Robotics Research
Haptics and Telemanipulation
In robotics, we design and build vision-based software for autonomous and semi-autonomous control of manipulators and mobile manipulators. This includes both visual servoing methods as well as learning based methods. Additionally, we develop haptic leader-follower teleoperation systems for human-in-the-loop telemanipulation. We focus on applications for unstructured environments.
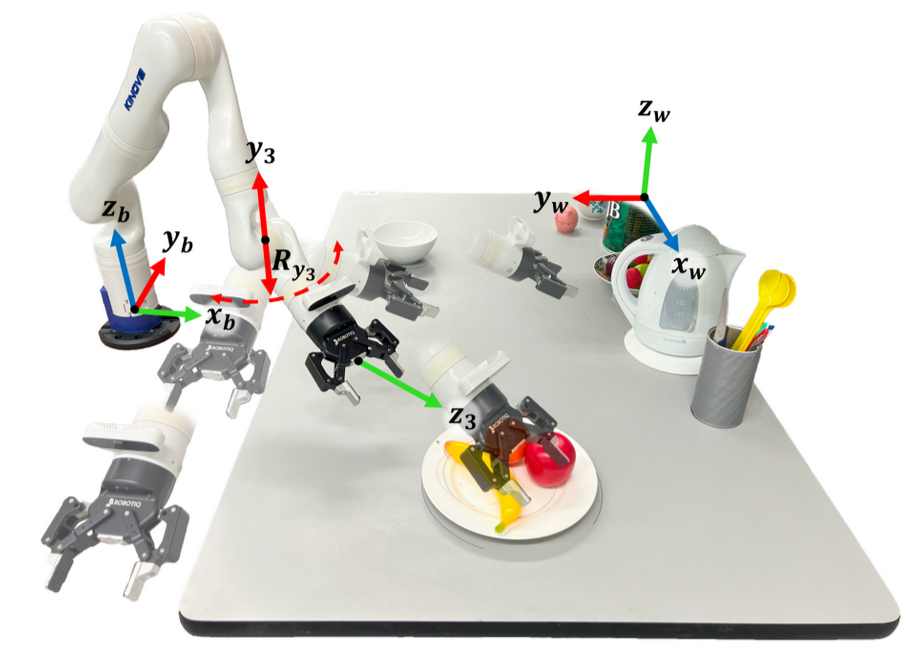
Point and Go: Intuitive Reference Frame Reallocation in
Mode
Switching for Assistive Robotics
People: Allie Wang; Chen Jiang; Michael Przystupa; Justin Valentine; Martin Jagersand
Operating high degree of freedom robots can be difficult for users of wheelchair mounted robotic manipulators. Mode switching in Cartesian space has several drawbacks such as unintuitive control reference frames, separate translation and orientation control, and limited movement capabilities that hinder performance. We propose Point and Go mode switching, which reallocates the Cartesian mode switching reference frames into a more intuitive action space comprised of new translation and rotation modes..
Thesis Link
Website Link

Back2Future-SIM: Creating Real-Time Interactable Immersive Virtual World For Robot Teleoperation
People: Sait Akturk; Justin Valentine; Martin Jagersand
In this thesis, our focus is on providing predictive haptic feedback and immersive visuals from the virtual replica of the remote scene in a physics simulator. Our system acts as a bridge between the operator and the follower robot, considering real-world constraints. We create a cyber-physical system using a real-time 3D surface mesh reconstruction algorithm and a digital twin of the Barrett WAM arm robot. The Gazebo physics simulator integrates the digital twin and an incremental surface mesh to create a real-time virtual replica of the remote scene. This virtual replica is used to provide haptic surface interaction feedback through collision detection from the physics simulator. Additionally, we address the operator's spatial awareness by using an immersive display for predictive visualization.
Thesis Link
Website Link

Mobile Manipulation and Telerobotics for Space Exploration
People: Azad Shademan; Alejandro Hernandez-Herdocia; David Lovi; Neil Birkbeckartin; Martin Jagersand
We have a partnership with the Canadian Space Agency (CSA) to develop semi-autonomous supervised control in space telerobotics using uncalibrated vision for traking and modeling...

