Hong Zhang, PhD
Professor
Department of Computing Science
University of Alberta, Edmonton, Alberta, Canada
VISUAL ROBOT NAVIGTATION
We are interested in developing mobile robots capable of navigating autonomously using vision, e.g., a monocular camera. This problem has been defined in the research community as visual SLAM (simultaneous localization and mapping) in which our work has been focused in three areas: visual loop closure detection, visual homing and illumination-invariant scene description.
Loop Closure Detection
 The ability is to determine if a robot has returned to a previously
visited location is critical in order for the robot to build a map of
an environment correctly. This is the problem of loop closure detection,
also known as place recognition or robot relocalization in the literature.
We have developed efficient and robust algorithms that can detect loop
closures in city-size maps. Our main approach
is to use compact and discriminating whole-image descriptors.
The ability is to determine if a robot has returned to a previously
visited location is critical in order for the robot to build a map of
an environment correctly. This is the problem of loop closure detection,
also known as place recognition or robot relocalization in the literature.
We have developed efficient and robust algorithms that can detect loop
closures in city-size maps. Our main approach
is to use compact and discriminating whole-image descriptors.
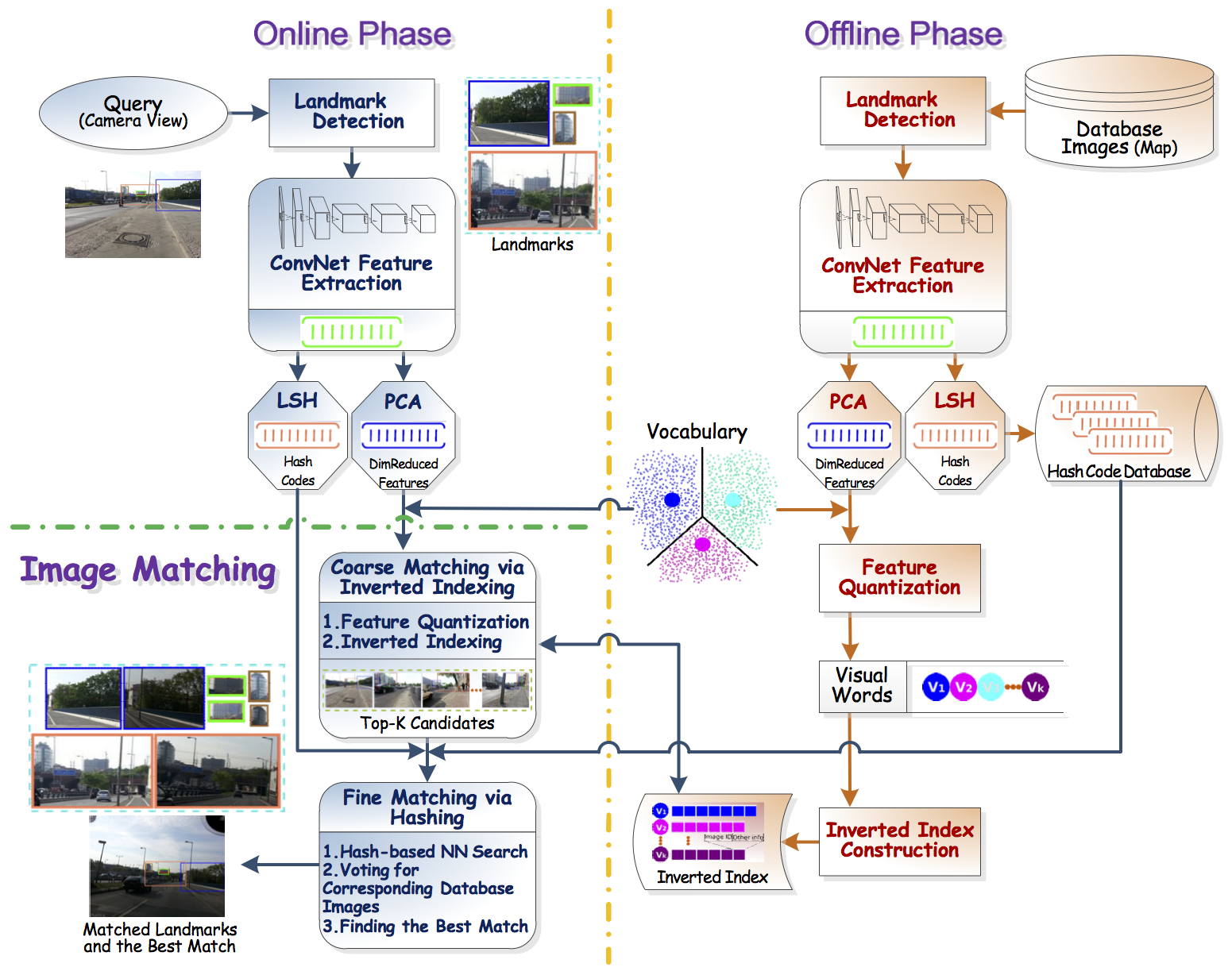
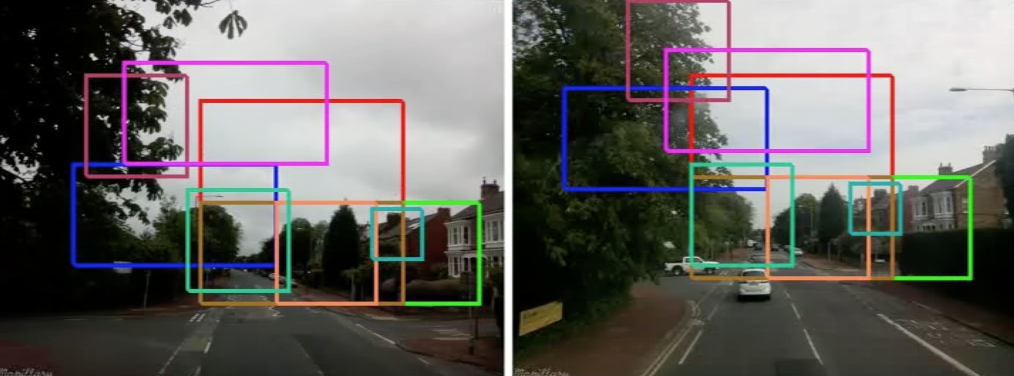
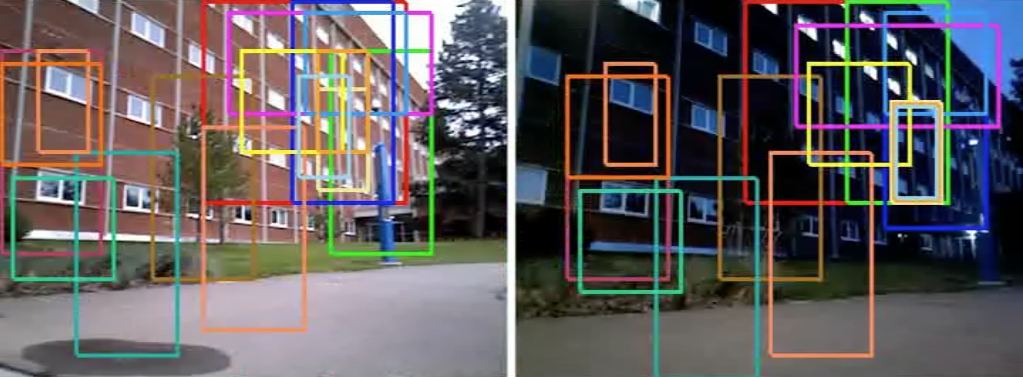
One of the more recent approach we have explored in solving loop closure is based on deep convolutional neural networks. In this case, place recognition is solved using a landmark-based method in which objects or landmarks in a scene are detected first, and expressed in terms of the deep CNN feature descriptions. Recognition is conducted by computing similarity between the current view and the map views, efficiently using a modified coarse-to-fine bag-of-words (BoW) algorithm that incorporates hamming embedding for added discriminating power. See matched image pairs in two different datasets below for examples.
