Talk schedule and abstracts
Sun 8:30-10:20
Global optimization, large reconstruction problems
- Fredrik Kahl, Lund University
Global Optimization for Geometric Reconstruction Problems (40 min).
In this talk, a framework for solving various geometric fitting problems appearing
in computer vision will be presented. The overall goal is to find the best model
which is most consistent with the observations. In the context of structure from
motion, this means that the differences between the reprojected 3D scene geometry
and the image measurements should be minimized. While traditional reconstruction
algorithms often suffer from local minima, we pursue the goal of achieving
globally optimal solutions. Two different optimization approaches will be
considered, first a Branch & Bound approach using convex envelopes and second,
lower-bounding relaxations based on Linear Matrix Inequalities (LMI). These
schemes are applied to a number of classical vision and fitting problems.
Slides: .pdf, .ppt
-
Richard Hartley, Australian National University
Some aspects of quasi-convex optimization (35-40 min).
Quasi-convex optimization problems have been studied recently in
geometric computer vision; many common problems turn out to
be quasi-convex optimization problems in L-infinity norm.
The present talk will focus particularly on some pleasant properties of
quasi-convex functions that make quasi-convex optimization both in
L-2 norm and L-infinity norm simpler than general problems.
In particular, it will be shown with respect to outliers, that in solution
of a problem with outliers, the set of measurements with maximum
residual always contains at least one outlier. This is not the case
with general optimization problems.
A further useful property is that any estimate of the minimum of
a cost function formed from a sum of quasi-convex functions will
greatly restrict the positin of the optimal solution, so that
localization of the absolute global minimum is possible (in L-2 norm).
- Ananth Ranganathan, Georgia Tech
Inference in Large-Scale Graphical Models and its application to matching
problems in Structure from Motion and SLAM
Large-scale reconstruction problems where appearance information is
unreliable or unavailable pose special challenges. The 4D-Cities project,
that our group is involved in, is a case in point, as is laser-based
Simultaneous Localization and Mapping (SLAM) in robotics. In such cases,
reliable matching can be achieved by computing marginal covariances for
the structure and motion variables and using this to perform maximum
likelihood correspondence. However, it is well-known that marginal
covariances are expensive to obtain. In this talk, I will present recent
work by our group that exploits the connections between reconstruction
problems and graphical models. Both Structure from Motion and SLAM can be
posed in terms of this
graphical model language, and inference in them can be explained in a
purely graphical manner via the concept of variable elimination. This
leads to a new way of looking at inference that is equivalent to the
junction tree algorithm yet is, in some ways, much more insightful. When
applied to linear(ized) Gaussian problems, the algorithm yields the
familiar QR and Cholesky factorization algorithms, and this connection
with linear algebra in turn leads to strategies for very fast inference in
familiar QR and Cholesky factorization algorithms, and this connection
with linear algebra in turn leads to strategies for very fast inference in
arbitrary graphs. I will present some published results from SLAM and some
preliminary results from 4d-Cities that exploits this connection to the
fullest.
Slides: .pdf, .ppt
Sun 10:50-12
Multi-View Geometry
-
David Nistér, University of Kentucky
Vision Geometry Applied to Audio: Quadrisonal Tensor or Absolute Sonic? (25 min).
In this talk I will outline a new algorithm for determining the Euclidean
configuration of a number of microphones using only the sound arriving at the microphones.
More precisely, it is assumed that 'correspondence' is solved, so that
time-differences-of-arrival (TDOA) measurements are available.
The algorithm works for any spatial dimension. In 3D, it is possible to determine
the configuration of four microphones hearing six or more sound sources.
The algorithm is a beautiful least squares method working with the square KK' of
the Euclidean shape, very much like the absolute conic. It encodes the configuration
of the four microphones and therefore also deserves the name quadrisonal tensor.
The algorithm assumes distant sound sources, which makes the problem much more tractable
than the finite counterpart. The algorithm is therefore in a sense a
'Tomasi-Kanade algorithm for audio'. I will also discuss critical configurations for the algorithm.
- Anders Heyden, Malmö University
Differential-Algebraic Multiview Constraints.
Motion estimation has traditionally been approached either from
a pure discrete point of view, using multi-view tensors, or from a pure
continuous point of view, using optical flow.
This talk presents a novel framework for unifying these two different
approaches and also derives hybrid methods combining the best
part of each of them.
The main contributions of the talk are (i) to bridge the gap between the
discrete and the continuous approach to motion estimation, (ii) to derive
differential-algebraic matching constraints that can be used for matching
constraint tracking, and (iii) to present novel algorithms for updating the
motion parameters from image correspondences, requiring fewer points
than the traditional methods and also avoiding the non-linear constraints
usually appearing in the calibrated case.
Firstly, we show how the continuous epipolar constraint is related to the
discrete epipolar constraint via a limiting process. Secondly, we derive
several hybrid matching constraints involving both discrete parts (i.e.
widely separated cameras) and continuous/finite difference parts (i.e.
closely spaced cameras). Finally, we propose two different methods
for updating the essential matrix in an image sequence. The first method
requires six points, and the second one only three points, for the update
and the equations are linear in the motion parameters.
We will also present extensions to trifocal tensor tracking based on
another type of differential-algebraic constraints and motion tracking
of a rigid stereo-head based on yet another type of constraints.
Slides: .pdf, .ppt
Sun 13:30-15
Geometry/Misc
- Marc Pollefeys, University of North Carolina
Reconstructing Dynamic Scenes with One or More Cameras
In this talk we discuss different approaches to obtain 3D
reconstructions of dynamic scenes. We first present an approach to
analyze and recover articulated motion with non-rigid parts, e.g. the
human body motion with non-rigid facial motion, under affine projection
from feature trajectories. We model the motion using a set of
intersecting subspaces. Based on this model, we can analyze and recover
the articulated motion using subspace methods. Our framework consists of
motion segmentation, kinematic chain building, and shape recovery. We
test our approach through experiments and demonstrate its potential to
recover articulated structure with non-rigid parts via a single-view
camera without prior knowledge of its kinematic structure. Next, we
discuss ongoing work to recover a dynamic shape from silhouettes in the
presence of occlusion. Our approach nto only recovers the dynamic
shape, but is also able to recover the shape of the occluder.
