Clementine Server Analysis Report
A case study of data mining software product Clementine server5.1
TO:
FOR
CMPUT690
FALL TERM, 1999
By
Hang Cui, Peng Wang, Chong Zhang
Department of Computing Science
University of Alberta
October 20, 1999.
1. Introduction to Clementine *
B.1 Fast and scalable Performance with Distributed Architecture *
B.2 Interactive and efficient mining process with Visual Workflow Interface *
B.3 Multi-applications with various Data Mining Techniques *
B.4 Easy solution deployment with Solution Publisher *
B.7 Exploratory Data Analysis *
What is Clementine Server?
Clementine Server is a commercial data mining system for successful business decision making. It is a large scale, distributed data mining software package with fast and scalable performance, user-friendly visual workflow interface, a wide range of powerful analytical techniques, and sophisticated solution deployment function.
Brief introduction to Clementine
Clementine is a data mining tool that was originally developed by Integral Solution Ltd. in 1994. It adopted the visual workflow interface that integrated a set of tools covering all stages of the data mining process. The old version of Clementine was a standalone application installed on the user’s desktop and run exclusively with that processor’s resources, and worked best with sampled data. Since SPSS’s takeover of Integral Solutions Ltd, Clementine has kept its leading position in data mining software market. In order to keep up with the fast growing demand of its business users, earlier this year, SPSS introduced a new distributed version of Clementine product – Clementine Server 5.1. Compared with the old non-server version, Clementine Server features a unique distributed architecture that achieves optimal performance by running network intensive operations on a server rather than on a desktop computer. It can be applied to larger data sets instead of sampled data for data mining process. Clementine Server’s distributed architecture combining with its visual workflow interface, multiple analytical techniques and Solution Publisher makes it an awarding winning data mining software with a variety of applications in database marketing, customer profiling, promotion response analysis, fraud detection, credit risk scoring, medical risk analysis, survey research, and crime analysis. Nowadays, Clementine server is serving more than 250 organizations worldwide[5].
2. Clememtine Server 5.1
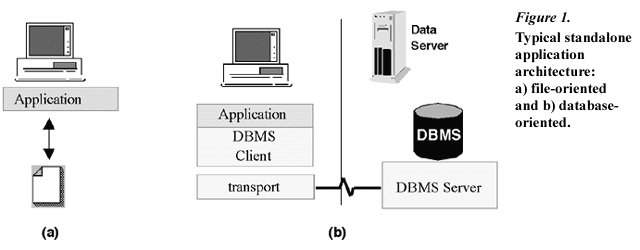
Clementine Server’s distributed architecture enables it to offer much faster and scalable performance for data mining process. Old versions of Clementine products had a standalone application architecture. Under this architecture, the data mining software was installed on the user’s desktop, and run exclusively with that processor’s resources. It treated all files it accessed as if they were on a locally attached hard drive.
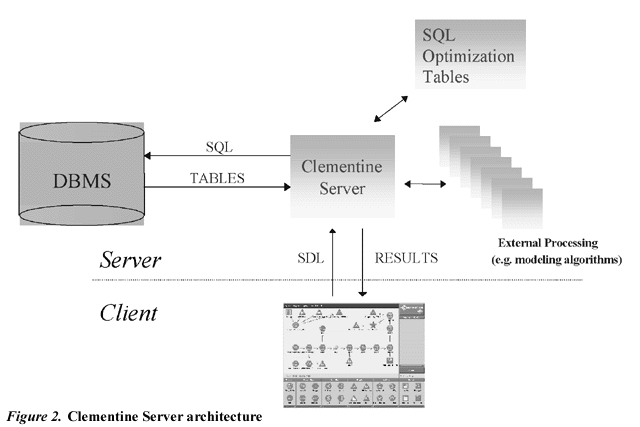
Clementine Server has a three-tier architecture: a desktop client, Clementine Server, and a host database.
During the knowledge discovery, first, the client needs to form a stream to specify the learning process. The description of the stream (SDL code) is sent to Clementine server. The Clementine Server determines which operations can be executed in SQL, and creates appropriate queries. The queries are executed in the database, and the results are sent back to the Server for further processing. Only the relevant summary results are sent back to the client [1].
B.1 Fast and scalable Performance with Distributed Architecture
With distributed architecture, Clementine Server can leverage the power of the DBMS and a fast server to perform analysis faster. This benefit is especially valuable when a large database is involved. Also, Clementine Server can improve its performance by pushing some data operations back to the database or onto a more powerful server machine. It can significant reduce network traffic to desktop machines and manage intermediate storage more efficiently [1].