Predictive display
People: Martin Jagersand; Adam Rachmielowski; Dana Cobzas; Azad Shademan; Neil Birkbeck
A predictive display system provided immediate visual feedback from robot site at the operator site...

A modular and flexible bimanipulation system for space-analogue
People: Alejandro Hernandez-Herdocia; Azad Shademan; Martin Jagersand
An advanced dual-arm mobile manipulator is prototyped for research in semi-autonomous teleoperation and supervisory control...

Communication mechanisms for cooperative human-robot manipulation tasks in unstructured environments
People: Camilo Perez Quintero; Martin Jagersand
Humans teach each other manipulation tasks through gestures and pointing. We develop an HRI where the robot interprets spatial gestures using comuter vision and carries out manipulation tasks...
Robot Learning

Learning Geometry from Vision for Robotic Manipulation
People: Jun Jin; Martin Jagersand
This thesis studies how to enable a real-world robot to efficiently learn a new task by watching human demonstration videos. Learning by watching provides a more human-intuitive task teaching interface than methods requiring coordinates programming, reward/cost design, kinesthetic teaching, or teleoperation. However, challenges regarding massive human demonstrations, tedious data annotations or heavy training of a robot controller impede its acceptance in real-world applications. To overcome these challenges, we introduce a geometric task structure to the problem solution.
Thesis Link
Website Link

Understanding Manipulation Contexts by Vision and Language for Robotic Vision
People: Chen Jiang; Martin Jagersand
In Activities of Daily Living (ADLs), humans perform thousands of arm and hand object manipulation tasks, such as picking, pouring and drinking a drink. In a pouring manipulation task, its manipulation context involves a sequence of actions executed over time over some specific objects. The study serves as a fundamental baseline to process robotic vision along with natural language understanding. In future, we aim to enhance this framework further for knowledge-guided assistive robotics.
Thesis Link

Actuation Subspace Prediction with Neural Householder Transforms
People: Kerrick Johnstonbaugh; Martin Jagersand
Choosing an appropriate action representation is an integral part of solving robotic manipulation problems. Published approaches include latent action models, which train context-conditioned neural networks to map low-dimensional latent actions to high-dimensional actuation commands. Such models can have a large number of parameters, and can be difficult to interpret from a user perspective. In this thesis, we propose that similar performance gains in robotics tasks can be achieved by restructuring the neural network to map observations to a basis for context-dependent linear actuation subspaces. This results in an action interface wherein a user's actions determine a linear combination of state-conditioned actuation basis vectors. We introduce the Neural Householder Transform (NHT) as a method for computing this basis.
Thesis Link
Visual Servoing

Robot Manipulation in Salient Vision through Referring Image Segmentation and Geometric Constraints
People: Chen Jiang; Allie Wang; Martin Jagersand
To solve robot manipulation tasks in real-world environments, CLIPU²Net is first employed to segment regions most relevant to the target specified by referring language. Geometric constraints are then applied to the segmented region, generating context-relevant motions for uncalibrated image-based visual servoing (UIBVS) control.
Paper Link

Image Based Path Following Control using Visual Servoing
People: Cole Dewis; Martin Jagersand
We develop a visual servoing based path following controller to allow robot arms to follow arbitrary paths or contours. This allows tasks to be specified as paths in image space.
Paper Link