Slides: .pdf, .ppt ,
Videos:
Head,
jingyu,
jingyu2,
oldwell,
people1sculpt,
people2sculpt,
puppet,
toy1
References:
J. Yan, M. Pollefeys, Recovering Articulated Non-rigid Shapes,
Motions and Kinematic Chains From Video, AMDO'06 (Conference on
Articulated Motion and Deformable Objects), 2006.
J. Yan, M. Pollefeys, Automatic Kinematic Chain Building from
Feature Trajectories of Articulated Objects, Proc. CVPR, 2006.
J. Yan, M. Pollefeys,
[pdf A General Framework for Motion Segmentation:
Independent, Articulated, Rigid, Non-rigid, Degenerate and
Non-degenerate , European Conference on Computer Vision, 2006.
J. Yan, M. Pollefeys, A factorization approach to articulated
motion recovery, IEEE Conf. on Computer Vision and Pattern
Recognition, 2005.
- Rene Vidal, Johns Hopkins University
Segmentation of Dynamic Scenes and Textures
Abstract:
Dynamic scenes are video sequences containing multiple objects moving in
front of dynamic backgrounds, e.g. a bird floating on water. One can
model
such scenes as the output of a collection of dynamical models exhibiting
discontinuous behavior both in space, due to the presence of multiple
moving
objects, and in time, due to the appearance and disappearance of
objects.
Segmentation of dynamic scenes is then equivalent to the
identification of
this mixture of dynamical models from the image data. Unfortunately,
although the identification of a single dynamical model is a well
understood
problem, the identification of multiple hybrid dynamical models is
not. Even
in the case of static data, e.g. a set of points living in multiple
subspaces, data segmentation is usually thought of as a "chicken-and-
egg"
problem. This is because in order to estimate a mixture of models one
needs
to first segment the data and in order to segment the data one needs
to know
the model parameters. Therefore, static data segmentation is usually
solved
by alternating data clustering and model fitting using, e.g., the
Expectation Maximization (EM) algorithm.
Our recent work on Generalized Principal Component Analysis (GPCA)
has shown
that the "chicken-and-egg" dilemma can be tackled using algebraic
geometric
techniques. In the case of data living in a collection of (static)
subspaces, one can segment the data by fitting a set of polynomials
to all
data points (without first clustering the data) and then differentiating
these polynomials to obtain the model parameters for each group. In this
talk, we will present ongoing work addressing the extension of GPCA to
time-series data living in a collection of multiple moving subspaces.
The
approach combines classical GPCA with newly developed recursive hybrid
system identification algorithms. We will also present applications
of DGPCA
in image/video segmentation, 3-D motion segmentation, dynamic texture
segmentation, and heart motion analysis.
Slides: .pdf
- Raghav Subbarao, Rutgers University
Nonparametric Methods over Analytic Manifolds in Computer Vision (30 min).
Many low-level and mid-level vision tasks involve the estimation of
parameters in the presence of noise and outliers. The use of parametric
models at this stage may lead to incorrect results which are compounded by
the high-level modules of a vision system. An alternative to this is the
use of nonparametric techniques for the analysis of visual data. The
original mean shift algorithm is one such nonparametric method which has
been widely used in computer vision for tracking, robust fusion, smoothing
and segmentation.
In all previous applications of mean shift, it has always been
applied to vector spaces. However, in practice the geometric constraints
involved in the problem and the nature of the imaging device, lead to
feature spaces which are not vector spaces. Most of these feature spaces
still exhibit a regular geometry and belong to the class of analytic
manifolds, which have been well studied in fields such as differential
geometry. We develop a Nonlinear Mean Shift algorithm which is a
generalization of mean shift to analytic manifolds. The nonlinear mean
shift algorithm can be used for motion segmentation, model-based optical
flow field segmentation and diffusion tensor image smoothing.
As examples, two specific classes of frequently occurring
parameter spaces, Grassmann manifolds and matrix Lie groups, are
considered. The algorithm is applied to a variety of robust motion
segmentation problems and multibody factorization. The motion segmentation
method is robust to outliers, does not require any prior specification of
the number of independent motions and simultaneously estimates all the
motions present.
We are currently exploring other applications of the algorithm
such as the smoothing of tensor fields and optical flow field
segmentation.
Slides: .pdf, .ppt
Sun 15:45-17:30
Reconstruction 1
- Yasutaka Furukawa, University of Illinois
Multi-View Stereo through Feature Matching and Expansion.
I'm going to present a novel multi-view stereo algorithm, which
reconstructs a dense set of oriented points (or patches) from a set of
calibrated photographs, where a 3D coordinate and a surface normal are
estimated at each oriented point. In particular, the algorithm starts
by detecting a set of feature points in each image, and matches them
across multiple imagess. Matched feature points yield a single patch,
and this initial matching step produces a set of patches covering the
surface of an object (or a scene) of interests. However, the generated
patches are rather sparse and only correspond to regions with salient
image features. In order to get a dense coverage, we use a simple
patch expansion step that makes use of the estimated surface normal
information. The proposed method has many advantages over existing
multi-view stereo algorithms. First of all, the method does not
require any initialization, such as a visual hull or a bounding box
that are often used to start the iterative deformation of a
surface. Secondly, it can handle an object of complicated topology,
because it has little regularization. Thirdly, the method is memory
efficient. It does not use voxels and the memory usage is simply
proportional to the size of inputs and outputs. Lastly, our approach
can handle outliers in input images (e.g., pedestrials in an outdoor
scene). The proposed method has been implemented and tested on various
datasets. We have also implemented a couple of algorithms that
reconstruct a polygonal mesh from a set of patches, and have conducted
qualitative and quantitative comparisons with models obtained by
state-of-the-art image-based modeling algorithms and laser range
scanners.
