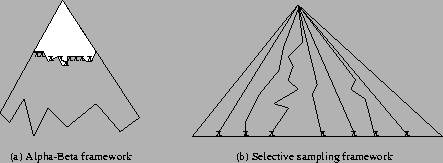
The alpha-beta algorithm [20] has proven to be an effective tool for the design of two-player, zero-sum, deterministic games with perfect information. Its origins go back to the beginning of the 1960's. Since that time the basic structure has not changed much, although there have been numerous algorithmic enhancements to improve the search efficiency. The selective-sampling simulation technique is becoming an effective tool for the design of zero-sum games with imperfect information or conditions of uncertainty (see Chapter 6). Table 5.1 shows a comparison between the usual characteristics of both approaches.
In poker the heuristic evaluation at the interior nodes of the simulation is done to determine the appropriate opponents' actions and Loki-2's actions. The leaf node evaluations are the amount of money won or lost, since the simulation done for each sample goes to the end of the game. In deterministic games, the heuristic evaluation is done to estimate the expected utility of the game from a given position (i.e. the value of the subtree beyond the maximum search depth of the program). A simple leaf node evaluation for some perfect information games can be the material balance. Figure 5.5 illustrates where the evaluation occurs in the search and simulation approaches and the game space explored by them.
The alpha-beta algorithm gathers confidence in its move choice by searching deeper along each line. The deeper the search, the greater the confidence in the move choice, although diminishing returns quickly takes over. The alpha-beta algorithm is designed to identify a ``best'' move, and not differentiate between other moves. Hence, the selection of the best move may be brittle, in that the misevaluation of a single node can propagate to the root of the search and alter the best move choice. Similarly, selective sampling simulation increases its confidence in the answer as more nodes are evaluated. However, diminishing returns takes over after a statistically significant number of trials have been performed. Selective sampling simulation can be compared to selective search or forward pruning techniques in alpha-beta algorithms. These techniques discard some branches to reduce the size of tree; however, their major drawback is the possibility that the lookahead process will ignore a key move at a shallow level in the game tree [18]. To be reliable, forward pruning methods need to reason about the tree traversal to deduce which ``future branches'' can be excluded. On the other side, selective sampling simulation uses available information about the game and the opponents to explore the most likely ``current branches'' of the game tree.