COMPUTER VISION PROJECTS
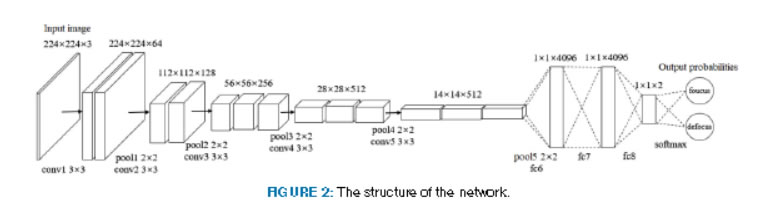 |
Focus Measure for Synthetic Aperture Imaging using a Deep Convolutional Network Synthetic aperture imaging is a technique that mimics a camera with a large virtual convex Reference Z. Pei, L. Huang, Y. Zhang, M. Ma and Y.I. Peng, and Y.H. Yang, "Focus measure for synthetic aperture imaging using a deep convolutional network," IEEE Access, to appear. |
||||
 |
Synthetic Aperture Photography Using A Moving Camera-IMU System Occlusion poses a critical challenge to computer vision for a long time. Recently, the technique of synthetic aperture photography using a camera array has been regarded as a promising way to address this issue. Unfortunately, the expensive cost of a standard camera array system with the required calibration procedure still limits the widespread application of this technique. To make synthetic aperture photography practical, in this project, we propose a novel approach based on a mobile camera-IMU system moving on a planar surface. The contributions of our work include: 1) with geometric property assumptions, we mathematically prove that the transformation matrices for synthetic aperture image generation can be factorized into an infinite homography and a shift, 2) the IMU data are utilized to estimate the homography by selecting the plane at infinity as the reference plane, which is scene independent and does not rquire any calibration, 3) compared to the conventional camera array based approaches, the proposed method effectively improves the solution for synthetic aperture capturing and generation using a more flexible, convenient, and inexpensive system. Extensive experimental results with qualitative and quantitative evaluations demonstrate the see-through-occlusion performance with satisfactory accuracy of the proposed method. Reference X. Zhang, Y. Zhang, T. Yang, and Y.H. Yang, "Synthetic Aperture Photography using a Moving Camera-IMU System," Pattern Recognition, online preprint version, July 8, 2016. |
||||
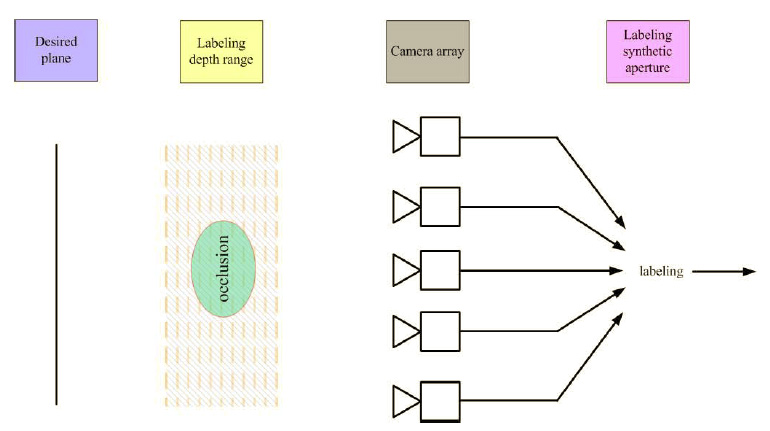 |
Synthetic Aperture Imaging Using Pixel Labeling via Energy Minimization Unlike the conventional synthetic aperture imaging method, which averages images from all the camera views, we reformulate the problem as a labeling problem. In particular, we use the energy minimization method to label each pixel in each camera view to decide whether or not it belongs to an occluder. After that, the focusing at the desired depth is by averaging pixels that are not labeled as occluder. The experimental results show that the proposed method outperforms the traditional synthetic aperture imaging method as well as its improved versions, which simply dim and blur occluders in the resulting image. To the best of our knowledge, our proposed method is the first one for improving the results of synthetic aperture image without using a training set from the input sequence. As well, it is the first method that makes no assumptions on whether or not the objects in the scenes are static. Reference Z. Pei, Y. Zhang, X. Chen and Y.H. Yang, "Synthetic Aperture Imaging using Pixel Labeling via Energy Minimization," Pattern Recognition, Vol. 46, Issue 1, 2013, pp. 174-187. (http://dx.doi.org/10.1016/j.patcog.2012.06.014) |