Slides: .pdf, .ppt
- Kyros Kutulakos, University of Toronto
High-resolution 3D photography by Confocal Stereo
The high-resolution sensors in today's digital SLR cameras open the
possibility of imaging complex scenes at a very high level of
detail---with resolutions surpassing 12Mpixels, even individual
strands of hair may be one or more pixels wide. In this talk I will
discuss a new 3D photography method called "Confocal Stereo" that is
specifically designed for reconstructing scenes with high geometric
complexity or fine-scale texture (hair, dirty transparent surfaces,
etc). Confocal stereo relies on the ability to control the focus and
aperture of a lens and requires nothing more than a camera with an
off-the-shelf wide-aperture lens (e.g., f1.2) and a laptop for
controlling the camera's settings. At the heart of the approach is the
confocal constancy property, which states that as the lens aperture
varies, the pixel intensity of a visible in-focus scene point will
vary in a scene-independent way. To expoit it, we develop a detailed
lens model that factors out the geometric and radiometric distortions
in high resolution SLR cameras with wide-aperture lenses. I will
discuss how we can recover this lens model from images and how we can
use it to reconstruct detailed 3D shape for a variety of complex
scenes.
- Gabriel Taubin, Brown University
Multi-Flash 3D Photography.
This talk introduces a new 3D scanning system which exploits the depth
discontinuity information captured by a multi-flash camera as an object
moves along a known path. In contrast to existing differential and global
shape-from-silhouette algorithms, this method can reconstruct the position
and orientation of points located deep inside concavities. Since more
information than what silhouettes provide is used, the resulting shapes are
a much tighter fit to the surface of the scanned object than a visual hull,
perhaps competing in quality to laser scanners. However, points which do not
produce an observable depth discontinuity cannot be recovered. The resulting
point cloud is unevenly sampled, with very low sampling rate in shallow
concavities or flat areas. To fill the holes an implicit surface is fit to
the oriented point cloud, which is used to generate additional oriented
points on the surface of the object in regions of low sampling density.
Finally, the appearance of each surface point is modeled by fitting a Phong
reflectance model to the BRDF samples using the visibility information
provided by the implicit surface. I will present experimental results for a
variety of objects imaged while rotating on a computer controlled turntable.
Slides: .pdf
Sun 19-20:30
Plenary talks/Banff centre interaction
Talks of interest to a wide Banff Centre audience
- Gabriel Taubin, Brown U. "The digital capture and virtual exhibit of Michelangelo's Pieta"
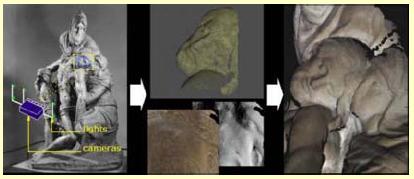
We describe a project to create a three-dimensional digital model of Michelangelo s Florentine Piet`a. The model is being used in a comprehensive art-historical study of this sculpture that includes a consideration of historical records and artistic significance as well as scientific data. A combined multi-view and photometric system is used to capture hundreds of small meshes on the surface, each with a detailed normals and re- flectance map aligned to the mesh. The overlapping meshes are registered and merged into a single triangle mesh. A set of reflectance and normals maps covering the statue are computed from the best data available from multiple color measurements. In this paper, we present the methodology we used to acquire the data and construct a computer model of the large statue with enough detail and accuracy to make it useful in scientific studies. We also describe some preliminary studies being made by an art historian using the model.
- Noah Snavely and
Richard Szeliski, Microsoft:
"Photo-tourism Exploring photo collections in 3D"
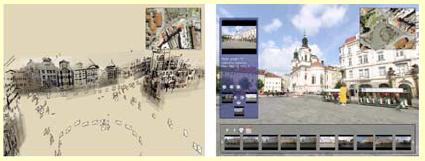 We present a system for interactively browsing and exploring large unstructured collections of photographs of a scene using a novel 3D interface. Our system consists of an image-based modeling front end that automatically computes the viewpoint of each photograph as well as a sparse 3D model of the scene and image to model correspondences. Our photo explorer uses image-based rendering techniques to smoothly transition between photographs, while also enabling full 3D navigation and exploration of the set of images and world geometry, along with auxiliary information such as overhead maps. Our system also makes it easy to construct photo tours of scenic or historic locations, and to annotate image details, which are automatically transferred to other relevant images. We demonstrate our system on several large personal photo collections as well as images gathered from Internet photo sharing sites.
We present a system for interactively browsing and exploring large unstructured collections of photographs of a scene using a novel 3D interface. Our system consists of an image-based modeling front end that automatically computes the viewpoint of each photograph as well as a sparse 3D model of the scene and image to model correspondences. Our photo explorer uses image-based rendering techniques to smoothly transition between photographs, while also enabling full 3D navigation and exploration of the set of images and world geometry, along with auxiliary information such as overhead maps. Our system also makes it easy to construct photo tours of scenic or historic locations, and to annotate image details, which are automatically transferred to other relevant images. We demonstrate our system on several large personal photo collections as well as images gathered from Internet photo sharing sites.
Slides: .pdf, .ppt,
Videos:
BasilSmall,
FlickrSearch2,
GreatWall,
HalfDomeInteract4,
NotreDameAnnotate1a,
PragueAlign2,
PragueInteract3,
PragueMorph2,
TrafalgarSmall,
TreviReconstruct2,
TreviFlythrough2,
TreviInteract2
References:
Snavely, N., Seitz, S., Szeliski, R.
Photo Tourism: Exploring photo collections in 3D,
SIGGRAPH 2006
Mon 8:30-10:10
Variational methods
- Jan Erik Solem, Malmö University
Variational problems and level set methods in comptuer vision: theory
and applications
Current state of the art suggests the use of variational
formulations for solving a variety of computer vision problems.
This talk deals with such variational problems which often
include the optimization of curves and surfaces. The level set
method is used throughout the talk, both as a tool in the
theoretical analysis and for constructing practical algorithms.
One frequently occurring example is the problem of recovering
three-dimensional (3D) models of a scene given only a sequence of
images. Other applications such as segmentation are also
considered.
The talk consists of three parts. The first part contains a
review of background material and the level set method. The second
part contains a collection of theoretical contributions such as a
gradient descent framework and an analysis of several variational
curve and surface problems. The third part contains contributions
for applications such as a framework for open surfaces and
variational surface fitting to different types of data.
Slides: .pdf
- Yuri Boykov, University of Western Ontario
Connecting graph cuts and level sets:
Discrete optimization methods for solving continuous problems
Among a multitude of image segmentation methods, the level set method and
the graph minimal cut approaches have emerged as two powerful paradigms to
compute the segmentation of images. Both methods are based on fundamentally
different representations of images. Level sets are formulated as
infinite-dimensional optimization on a spatially continuous image domain.