Data operations that can be push back to database for execution include: Joins, Aggregation, Selection, Sorting, Field Derivation, and Field Projection.
B.2 Interactive and efficient mining process with Visual Workflow Interface
Clementine Server provides an exceptionally user-friendly framework for business users to understand the data mining process. It allows great flexibility for the users to combine data and business knowledge with Clemintine’s analytical techniques to create models that discover the insight for decision making.
Clementine’s user-friendly interface allows user to visualize the data mining journey. There are series of icons available in the visual workflow interface. Each icon represents a distinct step in the date mining process. Users can build a stream with a combination of icons for their own learning process.
It also allows users to add their business knowledge to help optimize each data mining step. This means that the variables for each icon can be created by the users based upon their business know-how. In addition, user can interact with Clementine’s informative graphs, create new variables on the basis of the knowledge discovered in the graph, and then work toward the best possible solution.
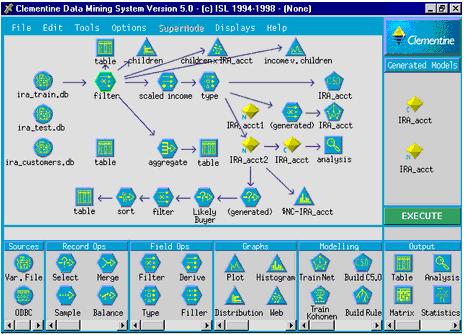
Figure 3: Clementine’s visual workflow interface allows users to create their own mining
process by combing icons.
Multi-applications with various Data Mining TechniquesClementine Server has a wide range of analytical techniques for data mining. This allows Clementine Server to offer a variety of data mining functionalities to meet the needs of different business types, and give user the flexibility to quickly run several different types of models to identify the best one for a specific problem.
Neural Networks:
Neural networks are data models that simulate the structure of the human brain. Neural networks learn from a set of inputs and adjust the parameters of the model according to the new knowledge to find patterns in data.
Neural networks are good at dealing with non-linear data. User doe not need to have any specific model when running the analysis. Neural networks can interpret very complex relationships in data, and often yield very predictive results. Thus, neural networks are best for classifying data because they find trends and patterns in data. They are good tools for forecasting, credit scoring, response model scoring and risk analysis [7].
Graphs
Graphs take advantage of human perception as a technique for data analysis. What numbers can't show you, corresponding graphs often can. Graphs can also be effective presentation tools. Once a discovery is made, the user must convey that discovery using an easily accessible language such as graphs. Clementine’s web graph, plot nodes and histograms give user a visual representation of the strength of connection between the variables in the data. Graph is used to spot characteristics and patterns at a glance [3].
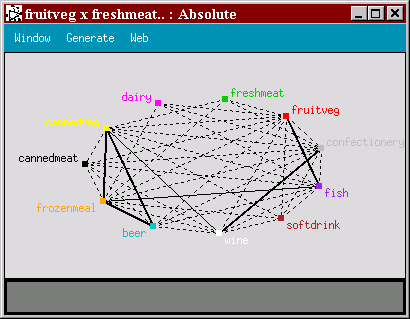 Figure 4:
Clementine’s web graph is a visual tool for association
Figure 4:
Clementine’s web graph is a visual tool for association
Discovery
Rule Induction
Rule Induction technique can yield easily understood rules that can be applied to business decision making. Clementine Server uses rule induction models like GRI and Apriori algorithms as well as C5.0 model to find association rules in data.
Clustering Methods
Cluster analysis is a data reduction technique that groups together either variables or cases based on similar data characteristics. This technique is useful for finding customer segments based on characteristics such as demographic and financial information or purchase behavior. Clementine uses Kohonen network and K-means for segmentation.
Linear Regression
Linear regression is a method that fits a straight line through data. If the line is upward sloping it means that an independent variable has a positive effect on a dependent variable. If the line is downward sloping there is a negative effect. The steeper the slope, the more effect the independent variable has on the dependent variable. Although many business models are not linear, many models can be linearized by a log transformation. Linear regression is used for predicting future business trends based on input variables[7].