Pose-Graph Visual SLAM
 With the loop closure information, one can construct robot maps as using
state-of-the-art pose graph SLAM algorithms such as g2o.
In this case, we represent an environment topologically in the form of a
graph where each node corresponds to a robot pose, and an edge can be
computed between nodes using either odometric information due to robot
motion or transformation between robot poses in the case of loop closures.
We can reconstruct a map for the environment with global optimization of the
pairwise constraints between robot poses. Our current effort focuses on
active pose-graph SLAM in which ground detection and next-goal selection
are included in the overall navigation system so that a mobile robot
can explore an environment and construction its representation entirely
autonomously. The research is being conducted in both indoor and outdoor
environments under variable environmental conditions.
With the loop closure information, one can construct robot maps as using
state-of-the-art pose graph SLAM algorithms such as g2o.
In this case, we represent an environment topologically in the form of a
graph where each node corresponds to a robot pose, and an edge can be
computed between nodes using either odometric information due to robot
motion or transformation between robot poses in the case of loop closures.
We can reconstruct a map for the environment with global optimization of the
pairwise constraints between robot poses. Our current effort focuses on
active pose-graph SLAM in which ground detection and next-goal selection
are included in the overall navigation system so that a mobile robot
can explore an environment and construction its representation entirely
autonomously. The research is being conducted in both indoor and outdoor
environments under variable environmental conditions.
Visual Navigation
 With a feature-based map of an environment, an autonomous robot should be
able to navigate within that environment one location to another, by matching
its current view of the camera with the views stored in the robot map.
This is the general problem of visual homing, and a special case, defined
as visual teach and repeat (VTaR), is illustrated in the video to the right
where ORB-SLAM was used to construct a map of the environment and repeating
the teaching route is performed by localizing the robot with respect to
and correcting deviation from the route. Specifically, in the teaching
phase, a map in terms of the 3D point features is constructed by detecting
and triangulating 2D ORB features using the ORB-SLAM algorithm. In the
repeat phase, the robot moves through the same sequence of keyframes as in
the teach phase, and matches the observed ORB features with those in the
keyframe in order to determine the pose of the robot with respect to the
keyframe and the global map. A simple PD controller is then used to
steer the robot in order to track the route of the teaching phase.
With a feature-based map of an environment, an autonomous robot should be
able to navigate within that environment one location to another, by matching
its current view of the camera with the views stored in the robot map.
This is the general problem of visual homing, and a special case, defined
as visual teach and repeat (VTaR), is illustrated in the video to the right
where ORB-SLAM was used to construct a map of the environment and repeating
the teaching route is performed by localizing the robot with respect to
and correcting deviation from the route. Specifically, in the teaching
phase, a map in terms of the 3D point features is constructed by detecting
and triangulating 2D ORB features using the ORB-SLAM algorithm. In the
repeat phase, the robot moves through the same sequence of keyframes as in
the teach phase, and matches the observed ORB features with those in the
keyframe in order to determine the pose of the robot with respect to the
keyframe and the global map. A simple PD controller is then used to
steer the robot in order to track the route of the teaching phase.
Illumination-Invariant Scene Description
 Visual recognition of a scene is sensitive to lighting or illumination as
well as to other types of dynamic changes (e.g., moving objects, weather and
season). Our research addresses the problem of illumination-invariant
scene representation in the place recognition application. We employ two
approaches primarily, one that builds an invariant representation of a visual
scene by extracting the reflectance component of the observation using
low-rank optimization, and the
other that uses deep neural networks (e.g., convolutional neural networks or
CNN) to extract a high-level and abstract representations of the scene
for its recognition (see right). Another application of our research is
moving object detection in wildlife monitoring in
time-lapse videos.
Visual recognition of a scene is sensitive to lighting or illumination as
well as to other types of dynamic changes (e.g., moving objects, weather and
season). Our research addresses the problem of illumination-invariant
scene representation in the place recognition application. We employ two
approaches primarily, one that builds an invariant representation of a visual
scene by extracting the reflectance component of the observation using
low-rank optimization, and the
other that uses deep neural networks (e.g., convolutional neural networks or
CNN) to extract a high-level and abstract representations of the scene
for its recognition (see right). Another application of our research is
moving object detection in wildlife monitoring in
time-lapse videos.