The Graph Cuts, on the other hand, are defined as minimal cuts of a discrete
graph representing the pixels of the image.
In this talk, we want to bridge the gap between these seemingly very
different paradigms. We demonstrate that graph cuts is an efficient tool for
global and/or
local optimization of typical in computer vision geometric surface
functionals that are currently addressed mainly with variational methods
based on gradient flow PDEs.
Slides: .pdf, .ppt
- Todd Zickler, Harvard University
Appearance Decomposition for Image-based Reconstruction
Image-based reconstruction systems are designed to accurately recover
the
three-dimensional shape of a scene from its two-dimensional images. The
reconstruction problem is ill-posed because images do not generally
provide direct access to 3D shape. Instead, shape information is coupled
with additional factors: illumination, pose and surface reflectance.
Shape is typically recovered by making assumptions about reflectance. It
is often assumed, for example, that surfaces are Lambertian; and when
this
assumption is violated, the accuracy of the recovered shape can be
compromised.
In this talk, I discuss two techniques for recovering shape that relax
the assumptions about surface reflectance. Both methods are based on a
notion of 'appearance decomposition'. By decoupling some of the factors
that determine an image (shape, reflectance, illumination and pose), we
obtain more direct access to shape information, greatly simplifying the
reconstruction problem.
In the first part of the talk I discuss Helmholtz stereopsis, and I
focus
on recent calibration work that makes this a more practical
reconstruction
technique. In the second part, I present a family of colour-based
photometric invariants that extend the applicability of Lambertian-based
reconstruction techniques (SFM, stereo, photometric stereo,
shape-from-shading, etc.) to a broad class of specular, non-Lambertian
scenes.
Slides: .pdf, .ppt
Video: face_1Dsubspace
References:
Zickler, T.
Reciprocal Image Features for Uncalibrated Helmholtz Stereopsis,
Proc. IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), 2006.
Zickler, T., Mallick, S. P., Kriegman, D. J., and Belhumeur, P. N.
Color Subspaces as Photometric Invariants, Proc. IEEE
Conference on Computer Vision and Pattern Recognition (CVPR), 2006.
Mallick, S. P., Zickler, T., Kriegman, D. J., and Belhumeur, P. N.
Beyond Lambert: Reconstructing Specular Surfaces Using Color,
Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR)
2005.
Mon 10:40-11:30
Reconstruction 2
- Geert Caenen, KU Leuven
Generative imaging models (20 min).
Generative models have already shown their value in computer vision. By
explicitly formulating the image formation process (i.e. describing how
the available data has been obtained) in terms of different parameters
and the unknown "real world", several inference problems can be solved
by inverting this process.
The probabilistic nature of the framework allows for the introduction of
(prior) assumptions that can express coherence of the data, (coherent)
outliers and much more.
The talk will introduce the mathematical building blocks and tools (i.c.
EM-algortihm) for solving the aforementioned problems. Next, different
applications showing the genericity and the modularity of the framework
are discussed and illustrated with numerous examples: image
registration, depth computation, ...
Slides: .pdf, .ppt
- Stefan Roth, Brown University
Specular Flow and the Recovery of Surface Structure (25 min).
In scenes containing specular objects, the image motion observed by a
moving camera may be an intermixed combination of optical flow
resulting from diffuse reflectance (diffuse flow) and specular
reflection (specular flow). In this talk I will formalize the notion
of specular flow with few assumptions, show how it relates to the 3D
structure of the world, and develop an algorithm for estimating scene
structure from 2D image motion. Unlike previous work on isolated
specular highlights we use two image frames and estimate the semi-
dense flow arising from the specular reflections of textured scenes.
We parametrically model the image motion of a quadratic surface patch
viewed from a moving camera. The flow is modeled as a probabilistic
mixture of diffuse and specular components and the 3D shape is
recovered using an Expectation-Maximization algorithm. Rather than
treating specular reflections as noise to be removed or ignored, I
will show that the specular flow provides additional constraints on
scene geometry that improve estimation of 3D structure when compared
with reconstruction from diffuse flow alone. I will illustrate this
for a set of synthetic and real sequences of mixed specular-diffuse
objects.
Slides: .pdf,
Videos:
stabilize_diffuse,
stabilize_specular
References:
Stefan Roth and Michael J. Black.
Specular Flow and the Recovery of Surface Structure. In Proc. of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), vol. 2, pp. 1869-1876, June 2006.
Mon 14-15:30
Reconstruction 3
- Yuri Boykov, University of Western Ontario
From Photohulls to Photoflux Optimization
Our work was inspired by recent advances in image segmentation where flux
based functionals significantly improved alignment of object boundaries.
We propose a novel "photoflux" functional for multi-view 3D reconstruction
that is closely related to properties of photohulls. Our photohull prior
can be combined with regularization. Thus, this work unifies two major
groups of multiview stereo techniques: ``space carving'' and ``deformable models''.
Our approach combines benefits of both groups and allows to recover fine
shape details without oversmoothing while robustly handling noise.
Photoflux provides data-driven ballooning force helping to segment thin
structures or holes. We propose a number of different versions of photoflux
based on global, local, or non-deterministic visibility models. Some forms
of photoflux can be easily added into standard regularization techniques.
For other forms we propose new optimization methods. We also show that
photoflux maximizing shapes can be seen as regularized Laplacian zero-crossings.
Slides: .pdf, .ppt
- Patrick Hébert, Université Laval
A Unified Surface Representation
for 3-D Imaging and Modeling: A Necessity for Efficient
Integration of Geometry and Appearance Properties
We present our recent work on object 3D shape and appearance modeling. From a set of input data, the process builds a 3D model, i.e. a geometric representation of the surface of each object augmented with their appearance. This process requires multiple steps that vary depending on the type of input data: colour images or range data. In recent years, we have focussed on surface representation instead of developing each step independently. We have considered modeling as a unified process from data as opposed to a cascaded series of steps.