||||
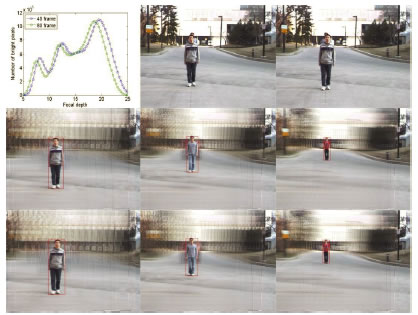 |
Synthetic Aperture Imaging in Complex Scene In this project, we have developed a novel multi-object detection method using multiple cameras. Unlike conventional multi-camera object detection methods, our method detects multiple objects using a linear camera array. The array can stream different views of the environment and can be easily reconfigured for a scene compared with the overhead surround configuration. Using the proposed method, the synthesized results can provide not only views of significantly occluded objects but also the ability of focusing on the target while blurring objects that are not of interest. Our method does not need to reconstruct the 3D structure of the scene, can accommodate dynamic background, is able to detect objects at any depth by using a new synthetic aperture imaging method based on a simple shift transformation, and can see through occluders. The experimental results show that the proposed method has a good performance and can synthesize objects located within any designated depth interval with much better clarity than that using an existing method. To our best knowledge, it is the first time that such a method using synthetic aperture imaging has been proposed and developed for multi-object detection in a complex scene with significant occlusion at different depths. Reference Z. Pei, Y. Zhang, T.Yang, X. Zhang, and Y.H. Yang, "A Novel Multi-Object Detection Method in Complex Scene Using Synthetic Aperture Imaging," Pattern Recognition, Vol. 45, Issue 4, 2012, pp. 1637-1658. (http://dx.doi.org/10.1016/j.patcog.2011.10.003) |
||||
A Cluster-Based Camera Array System In this project, we are devloping a cluster-based system for camera array application. The idea is to develop a framework such that the cluster will be as easy to use as a single machine. Our current cluster consists of 8 nodes, each of which consists of two dual-core Opteron CPUs, 2 Nvidia 8800 GTX GPUs, and one 10Gb network interface card. The nodes are connected by 10Gb high speed Ethernet. Each node controls two firewire cameras. References C. Lei, X. Chen, and Y.H. Yang, "A New Multiview Spacetime-Consistent Depth Recovery Framework for Free Viewpoint Video Rendering, International Conference on Computer Vision, Kyoto, Japan, September 27-October 2, 2009. (http://dx.doi.org/10.1109/ICCV.2009.5459357) C. Lei and Y.H. Yang, "Efficient geometric, photometric, and temporal calibration of an array of unsynchronized video cameras," Sixth Canadian Conference on Computer and Robot Vision, Kelowna, BC, May 25-27, 2009. (http://dx.doi.org/10.1109/CRV.2009.17) C. Lei and Y.H. Yang, "Design and implementation of a cluster-based smart camera array application framework," Second ACM/IEEE International Conference on Distributed Smart Cameras, Stanford, California, September 7-11, 2008. Poster Presentation.(http://dx.doi.org/10.1109/ICDSC.2008.4635708)
|
|||||
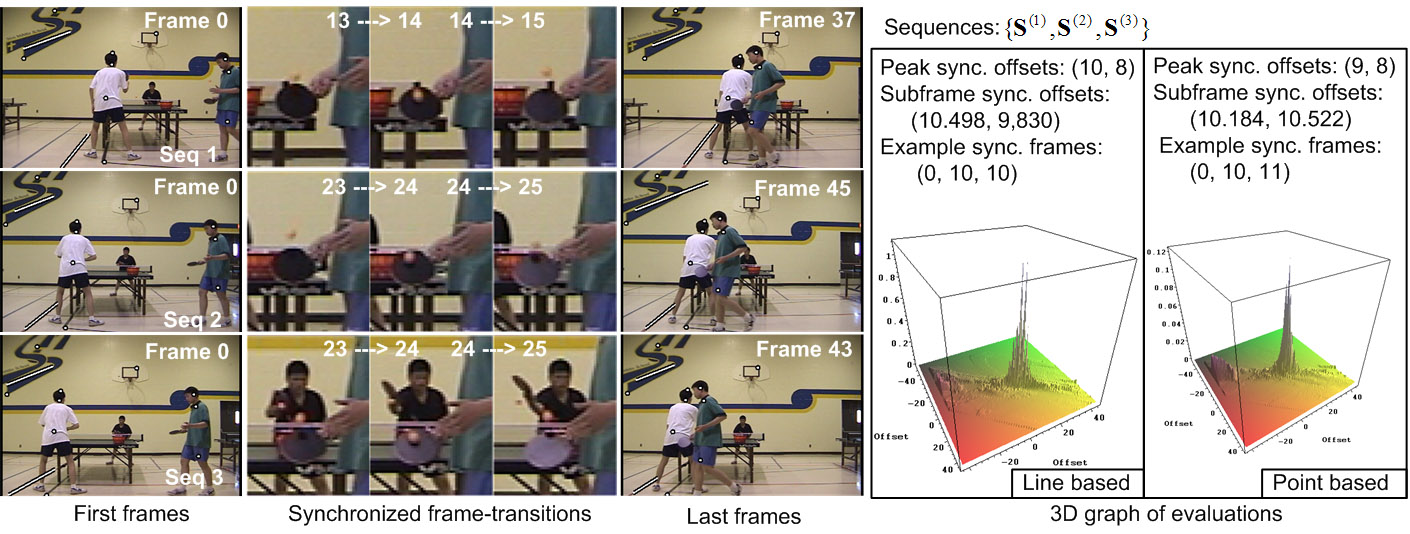