B.4 Easy solution deployment with Solution Publisher
Clementine solution publisher is a post data-mining step that helps user to build an application quickly and effectively during the initial rollout. After the user builds a stream, validates and modifies the model using Clementine’s visual workflow interface, the stream can be connected to Solution Publisher node. Solution Publisher’s export options enable user to specify the type of output to generate from the exported Clementine stream. The output can be a node that yields data statistics; a file export that allows results to be written in ASCII file; or a database that puts results in a database table. Executing the Solution Publisher node can generate an application, and the files can be compiled for deployment throughout the organization.
Depending on the goals and needs of the KDD process, user may select, merge, aggregate, filter or clean the target datasets. Clementine provides these functionality seamlessly in the visual modeling environment, which makes the data mining process more efficiently and accurately.
Clementine provides an architecture that makes it easy to incorporate new modeling method. Its external module interface allows users' favorite algorithms and utilities to be added to Clementine's visual programming environment.
With Clementine's visual workflow interface, it takes advantage of users’ business expertise to achieve better solutions. Once specific business problem is identified, the users can combine their data and business knowledge with Clementine to create models that contain their insight. This enables users to apply their business know how to the modeling process interactively.
Clementine exports the model into a C program that can be embedded in another
program and a platform-specific makefile.
Clementine stores intermediate results on disk instead of RAM. Because servers usually have significantly more disk space available than RAM, Clementine Server can perform operations such as sort, merge and aggregation on large data sets.
Data mining functionalities specify the kinds of patterns to be found in data mining tasks. Clementine Server is a data mining system that can mine multiple kinds of patterns in parallel to accommodate different user expectations and application, thanks to its wide range of data analytical techniques and user-friendly visual workflow interface.
Forms of model used: rule induction, neural networks and decision tree.
Applications example: describe and distinguish data classes and concepts, i.e.
categorize customers or clients according their shopping behavior.
Forms of model used: Kohonen networks, rule induction, and k-means.
Application example: Group people or products with similar characteristics together,
i.e. crime detection: Cluster physical descriptions and crime pattern in electronic
case files, combines clusters to see whether groups of similar physical descriptions
coincide with groups of similar crime pattern. If good match is found, and
perpetrators are known for one or more of the offenses, it is possible that the cases
were committed by the same individuals.
Forms of model used: web diagrams, Apriori, and rule induction.
Application example: discover products that are purchased together, i.e. bread and milk association.
Forms of models used: rule induction, neural networks, and linear regression.
Application example: find patterns and trends from time series data like stock prices.
Forms of model used: rule induction and neural networks.
Application example: forecast future sales or usage of a product, i.e. IRA account
promotion. Training Data (Trial mailing in random samples of customers)à
Apply the model to customer database to find who is mostly likely to buy IRA
account [3].
Live Data Warehouse (e.g. Oracle on a large UNIX server), or Data mart (e.g. SQL
Server on an NT server).
Clementine is a comprehensive data mining system that provides multiple functionalities such as association, classification, clustering, trend and evolution analysis, prediction and sequence.
Interactive exploratory systems, Neural Networks, Rule Induction, Clustering,
Graph, Linear Regression. [7]
Customer relationship management:
Product safety evaluation:
Sitting retail outlets:
Traffic flow prediction:
Exchange price verification:
F. Clementine 5.1 Specifications:
Platforms supported for server software:[4]
Windows NT 4.0
Sun Solaris
IBM AIX
Hewlett-Packard HP/UX
Clementine 5.1 (Standalone)
Windows NT
HP Workstations
SG Workstations
SunSPARC
DEC Alpha (Digital UNIX)
IBM RS6000
Data General AViiON
NCR UNIX®
spatial data, multimedia data, and Web-based global information system.
[1] White Paper: "Clementine Server Distributed Architecture"
http://www.spss.com/clementine/downloads.htm, SPSS Corp. 1999
[2] http://www.spss.com/clementine/apps.htm, SPSS Corp. 1999
[3] http://www.spss.com/clementine/capabilities.htm, SPSS Corp. 1999
[4] http://www.spss.com/clementine/specs.htm, SPSS Corp., 1999
[5] http://www.spss.com/press/biaward.htm, SPSS Corp., 1999
[6] http://www.isldsi.com, ISL Decision Systems Inc, 1998
[7] Jiawei Han, Micheline Kanber, "Data Mining: Concepts and Techniques",
Morgan Kaufmann Publishers, 2000
[8] Michael Goebel, Le Gruenwald, "A Survey of Data Mining and Knowledge
Discovery Software Tools", ACM SIGKDD Explorations, June 1999.