In order to illustrate the importance of selecting an appropriate surface representation, we first describe the approach that we have developed for interactive modeling of the surface geometry from range data. This process must be real-time and continuous over an extended period of time. It involves several steps including acquisition, alignment, fusion, surface reconstruction, visualisation as well as compression. A necessary condition for interactive modeling is that the computational complexity of all steps be linear with respect to the amount of acquired data. This can be fulfilled when, for a given point in 3D space, the closest point on the model can be identified in O(1). This is made possible by recovering the model in a volumetric representation based on vector fields. From range data, we can directly recover the gradient of the signed distance field and show how each step benefits from this representation. Furthermore, the whole framework is general enough to benefit from any type of range data (point clouds, curves, surface patches).
Although the previous framework can be improved by integrating appearance characteristics into the volumetric representation, we have also started investigating new approaches for modeling surface appearance. When the objective is to produce a model for visualization purposes only, recovering the accurate geometry is not a requirement as long as the appearance is photorealistic. Moreover, since no specific reflectance model is assumed, we are studying an image-based approach that exploits data acquired from a camera that is moved around an object to produce a light field from a large set of calibrated images. However, the selection of a specific surface for parameterising the light field has great influence on the quality of the visual simulation. We have proposed a frequency-based criterion to estimate a light field parameterisation surface that is adapted to the object and to the set of views. These ideas have been validated using an explicit surface representation (a mesh) that is deformed according to the criterion. Similar to some multi-view stereo algorithms, the mesh is initially set to the visual hull which is obtained after object-background segmentation in each image. This last operation exploits an implicit surface representation. We expose our current challenge of unifying all these steps in an effort to produce the light field in a common representation.
Slides: .pdf, .ppt
Videos:
HandyScan22sec,
Plate20sec
- Li Zhang, Columbia University
A Spacetime Approach to 3D Photography (45 min).
Recovering the 3D structure of a scene from photographs is an important
problem in several areas, including computer vision, computer graphics,
and robotics. Two fundamental challenges in 3D photography are the accurate
reconstruction of scenes with complex occlusions and scenes containing dynamic
objects. In this talk, I present a spacetime approach for solving these two
problems, which exploits the temporal variation of spatial visual cues, such
as defocus and stereo. I will first present a temporal defocus method, which
reliably recovers the 3D structure of a scene, regardless of its occlusion
complexity. Then, I will present a spacetime stereo method which accurately
reconstructs objects that are deforming over time. Both methods significantly
outperform the state-of-the-art techniques for 3D sensing. Finally, I will
demonstrate several applications of the proposed methods to computer graphics,
including image refocusing, video composition, expression synthesis, and facial
animation.
Slides:
.ppt
Mon 16-18
New Media Interaction Session 2
-
Neil Birkbeck, Adam Rachmielowski, U of Alberta "Capture of 3D models from 2D photos using variational shape and reflectance estimation"

Fitting parameterized 3D shape and general reflectance models to 2D image data is challenging due to the high dimensionality of the problem. The proposed method combines the capabilities of classical and photometric stereo, allowing for accurate reconstruction of both textured and non-textured surfaces. In particular, we present a variational method implemented as a PDE-driven surface evolution interleaved with reflectance estimation. The surface is represented on an adaptiveobject-centered mesh and the evolution allows topological change.
To provide the input data, we have designed a capture setup that simultaneously acquires both viewpoint and light variation while minimizing self-shadowing. Our capture method is feasible for real-world application as it requires a moderate amount of input data and processing time. In experiments, models of people and everyday objects were captured from a few dozen images taken with a consumer digital camera. The capture process recovers a photo-consistent model of spatially varying Lambertian and specular reflectance and a highly accurate geometry.
Slides:
.pdf,
.ppt
References:
Birkbeck, N., Cobzas, D., Sturm, P., Jagersand, M.
Variational Shape and Reflectance Estimation under Changing Light and
Viewpoints,
European Conference on Computer Vision (ECCV) 2006
Birkbeck, N., Cobzas, D., Jagersand, M.
Object centered stereo: displacement map estimation using texture and shading,
Third International Symposium on 3D Data Processing, Visualization and Transmission (3DPVT) 2006
Martin Jagersand, Dana Cobzas, Keith Yerex
Modulating View-dependent Textures,
Eurographics 2004, pp69-72, short presentation
-
Jim Rehg: Georgia Tech, "Projector-Guided Painting"
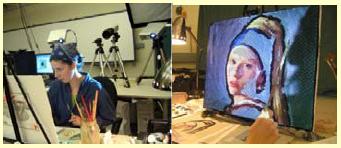
We present a novel interactive system for guiding artists to paint using traditional media and tools. The enabling technology is a multi-projector display capable of controlling the appearance of an artist.s canvas. Artists are guided by this display-on-canvas to paint according to a process model we designed to solve 3 common problems with novice painters. The artist paints according to a linear process of painting in layers and, within each layer, a set of colors. Each component of our model of the painting process has an associated interaction mode. Preview mode shows the entire layer as the current painting goal. Blank mode reveals the state of the painting. Color selection mode displays where to paint a target color. Color mixing mode shows how to mix it and orientation mode shows how to paint it. These interaction modes enable the novice to focus on painting sub-tasks in order to simplify the painting process while providing technical guidance ranging from high-level composition to detailed brushwork. We present results of a user study that quantify the benefit that our system can provide to a novice painter.
Slides: .pdf, .ppt
-
Adrian Broadhurst, Vicon, Motion capture, the state of the art and new developments

State of the art motion capture systems use reflective markers, placed on the actor's body, to capture the actor's motion. High resolution greyscale cameras with onboard digital processing, are used to capture and process the reflections of markers at very high frame rates and densities. The captured 2D data is processed through to labelled 3D points, which are used to drive a wide variety character skeletons. A sophisticated XML representation is used to describe the character topology including many different joint types. Character models, including bone lengths, and marker positions are automatically adjusted to fit the actor, using example data. At the start of the day, all actors are required to perform a range-of-motion to movement, to obtain this initial calibration data.
This presentation will demonstrate the state of the art for motion capture systems, and show the technical challenges of providing data to the standards expected by current users, and the large scale of high end motion capture systems.
- Geert Caenen, KU Leuven An Internet application for 3D modeling from 2D photos

This service allows archaeologists and engineers to upload digital
images to our servers where we perform a 3D reconstruction of the scene
and report the output back to the user.