Point to Line Visual Servoing
People: Mona Gridseth; Camilo Perez Quintero; Romeo Tatsambon; Martin Jagersand
Uncalibrated visual servoing is used to align the end-effector with the marked line on a patient...
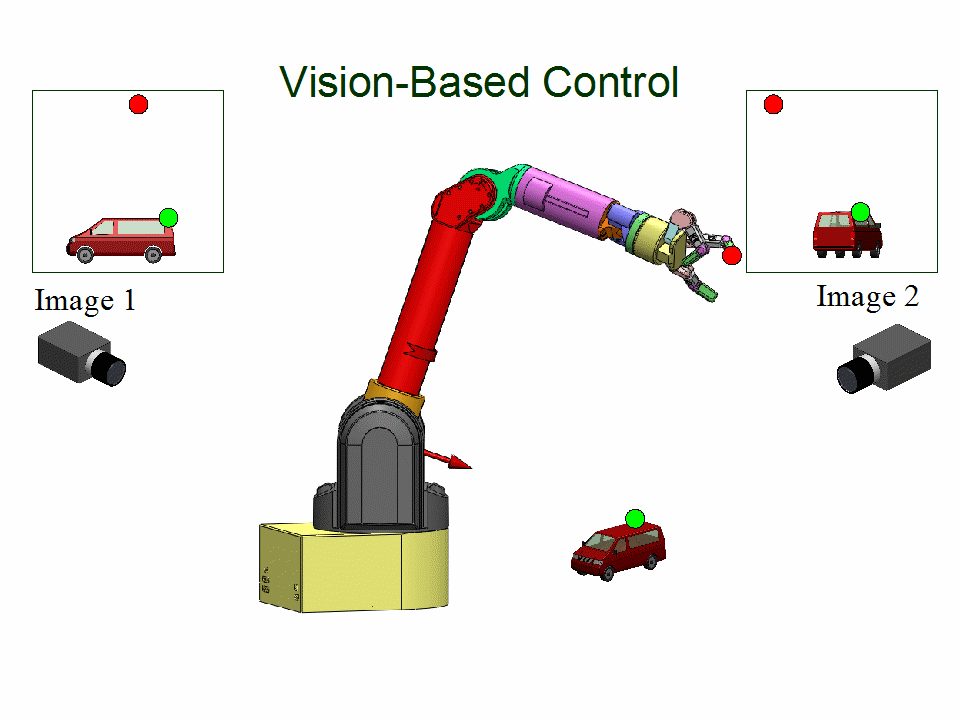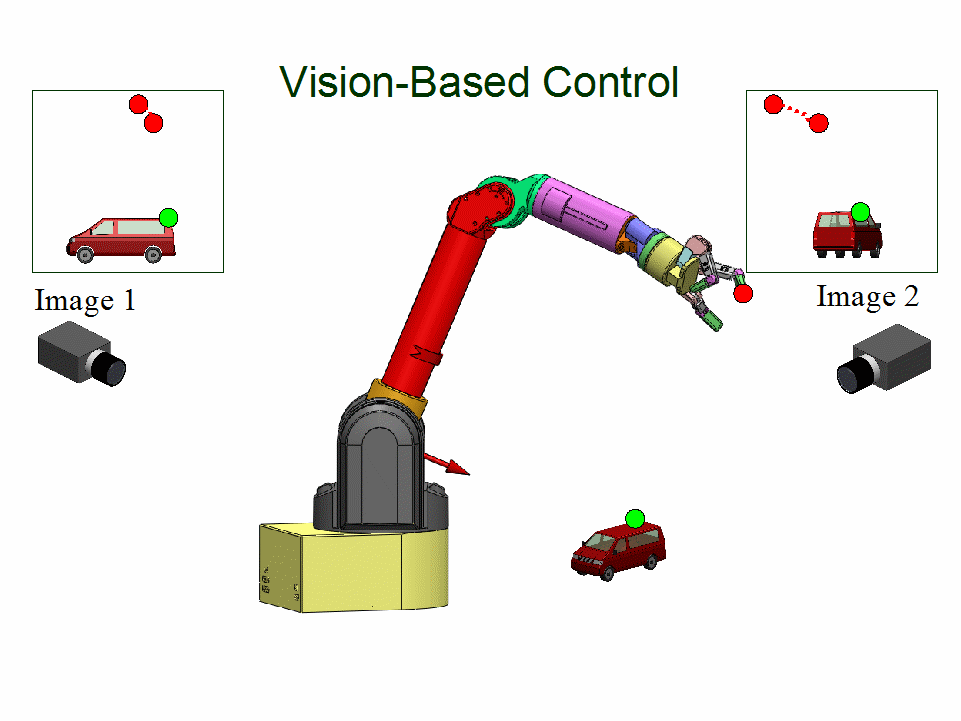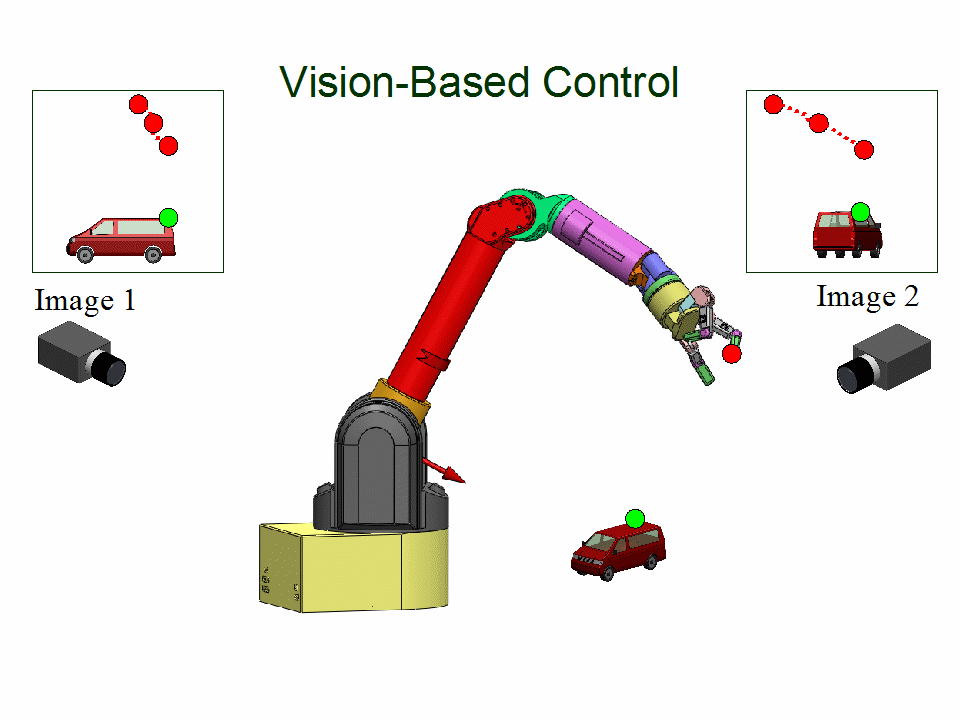