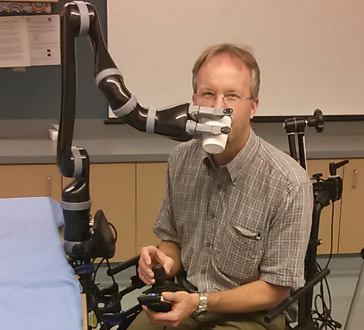
Haptic
Teleoperation demo at RiseX 2025!
Haptic
Teleoperation demo at RiseX 2025!
 Point and Go: Intuitive Reference Frame Reallocation in Mode
Point and Go: Intuitive Reference Frame Reallocation in Mode
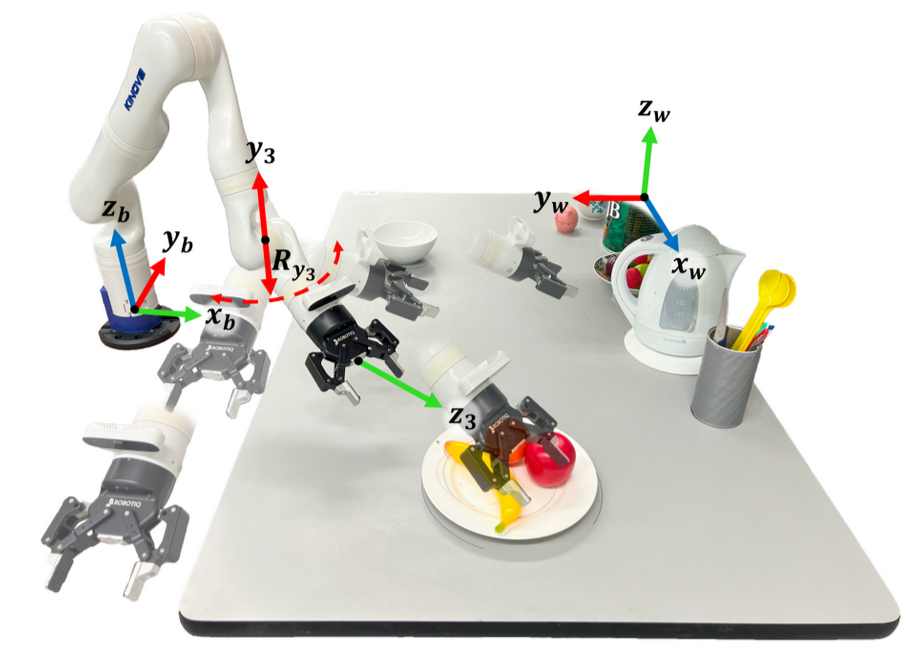
Switching for Assistive Robotics Robot Manipulation through Image Segmentation and Geometric Constraints
Robot Manipulation through Image Segmentation and Geometric Constraints
 Back2Future-SIM: Interactable
Immersive Virtual World For Teleoperation
Back2Future-SIM: Interactable
Immersive Virtual World For Teleoperation Visual Servoing Based Path
Following Controller
Visual Servoing Based Path
Following Controller Actuation Subspace
Prediction with Neural Householder Transforms
Actuation Subspace
Prediction with Neural Householder Transforms Understanding Manipulation Contexts
by Vision and Language for Robotic Vision
Understanding Manipulation Contexts
by Vision and Language for Robotic Vision Learning Geometry
from Vision for Robotic Manipulation
Learning Geometry
from Vision for Robotic Manipulation
 1
1 2
2 3
3 4
4 5
5 6
6 7
7 8
8wow slider by
WOWSlider.com v8.8