Uploading Images
The first simple application is the upload tool. All that is required is
that a sequence of images is uploaded to the server. The order of the
images can be set by the user, and the images can be subsampled before
uploading for a faster service.
While You're Waiting...
This is where the service really does its work. At VISICS, we have
developed software to compute the reconstruction over a distributed
network of PCs. This makes our procedure much faster and also more
robust. Depending on the size, number and quality of the images that
have been uploaded, a typical job may take from 15 minutes to 2 or 3 hours.
Building a Model...
Once the reconstruction has been successful, the system notifies the
user by email. They can then use this data to produce a 3D model with
the model viewer tool.
Slides: .pdf, .ppt,
Videos:
eindhoven_alignment,
eindhoven_3d,
maya,
adt1,
adt2
Mon 19-21
Demos related to New Media interaction talks
Max Bell 1st floor Demos related to interaction talks
Demos
- Noah Snavely, U of Washington, Rich Szeliski Microsoft: Photo-tourism
- Adam Rachmielowski/Neil Birkbeck, U of Alberta: 3D capture from 2D photos
- Matt Flagg/Jim Rehg Georgia Tech, Projector guided painting
- Adrian Broadhurst, Vicon, Motion capture
- Geert Caenen, KU Leuven An Internet application for 3D modeling from 2D photos
Posters
Recursive Structure from Motion using Hybrid Matching Constraints with Error Feedback
Fredrik Nyberg and Anders Heyden
Applied Mathematics Group School of Technology and Society
Malmo University, Sweden
We propose an algorithm for recursive estimation of struc- ture and motion in rigid body perspective dynamic systems, based on the novel concept of continuous-di®erential matching constraints for the estimation of the velocity parameters. The parameter estimation proce- dure is fused with a continuous-discrete extended Kalman filter for the state estimation. Also, the structure and motion estimation processes are connected by a reprojection error constraint, where feedback of the structure estimates is used to recursively obtain corrections to the motion parameters, leading to more accurate estimates and a more robust performance of the method. The main advantages of the presented algorithm are that after initialization, only three observed object point correspondences between consecutive pairs of views are required for the sequential motion estimation, and that both the parameter update and the correction step are performed using linear constraints only. Simulated experiments are provided to demonstrate the performance of the method.
Spherical Catadioptric Arrays: Construction, Multi-View Geometry, and
Calibration
By Douglas Lanman, Daniel Crispell, Megan Wachs, and Gabriel Taubin
Brown Univ.
This paper introduces a novel imaging system composed of an array of
spherical mirrors and a single highresolution digital camera. We describe
the mechanical design and construction of a prototype, analyze the geometry
of image formation, present a tailored calibration algorithm, and discuss
the effect that design decisions had on the calibration routine. This system
is presented as a unique platform for the development of efficient
multi-view imaging algorithms which exploit the combined properties of
camera arrays and non-central projection catadioptric systems. Initial
target applications include data acquisition for image-based rendering and
3D scene reconstruction. The main advantages of the proposed system include:
a relatively simple calibration procedure, a wide field of view, and a
single imaging sensor which eliminates the need for color calibration and
guarantees time synchronization.
Reconstructing a 3D Line from a Single Catadioptric Image
By Douglas Lanman, Megan Wachs, Gabriel Taubin and Fernando Cukierman
This paper demonstrates that, for axial non-central optical systems, the
equation of a 3D line can be estimated using only four points extracted from
a single image of the line. This result, which is a direct consequence of
the lack of vantage point, follows from a classic result in enumerative
geometry: there are exactly two lines in 3-space which intersect four given
lines in general position. We present a simple algorithm to reconstruct the
equation of a 3D line from four image points. This algorithm is based on
computing the Singular Value Decomposition (SVD) of the matrix of Plucker
coordinates of the four corresponding rays. We evaluate the conditions for
which the reconstruction fails, such as when the four rays are nearly
coplanar. Preliminary experimental results using a spherical catadioptric
camera are presented. We conclude by discussing the limitations imposed by
poor calibration and numerical errors on the proposed reconstruction
algorithm.
Synchronization and Calibration of a Camera
Network for 3D Event Reconstruction from Live Video
Sudipta N. Sinha and Marc Pollefeys,
Department of Computer Science, UNC Chapel Hill
Existing algorithms for automatic 3D reconstruction of dynamic
scenes from multiple viewpoint video requires calibrated and
synchronized cameras. Our approach recovers all the necessary
information by analyzing the motion of the silhouettes in video.
This precludes the need for specific calibration data or a pre-calibration
phase. The first step consists of independently recovering the temporal
offset and epipolar geometry between different camera pairs using an
efficient RANSAC-based algorithm that randomly samples the 4D space
of epipoles and finds corresponding extremal frontier points on the
silhouettes.
In the next stage, the calibration and synchronization of the complete
camera
network is recovered. For unsynchronized video streams, silhouettes
interpolated
based on sub-frame temporal offsets produce more accurate visual hulls.
We demonstrate our approach on six different datasets acquired by computer
vision researchers. The datasets contain 4 to 25 viewpoints with these
cameras in
general configurations. We are currently exploring calibration of
projector-camera
systems and that of heterogeneous camera networks containing video
cameras, IR
and 3D depth sensors. We are also trying to deal with severe silhouette
extraction noise.
Poster: .ppt
References:
* S. Sinha, M. Pollefeys, Calibrating a network of cameras from live
or archived video, Advanced Concepts for Intelligent Vision
Systems, 2004. [pdf]
http://www.cs.unc.edu/%7Emarc/pubs/SinhaACIVS04.pdf
* S. Sinha, M. Pollefeys. Visual-Hull Reconstruction from
Uncalibrated and Unsynchronized Video Streams, Second
International Symposium on 3D Data Processing, Visualization &
Transmission, 2004. [pdf]
http://www.cs.unc.edu/%7Emarc/pubs/Sinha3DPVT04.pdf
* S. Sinha, M. Pollefeys. Synchronization and Calibration of Camera
Networks from Silhouettes, International Conference on Pattern
Recognition 2004. [pdf]
//www.cs.unc.edu/%7Emarc/pubs/SinhaICPR04.pdf
* S. Sinha, M. Pollefeys. Camera Network Calibration from Dynamic
Silhouettes, Proc. of IEEE Conf. on Computer Vision and Pattern
Recognition, 2004 (to appear). [pdf]
//www.cs.unc.edu/%7Emarc/pubs/SinhaCVPR04.pdf
3D city reconstruction using cognitive loops. (video)
Geert Caenen, KU Leuven
The video demonstrates how a 3D city reconstruction module devised by
the KULeuven is combined with a car recognition module devised by
ETHZurich so that each module feeds information to the other module,
allowing the combined system to overcome the weaknesses of each seperate
module. The implementation of such a cognitive loop between modules led
to a drastic increase in robustness, efficiency and accuracy of the
resulting 3D city model.
