|
Visual Task Specification In today's world robots work well in structured environments where they complete tasks autonomously and accurately. This is evident from industrial robotics. However, in unstructured and dynamic environments such as for instance homes, hospitals or areas affected by disasters, robots are still not able to be of much assistance. Commercially available autonomous robots can vacuume, but cannot handle more complex scenarios like clearing a cluttered table. Moreover, robotics research has focused on topics such as mechatronics design, control and autonomy, while fewer works pay attention to human-robot interfacing. This results in an increasing gap between expectations of robotics technology and its real world capabilities. In this work we present a human robot interface for semi-autonomous human-in-the-loop control, that aims to tackle some of the challenges for robotics in unstructured environments. The interface lets a user specify tasks for a robot to complete using uncalibrated visual servoing. Visual servoing is a technique that uses visual input to control a robot. In particular, uncalibrated visual servoing works well in unstructured environments since we don not rely on calibration or other modelling.
The picture of the tablet is taken from here, with our interface inserted |

|
As mentioned above we want the user to define high-level actions for the robot. To this end we work with visual tasks as presented in [1]. The authors informally characterize a positioning task as the objective of bringing a robot to a target in its workspace. We can describe the pose of the robot and the target using features or combinations of features that we observe through visual input. For example, a task can be to move the robot end-effector towards a bottle that it is supposed to pick up. We include the following tasks in our work: point-to-point, point-to-line, point-to-ellipse, line-to-line and parallel lines. Point-to-point, point-to-line and point-to-ellipse tasks align the robot end-effector with a point, line or ellipse in the workspace. Line-to-line tasks bring two lines together, whereas a parallel lines tasks make two lines parallel. As we learn from [1], these simple geometric constrains can be combined to create higher level tasks. We want to tackle the challenge of how this can be done in practice. We want to find out how the geometric constraints behave in a real system and what the best strategies are for using them to creating higher-level tasks.
[1] J. P. Hespanha, Z. Dodds, G. D. Hager, and A. S. Morse, “What tasks can be performed with an uncalibrated stereo vision system?” Int. J. Comput. Vision, vol. 35, no. 1, pp. 65–85, Nov. 1999. |