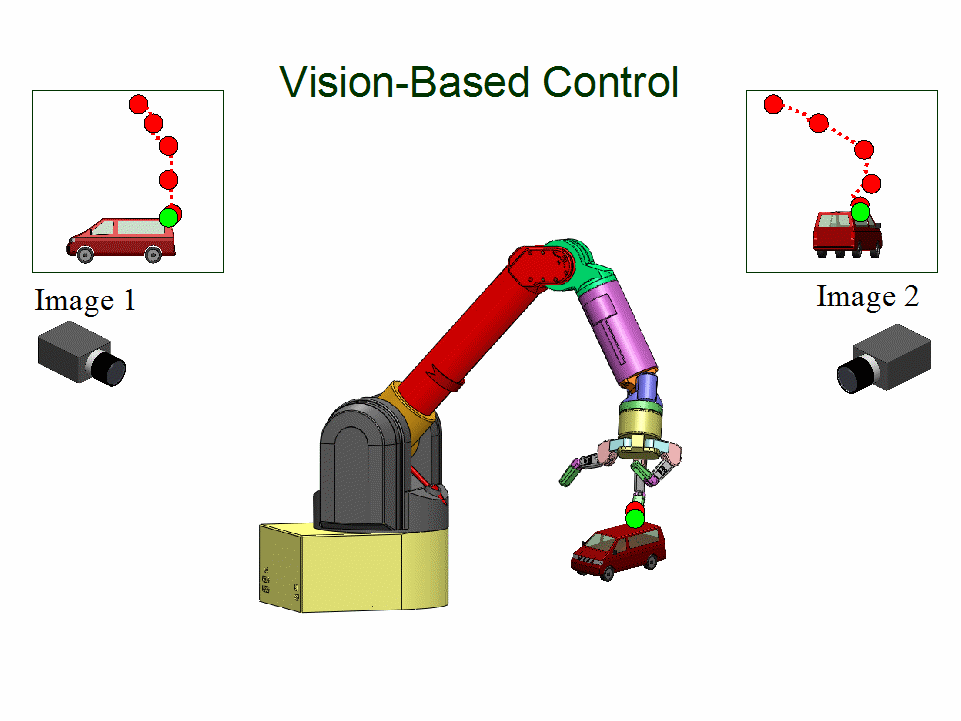
Uncalibrated Visual Servoing
People: Azad Shademan; Amir-massoud Farahmand; Martin Jagersand
Vision-based motion control of a WAM arm without using camera calibration or knowledge of camera/robot transformation for use in unstructured environments...