IMAGE SEGMENTATION
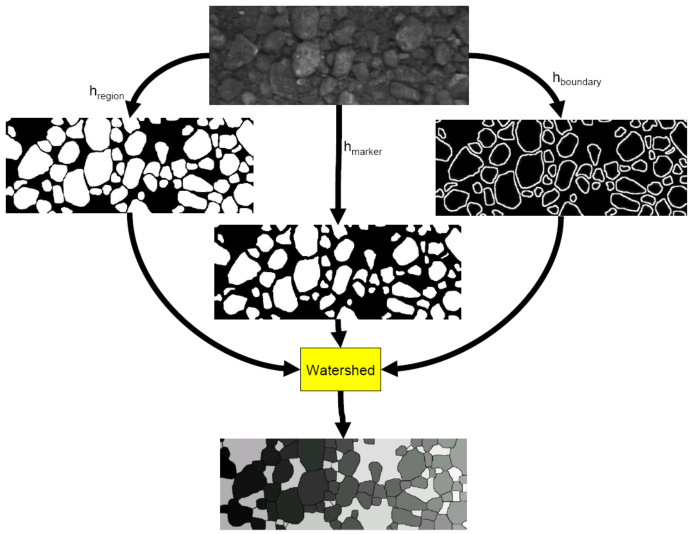 Our research in image segmentation is driven largely by the need of Alberta's oi
l sand mining industry to measure ore size while the oil sand ore is crushed, co
nveyed and screened. One novel image segmentation algorithm we have developed f
ormulates image segmentation as a problem of pixel classification, which is then
solved by supervised machine learning. We also extensively exploit the known s
hape of the objects for their segmentation. To evaluate our segmentation algori
thm objectively, we have designed a performance metric for images of multiple ob
jects that fairly penalizes over- and under-segmentation. Our segmentation algo
rithms have been successfully deployed in practical applications.
Our research in image segmentation is driven largely by the need of Alberta's oi
l sand mining industry to measure ore size while the oil sand ore is crushed, co
nveyed and screened. One novel image segmentation algorithm we have developed f
ormulates image segmentation as a problem of pixel classification, which is then
solved by supervised machine learning. We also extensively exploit the known s
hape of the objects for their segmentation. To evaluate our segmentation algori
thm objectively, we have designed a performance metric for images of multiple ob
jects that fairly penalizes over- and under-segmentation. Our segmentation algo
rithms have been successfully deployed in practical applications.
See our publications in ICIP, TIP, IVC and
PRL for details.
COLLECTIVE ROBOTICS
 In collective robotics, we are interested in understanding the underlying pri
nciples that enable multiple robots to work cooperatively in accomplishing joint
tasks. Our approaches are biologically inspired in which behaviors of social in
sects are mapped to local rules of interaction among the robots. We have investi
gated general methodologies with which one can design collective robot systems,
synthesize the rules of interaction, and prove about their properties. In recent
years, we have focused on the tasks of collective construction and collective d
ecision making , to ground our research ideas. Shown below are snapshots of col
lective construction via the bull dozing behavior (left), collective cons
truction using combinatorial optimization (middle), and highlights of a Robocup
match by Team Canuck based in Computing Science in 2000-2005 (right).
In collective robotics, we are interested in understanding the underlying pri
nciples that enable multiple robots to work cooperatively in accomplishing joint
tasks. Our approaches are biologically inspired in which behaviors of social in
sects are mapped to local rules of interaction among the robots. We have investi
gated general methodologies with which one can design collective robot systems,
synthesize the rules of interaction, and prove about their properties. In recent
years, we have focused on the tasks of collective construction and collective d
ecision making , to ground our research ideas. Shown below are snapshots of col
lective construction via the bull dozing behavior (left), collective cons
truction using combinatorial optimization (middle), and highlights of a Robocup
match by Team Canuck based in Computing Science in 2000-2005 (right).
See our
publications in IJRR, TMech, AB, SI and ROBIO for details.