(received the Best Video Award at CVPR 2006)
Towards Urban 3D Reconstruction From Video
A. Akbarzadeh, C. Engels, M. Phelps, L. Wang, Q. Yang, H. Stewenius, R.
Yang, D. Nister
Center for Visualization and Virtual Environments, University of
Kentucky, Lexington.
J.-M. Frahm, P. Mordohai, B. Clipp, D. Gallup, P. Merrell, S.N. Sinha,
B. Talton,
G. Welch, H. Towles,and M. Pollefeys,
Department of Computer Science,
UNC Chapel Hill
The poster introduces a data collection system and a
processing pipeline for automatic geo-registered 3D
reconstruction of urban scenes from video. The system
collects multiple video streams, as well as GPS and INS
measurements in order to place the reconstructed models
in geo-registered coordinates. Besides high quality in terms
of both geometry and appearance, we aim at real-time
performance. Even though our processing pipeline is not yet real-time,
we have selected techniques and designed processing modules that can
achieve fast performance on multiple CPUs and GPUs aiming
at real-time performance in the near future. We present the main
considerations in
designing the system and the steps of the processing pipeline.
We show results on real video sequences captured by our system.
Reference:
A. Akbarzadeh, J.-M. Frahm, P. Mordohai, B. Clipp, C. Engels, D.
Gallup, P. Merrell, M. Phelps, S. Sinha, B. Talton, L. Wang, Q.
Yang, H. Stewenius, R. Yang, G. Welch, H. Towles, D. Nister and M.
Pollefeys, Towards Urban 3D Reconstruction From Video, Proc.
3DPVT'06 (Int. Symp. on 3D Data, Processing, Visualization and
Transmission), 2006.
Tue 8:30-10
Recognition
-
David Nistér, University of Kentucky
Recognition and 3D Reconstruction (25 min).
A recognition scheme that scales efficiently to a large
number of objects is presented. The efficiency and quality is
exhibited in a live demonstration that recognizes CD-covers
from a database of 50000 images of popular music CD's.
The scheme builds upon popular techniques of indexing
descriptors extracted from local regions, and is robust to
background clutter and occlusion. The local region descriptors
are hierarchically quantized in a vocabulary tree. The
vocabulary tree allows a larger and more discriminatory
vocabulary to be used efficiently, which we show experimentally
leads to a dramatic improvement in retrieval quality.
The most significant property of the scheme is that the tree
directly defines the quantization. The quantization and the
indexing are therefore fully integrated, essentially being one
and the same.
Slides: .pdf, .ppt
- Vincent Lepetit, EPFL
Keypoint recognition in ten lines of code (25 min).
While feature point recognition is a key component of modern
approaches to object detection, existing approaches require
computationally expensive patch preprocessing to handle perspective
distortion. We show that formulating the problem in a Naive Bayesian
classification framework makes such preprocessing unnecessary and
produces an algorithm that is simple, efficient, and
robust. Furthermore, it scales well to handle large number of classes.
To recognize the patches surrounding keypoints, our classifier uses
hundreds of simple binary features and models class posterior
probabilities. We make the problem computationally tractable by
assuming independence between arbitrary {\em sets} of features. Even
though this is not strictly true, we demonstrate that our classifier
nevertheless performs remarkably well on image datasets containing
very significant perspective changes.
We applied our classifier to real-time 3-D object detection and pose
estimation. It is trained online by slowly moving the target object
with respect to the camera. This is made possible by the great
flexibility of our classifier, which lets us add and remove feature
points to our list as needed with a minimum amount of extra
computation.
Slides: .pdf,
- Martin Bergtholdt, Mannheim University
Graphical Models for Visual Object Class Recognition (40 min).
We focus on learning graphical models for the appearance of object
classes from arbitrary instances and viewpoints with the objective of
recognizing unseen instances in unknown environments. Large
intra-class variability of object appearance is dealt with by
combining statistical local part detection and relations between
object parts in a probabilistic network.
We show how the model parameters for a specific object class are
learned from a set of labeled examples. Inference for view-based
object recognition is done exactly with $A^{\ast}$-search employing
novel and dedicated admissible heuristics, or approximately with
Belief Propagation, depending on the network size. The former approach
enables us to evaluate the performance of current approximate
inference algorithms from the viewpoint of combinatorial optimization.
Our approach is applicable to arbitrary object classes, including
articulated objects such as humans. Experiments on ``faces'' and
``articulated humans'' show performance equal or superior to dedicated
recognition approaches.
Slides: .pdf, .ppt
Tue 10:30-12
Learning/Textures
- Jim Rehg, Georgia Tech
Provisional (40 min): I am planning to talk about my groups work on cascaded detectors. We
have some new results for the learning problem for these cascades, and
I may be able to show some applications as well.
- M. Alex O. Vasilescu, MIT
Multilinear (Tensor) Algebraic Framework for Computer Vision and Graphics
Principal components analysis (PCA) is one of the most valuable results
from applied linear algebra. It is used ubiquitously in all forms of data
analysis -- in data mining, biometrics, psychometrics, chemometrics,
bioinformatics, computer vision, computer graphics, etc. This is because
it is a simple, non-parametric method for extracting relevant information
through the demensionality reduction of high-dimensional datasets in order
to reveal hidden underlying variables. PCA is a linear method, however,
and as such it has severe limitations when applied to real world data. We
are addressing this shortcoming via multilinear algebra, the algebra of
higher order tensors.
In the context of computer vision and graphics, we deal with natural
images which are the consequence of multiple factors related to scene
structure, illumination, and imaging. Multilinear algebra offers a potent
mathematical framework for explicitly dealing with multifactor image
datasets. I will present two multilinear models that learn (nonlinear)
manifold representations of image ensembles in which the multiple
constituent factors (or modes) are disentangled and analyzed explicitly.