Visual Task Specification
People: Mona Gridseth
A visual interface where the user can specify tasks for the robot to complete using visual servoing...
Miscellaneous

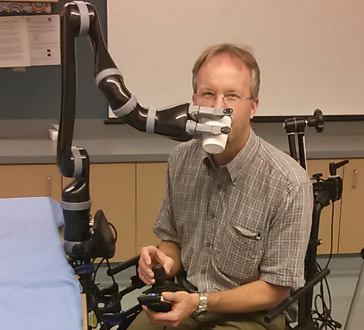
Advancing the Acceptance and Use of Wheelchair-mounted Robotic Manipulators
People: Laura Petrich; Martin Jagersand
Wheelchair-mounted robotic manipulators have the potential to help the elderly and individuals living with disabilities carry out their activities of daily living independently. While robotics researchers focus on assistive tasks from the perspective of various control schemes and motion types, health research tends to concentrate on clinical assessment and rehabilitation. This difference in perspective often leads to the design and evaluation of experimental tasks that are tailored to specific robotic capabilities rather than solving tasks that would support independent living. In addition, there are many studies in healthcare on which activities are relevant to functional independence, but little is known about how often these activities occur. Understanding which activities are frequently carried out during the day can help guide the development and prioritization of assistive robotic technology. By leveraging the strength of robotics (i.e., performing well on repeated tasks) these activities can be automated, significantly improving the quality of life for our target population.
Thesis Link
Activities of Daily Living: Frequency and Timing of Human Tasks
People: Laura Petrich; Martin Jagersand
Human assistive robotics can help the elderly and those with disabilities with Activities of Daily Living (ADL). Robotics researchers approach this bottom-up publishing on methods for control of different types of movements. Health research on the other hand focuses on hospital clinical assessment and rehabilitation using the International Classification of Functioning (ICF), leaving arguably important differences between each domain. In particular, little is known quantitatively on what ADLs humans perform in their ordinary environment - at home, work etc. This information can guide robotics development and prioritize what technology to deploy for in-home assistive robotics. This study targets several large lifelogging databases, where we compute (i) ADL task frequency from long-term low sampling frequency video and Internet of Things (IoT) sensor data, and (ii) short term arm and hand movement data from 30 fps video data of domestic tasks. Robotics and health care have different terms and taxonomies for representing tasks and motions. From the quantitative ADL task and ICF motion data we derive and discuss a robotics-relevant taxonomy in attempts to ameliorate these taxonomic differences.

Image-based maps for robot localization
People: Dana Cobzas; Hong Zhang; Martin Jagersand
Panoramic image mosaic augmented with depth information applied to robot localization...
Computer Vision Research

Line and Plane based Incremental Surface Reconstruction
People: Junaid Ahmad; Martin Jagersand
In this thesis, we try to take the natural step to also compute and verify 3D planes bottom-up from lines. Our system takes the real-time stream of new cameras and 3D points from a SLAM system and incrementally builds the 3D scene surface model. In previous work, 3D line segments were detected in relevant keyframes and were fed to the modeling algorithm for surface reconstruction. This method has an immediate drawback as some of the line segments generated in every keyframe are redundant and mark similar objects(shifted) creating clutter in the map. To avoid this issue, we track the 3D planes detected over keyframes for consistency and data association. Furthermore, the smoother and better-aligned model surfaces result in more photo-realistic rendering using keyframe texture images.

