AIxploratorium
|
||
|
|
||
Random SplitsThe tree produced probably looked something like this...
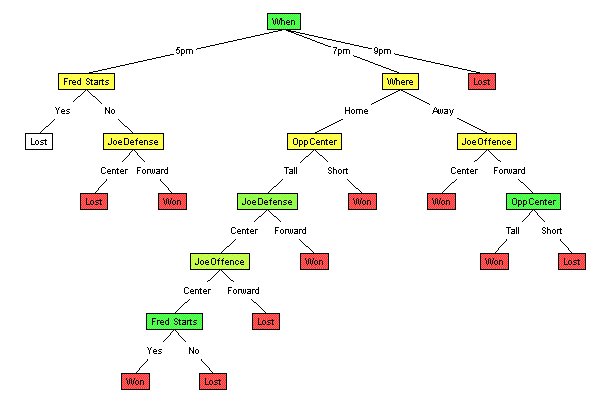
this one has a total of 22 nodes, including 10 internal (splitting) nodes. Why not split Randomly?As you saw, the tree can grow huge when the splits are done randomly. These trees are hard to understand, and can be difficult to store. And as you may have noticed, different runs will produce different answers. (Wanna try it? Choose "Initialize" and then "Run" from the "Algorithm" menu) It is known that larger trees are typically less accurate than smaller trees. (See Occam Algorithms and No Free Lunch papers.) How then can we produce small trees? Before we provide one approach, we encourage you to try it on your own. You can use the applet to do this: The general "Decision Tree learning algorithm" (LearnDT) grows a decision tree one node at a time. At each time, it considers the set of records that reach a specific location, based on the "path" to this point --- which corresponds to a sequence of "attribute = value" assignments (eg, [FredStarts=No, JoeOffence=Forward]). It then considers each of the remaining attributes, as the possible label for this node --- here, JoeDefends, OppC, ... (But not any of the attributes already encountered on the path to here. Why?) Your turn!
The applet
allows the user to grow a tree:
If you left-click at the end of any such path (shown as a
blue triangle Your goal is to find a small tree that is "consistent" with the records --- that is, which correctly determines which games were Won, vs Lost? Can you find a consistent tree with under 10 internal nodes? ... under 8 internal nodes? ... under 5? |
|||
|
|
 ),
you get the option of selecting which attribute to split on.
(This is true at the beginning as well, when bottom "decision tree" screen
is blank.)
Of course, make sure you're using the "Basketball" dataset.
),
you get the option of selecting which attribute to split on.
(This is true at the beginning as well, when bottom "decision tree" screen
is blank.)
Of course, make sure you're using the "Basketball" dataset.