Tri-Focal Tensor based Multiple Video Synchronization with Sub-Frame Optimization In this project, we develop a novel method for synchronizing multiple (more than 2) un-calibrated video sequences recording the same event by free-moving full-perspective cameras. Unlike previous synchronization methods, our method takes advantage of tri-view geometry constraints instead of the commonly used two-view one for their better performance in measuring geometric alignment when video frames are synchronized. In particular, the tri-ocular geometric constraint of point/line features, which is evaluated by tri-focal transfer, is enforced when building the timeline maps for sequences to be synchronized. A hierarchical approach is used to reduce the computational complexity. To achieve sub-frame synchronization accuracy, the Levenberg-Marquardt method based optimization is performed. The experimental results on several synthetic and real video datasets demonstrate the effectiveness and robustness of our method over previous methods in synchronizing full-perspective videos.
Reference C. Lei and Y.H. Yang, “Tri-Focal Tensor based Multiple Video Synchronization with Sub-Frame Optimization,” IEEE Trans. on Image Processing, Vol. 15, 2006, pp. 2473-2480. (http://dx.doi.org/10.1109/TIP.2006.877438) Raw video sequences (Ping pong and car) (30MB)
|
|||||
Real-time Backward Disparity-based Rendering for Dynamic Scenes using Programmable Graphics Hardware
This project develops a backward disparity-based rendering algorithm, which runs at real-time speed on programmable graphics Refererence M. Gong, J. Selzer, C. Lei, and Y.H. Yang "Real-time Backward Disparity-based Rendering for Dynamic Scenes using Programmable Graphics Hardware," Graphics Interface, Montreal, 2007, pp. 241-248.
|
|||||
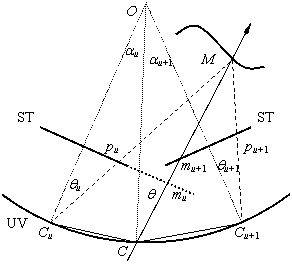 |
Camera Field Rendering of Static and Dynamic Scenes Most of the previously proposed image-based rendering approaches rely on a large number of samples, accurate depth information, or 3D geometric proxies. It is, therefore, a challenge to apply them to render novel views for dynamic scenes as the required information is difficult to obtain in real-time. The proposed approach requires only sparely sampled data. Two new interpolation techniques are presented in this paper, the combination of which can produce reasonable rendering results for sparsely sampled real scenes. The first one, which is a color-matching based interpolation, searches for a possible physical point along the testing ray using color information in nearby reference images. The second technique, which is a disparity-matching based interpolation, tries to find the closest intersection between the testing ray and the disparity surfaces defined by nearby reference images. Both approaches are designed as backward rendering techniques and can be combined to produce robust results. Our experiments suggest that the proposed approach is capable of handling complex dynamic real scenes offline. Reference M. Gong and Y.H. Yang, "Camera field rendering of static and dynamic scenes," Graphical Models, Vol. 67, 2005, pp. 73-99. |
||||
|