Incremental 3D Line Segment Extraction for Surface Reconstruction from Semi-dense SLAM
People: Shida He, Xuebin Qin, Zichen Zhang, and Martin Jagersand.
It is challenging to utilize the large scale point clouds of semi-dense SLAM for real-time surface reconstruction. In order to obtain meaningful surfaces and reduce the number of points used in surface reconstruction, we propose to simplify the point clouds generated by semi-dense SLAM using 3D line segments. Specifically, we present a novel incremental approach for real-time 3D line segments extraction. Our experimental results show that the 3D line segments generated by our method are highly accurate compared to other methods. We demonstrate that using the extracted 3D line segments greatly improves the quality of 3D surface compared to using the 3D points directly from SLAM systems.

VISUAL TRACKING VIA PERCEPTUAL GROUPING
People: Xuebin Qin, Shida He, Zichen Zhang, Masood Dehghan and Martin Jagersand.
Salient closed boundaries are typical common structures of many objects, such as object contours, cup and bin rims. These closed boundaries are hard to be tracked due to the lack of enough textures. In our project, we address the problem by prior shape constrained line segments and edge fragments perceptual grouping. Related techniques, such as edge fragments detection, tracking measure definition and graph based optimization are proposed to form real-time trackers.

A SEMI-AUTOMATIC BOUNDARY BASED IMAGE AND VIDEO ANNOTATION TOOL
People: Xuebin Qin, Shida He, Xiucheng Yang, Masood Dehghan, Qiming Qin and Martin Jagersand.
We developed a semi-automatic image and video annotation tool. This annotation tool replaces the polygons approximation of boundaries by one-pixel-width pixel chains which are smoother and more accurate. It defines objects as groups of one or multiple boundaries that means not only simple objects, which consist of one closed boundary, but also complex objects, such as objects with holes, objects split by occlusions, can be labeled and annotated easily.

MODNet: Moving Object Detection Network
People: Mennatullah Siam, Heba Mahgoub, Mohamed Zahran, Senthil Yogamani, Martin Jagersand, Ahmad El-Sallab
For autonomous driving, moving objects like vehicles and pedestrians are of critical importance as they primarily influence the maneuvering and braking of the car. Typically, they are detected by motion segmentation of dense optical flow augmented by a CNN based object detector for capturing semantics. In this paper, our aim is to jointly model motion and appearance cues in a single convolutional network. We propose a novel two-stream architecture for joint learning of object detection and motion segmentation. We designed three different flavors of our network to establish systematic comparison.

Convolutional Gated Recurrent Networks for Video Segmentation
People: Mennatullah Siam, Sepehr Valipour, Martin Jagersand, Nilanjan Ray
Semantic segmentation has recently witnessed major progress, where fully convolutional neural networks have shown to perform well. However, most of the previous work focused on improving single image segmentation. To our knowledge, no prior work has made use of temporal video information in a recurrent network. In this paper, we introduce a novel approach to implicitly utilize temporal data in videos for online semantic segmentation. The method relies on a fully convolutional network that is embedded into a gated recurrent architecture. This design receives a sequence of consecutive video frames and outputs the segmentation of the last frame.