|
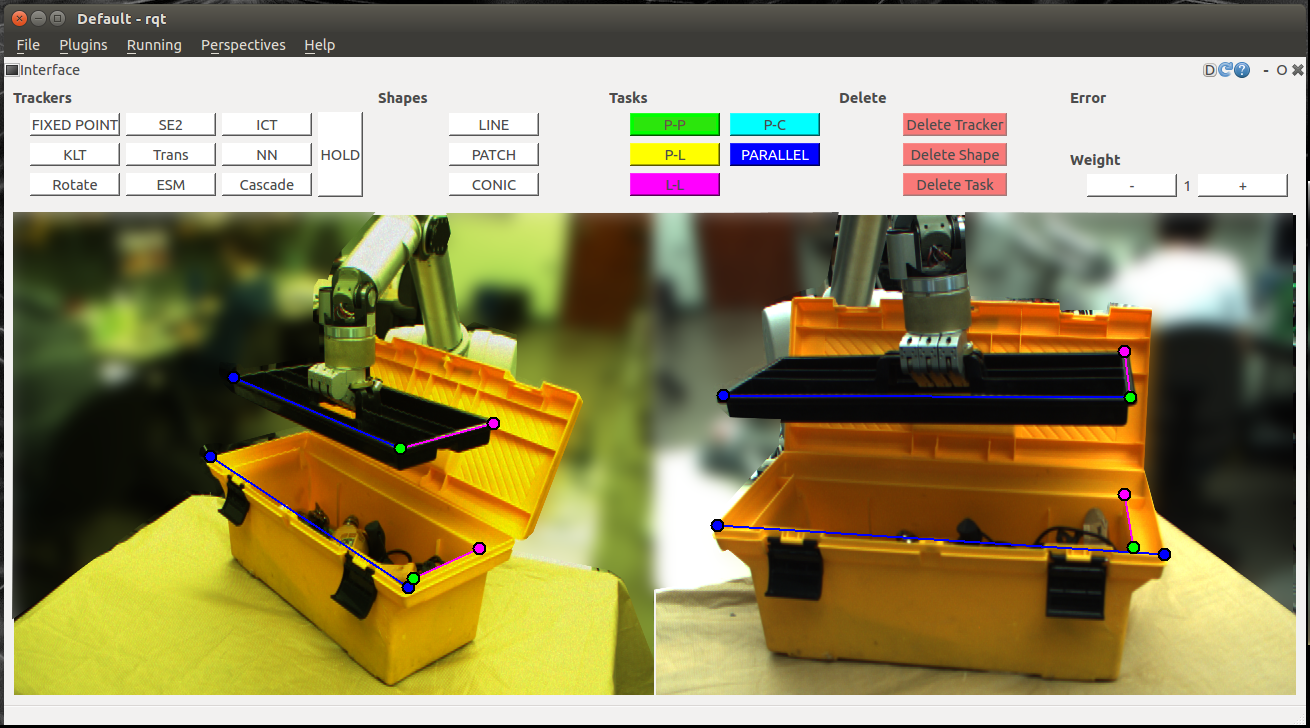
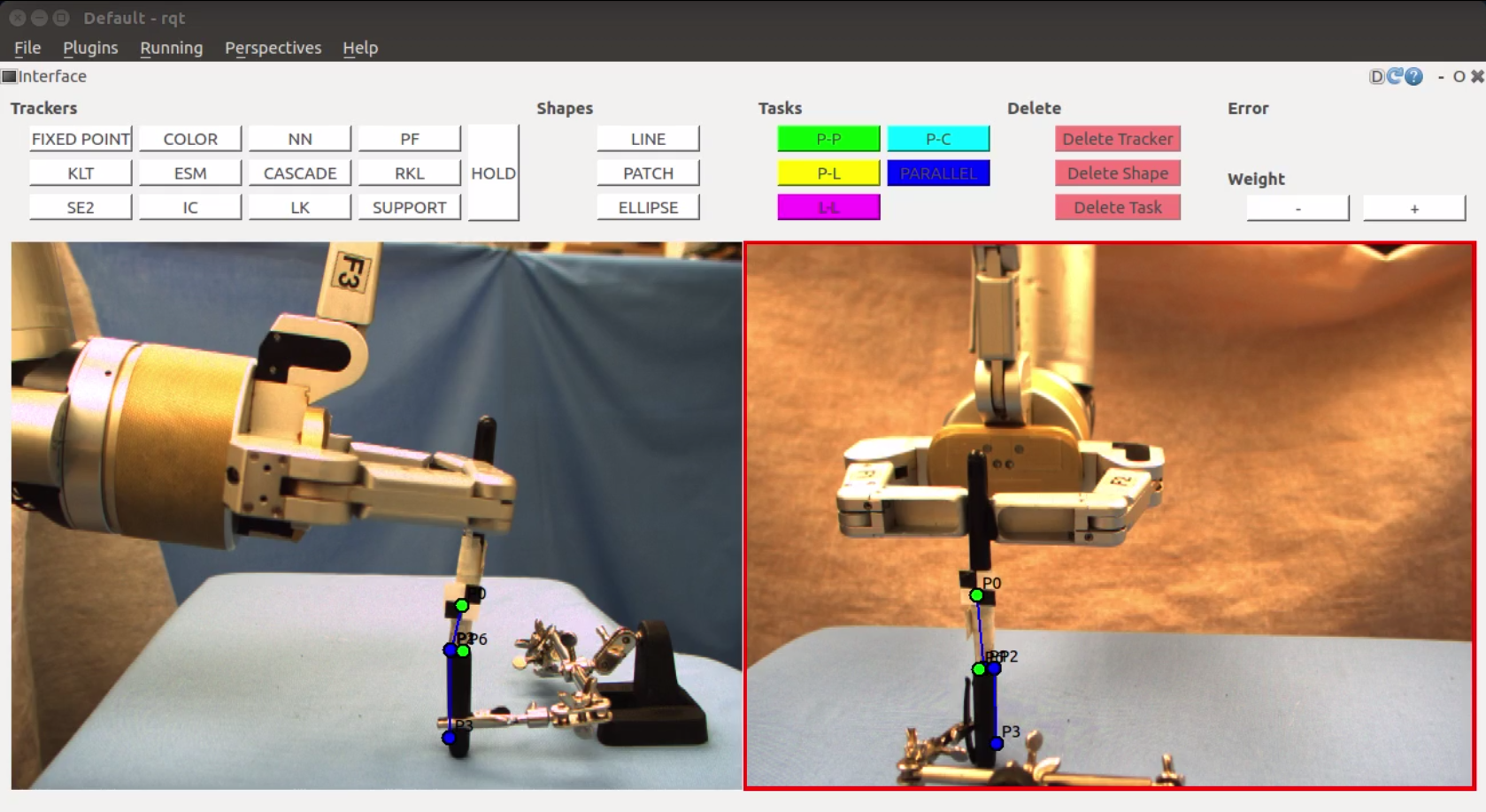
The main contribution of this thesis is twofold. We explore whether and how we can use combinations of simple geometric primitives for task specification as put forward by previous work. We also create a user interface that facilitates the interaction for task specification. The interface lets users visually specify high-level tasks for a robot to complete. Our work involves manipulation with a robot arm. However, this interface is general and can be included in any system that uses visual servoing to control robot movement. The interface facilitates our exploration of task specification in a real world system. A picture of the visual interface can be seen below. The example task is to place the black tray in the toolbox. The interface includes several trackers. The user can set points and create shapes. In the task below the user has combined a parallel lines task in blue, with a line-to-line task in purple and a green point-to-point task.
|
|
|

|
|