Modular Tracking Framework (MTF), A Highly Efficient and Extensible Library for Registration based Visual Tracking
People: Abhineet Singh; Mennatullah Siam; Vincent Zhang; Martin Jagersand
MTF is a modular, extensible and highly efficient open source framework for registration based tracking targeted at robotics applications. It is implemented entirely in C++ and is designed from the ground up to easily integrate with systems that support any of several major vision and robotics libraries including OpenCV, ROS, ViSP and Eigen.
Tracking video benchmark database
People: Ankush Roy, Xi Zhang, Nina Wolleb, Camilo Perez Quintero, Martin Jagersand
Tracking human manipulation tasks is challenging. This benchmark contains 100 videos of ordinary human manipulation tasks (pouring cereal, drinking coffee, moving and reading rigid books and flexible letters etc). The videos are categorized w.r.t. task difficulty, speed of motion and light conditions...
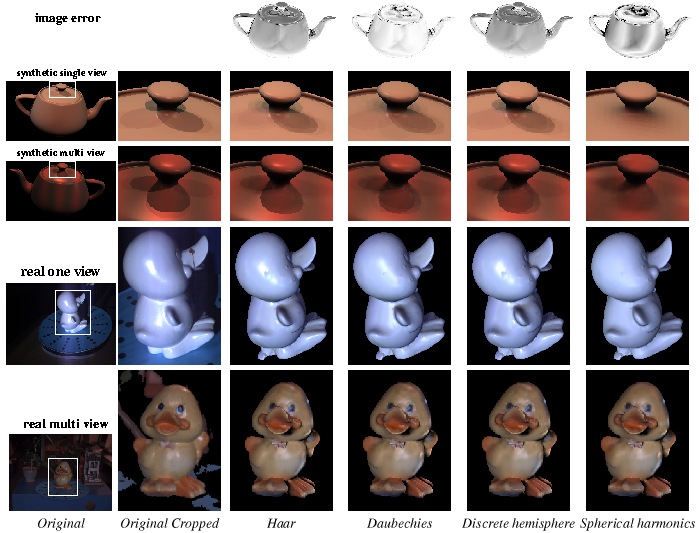
Wavelet light basis
People: Cameron Upright; Dana Cobzas; Martin Jagersand
A wavelet based light representation used for representing and capturing light...

Range intensity registration
People: Dana Cobzas; Hong Zhang; Martin Jagersand
A novel image-based algorithm for registering camera intesity data with range data from a laser rangefinder...

Modeling with dynamic texture
People: Martin Jagersand; Dana Cobzas; Keith Yerex; Neil Birkbeck
Inaccuracies in a coarse geometry obtained using structure-from-motion is compensated by an image-based correction - dynamic texture..
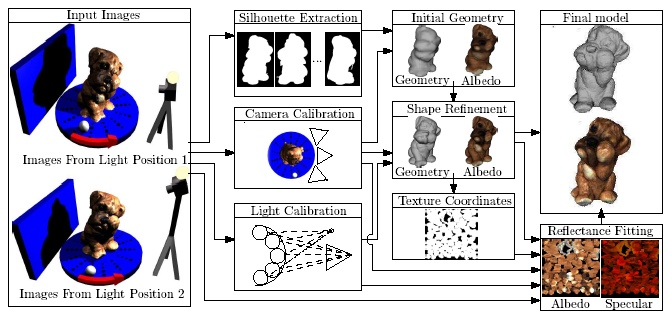
Variational Shape and Reflectance Estimation
People: Neil Birkbeck; Dana Cobzas; Peter Sturm; Martin Jagersand
Variational method implemented as a PDE-driven surface evolution interleaved with reflectance estimation...

3D SSD Tracking
People: Martin Jagersand; Dana Cobzas; Peter Sturm
3D SSD tracking A 3D consistent model is imposed to all tracked SSD regions, thus supporting direct tracking of camera position...
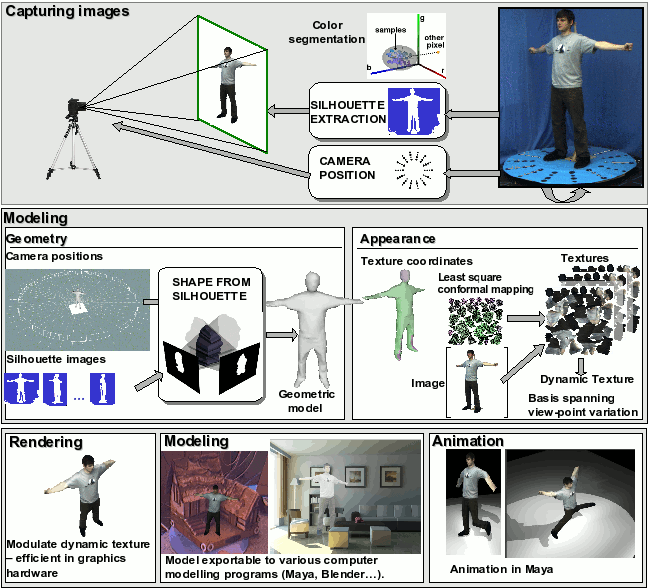
An image-based capture system
People: Keith Yerex; Neil Birkbeck; Cleo Espiritu; Cam Upright; Adam Rachmielowski; Dana Cobzas; Martin Jagersand
A quick and easy to use image-based modeling system for the acquisition of both 3D geometry and visual appearance of real world objects...

On-line tracking and modeling
People: Adam Rachmielowski; Neil Birkbeck; Martin Jagersand; Dana Cobzas
On-line 3D reconstruction from tracked feature points...
Medical Imaging Research
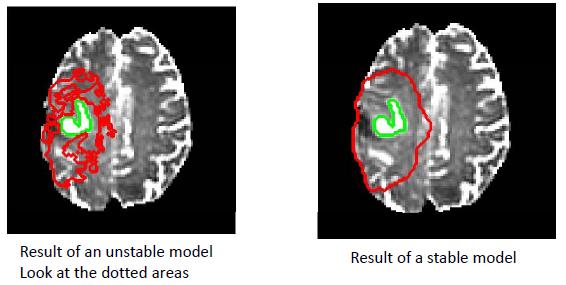
Tumor growth prediction
People: Dana Cobzas; Parisa Mosayebi; Albert Murtha; Martin Jagersand
Predicting tumor invasion margin using a geodesic distance defined on the Riemannian manifold of white fibers...
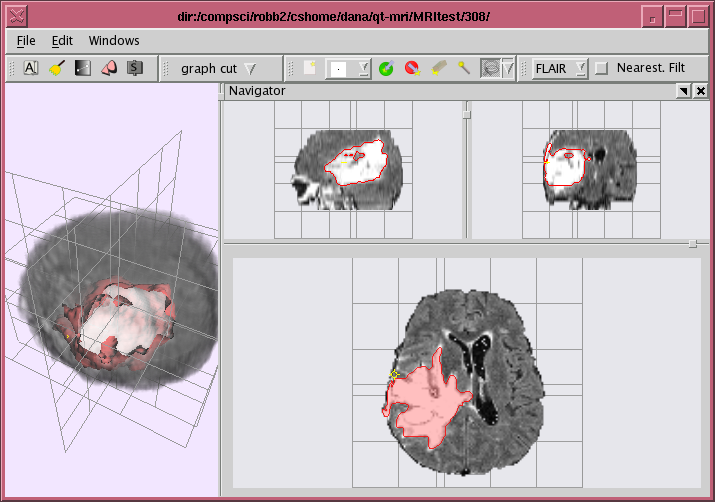
Semi-automatic segmentation software
People: Neil Birkbeck; Dana Cobzas; Martin Jagersand; Albert Murtha; Tibor Kesztyues, University of Applied Sciences Ulm, Germany
A semi-automatic software for medical image segmentation...See also project description on Neil's webpage

FEM for fast image registration
People: Karteek Popuri; Dana Cobzas; Martin Jagersand
A finite element implementation for the diffusion-based non-rigid registration algorithm...
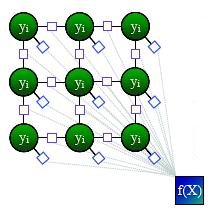
A continuous formulation of Conditional Random Fields (CRFs)
People: Dana Cobzas,University of Alberta ; Mark Schmidt,UBC
A variational formulation for a discriminative model in image segmentation...

Brain Tumor Segmentation
People: Dana Cobzas; Karteek Popuri; Neil Birkbeck; Mark Schmidt; Martin Jagersand; Albert Murtha
A variational segmentation method applied to a high-dimensional feature set computed from the MRI...
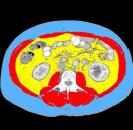
Muscle and fat segmentation
People: Howard Chung; Dana Cobzas; Jessica Lieffers, Agricultural, Food and Nutritional Science; Laura Birdsell, Oncology; Vickie Baracos, Oncology
Muscle and adipose tissue segmentation in CT images based on a deformable shape...
RW for deformable image registration
People: Dana Cobzas; Abhishek Sen
A discrete registration method based on the random walker algorithm...