Our nonlinear models are computed via a tensor decomposition, known as the
M-mode SVD, which is an extension to tensors of the conventional matrix
singular value decomposition (SVD), or through a generalization of
conventional (linear) ICA called Multilinear Independent Components
Analysis (MICA).
I will demonstrate the potency of our novel statistical learning approach
in the context of facial image biometrics, where the relevant factors
include different facial geometries, expressions, lighting conditions, and
viewpoints. When applied to the difficult problem of automated face
recognition, our multilinear representations, called TensorFaces (M-mode
PCA) and Independent TensorFaces (MICA), yields significantly improved
recognition rates relative to the standard PCA and ICA approaches.
Recognition is achieved with a novel Multilinear Projection Operator.
In computer graphics, our image-based rendering technique, called
TensorTextures, is a multilinear generative model that, from a sparse set
of example images of a surface, learns the interaction between viewpoint,
illumination and geometry, which determines surface appearance, including
complex details such as self-occlusion and self shadowing. Our tensor
algebraic framework is also applicable to human motion data in order to
extract "human motion signatures" that are useful in graphical animation
synthesis and motion recognition.
- Greg Mori
Simon Fraser University
On Human Pose Estimation
Slides:
.ppt
References:
Greg Mori and Jitendra Malik, Recovering 3d Human Body Configurations
Using Shape Contexts, IEEE Transactions on Pattern Analysis and Machine
Intelligence, 2006.
Greg Mori, Guiding Model Search Using Segmentation, IEEE International
Conference on Computer Vision, 2005.
G. Mori, X. Ren, A. Efros, and J. Malik, Recovering Human Body
Configurations: Combining Segmentation and Recognition, IEEE Computer
Vision and Pattern Recognition, 2004.
Tue 13:30-15:15
Human Motion 1
- Cristian Sminchisescu, University of Toronto
BM3E: Discriminative (and Generative) Methods for 3D Human Motion Analysis (40-60 min).
I will discuss learning and inference algorithms to estimate 3D human
motion in monocular video. This is difficult because the human body
has many degrees of freedom and because these are hard to observe due
to occlusion and depth ambiguities. While the problem has been
traditionally approached using the powerful machinery of generative
models, the main emphasis of this talk will be on an emerging class of
complementary discriminative temporal estimation models. These can be
viewed as up-side down, mirrored versions of the classical temporal
chains used with Kalman filtering or Condensation. But instead of
inverting a generative imaging model at runtime, we will learn to
cooperatively predict complex local image-to-state mappings, using
Conditional Bayesian Mixtures of Experts. These are embedded in a
probabilistic temporal framework in order to enforce dynamic
constraints and allow a principled propagation of uncertainty. We call
the resulting model BM^3E (a Conditional Bayesian Mixture of Experts
Markov Model). During the talk, I will also show how discriminative
inference can be efficiently restricted to low-dimensional, kernel
induced non-linear state spaces, and how the framework can be extended
in order to deal with clutter and occlusion. If time permits, I will
discuss the relative advantages of generative and discriminative
methods and ways to jointly learn them in automatic systems that
self-initialize and recover from failure.
Slides: .pdf
- Raquel Urtasun, MIT
Provisional: Gaussian Processes for Monocular 3D Person tracking (40-50 min).
We advocate the use of Gaussian Processes (GPs) to learn prior models of human
pose and motion for 3D person tracking. The Gaussian Process Latent variable
model (GPLVM) provides a low-dimensional embedding of the human pose, and
defines a density function that gives higher probability to poses close to the
training data. The Gaussian Process Dynamical Model (GPDM) provides also a
complex dynamical model in terms of another GP. With the use of Bayesian model
averaging both GPLVM and GPDM can be learned from relatively small amounts of
training data, and they generalize gracefully to motions outside the training
set. We show that such priors are effective for tracking a range of human
walking styles, despite weak and noisy image measurements and a very simple
image likelihood. Tracking is formulated in terms of a MAP estimator on short
sequences of poses within a sliding temporal window.
Tue 15:45-17:20
Human Motion 2
- David Fleet, University of Toronto
Provisional: Locomotion Dynamics for 3D People Tracking (30-40 min).
Kinematics models of human pose and motion, while extremely useful for
3D people tracking, do not always yield realistic movements, as they
do not neccessarily satisfy basic physical constraints. Two of the
most common problems during tracking concern balance and contact
dynamics. We introduce an approach to human tracking with prior
models of physics-based dynamics and kinematics. The model dynamics
is based largely on 2D passive-dynamic abstractions, and capture some
of the most important properties of human locomotion, including ground
contacts. With such models, we track walking people from monocular
video sequences; the current tracker uses an online sequential Monte
Carlo procedure to infer kinematic, dynamic and anthropometric state
variables. The tracker handles people walking straight and turning.
It also tolerates significant occlusions.
Slides: .pdf
- Phil Torr, Oxford Brookes University
Solving Markov Random Fields using Second Order Cone Programming Relaxations (40-60 min).
In this talk, I will present a generic method for solving Markov
random fields (MRF) by formulating the problem of MAP estimation as
0-1 quadratic programming (QP). In particular the focus will be on
estimating the best pose of pictorial structures, which well model
articulated structures such as humans. Though in general solving MRFs
is NP-hard, we propose a second order cone programming relaxation
scheme which solves a closely related (convex) approximation. In terms
of computational efficiency, our method significantly outperforms the
semidefinite relaxations that I previously proposed whilst providing
equally (or even more) accurate results. Unlike popular inference
schemes such as Belief Propagation and Graph Cuts, convergence is
guaranteed within a small number of iterations. Furthermore, we also
present a method for greatly reducing the runtime and increasing the
accuracy of our approach for a large and useful class of MRF. We
compare our approach with the state-of-the-art methods for subgraph
matching and object recognition and demonstrate significant
improvements.
Slides: .pdf, .ppt
References:
P. Kumar, P.H.S. Torr and A. Zisserman, "Solving Markov Random Fields
Using Second Order Cone Programming", In Proceedings IEEE Conference of
Computer Vision and Pattern Recognition, 2006 (poster).
P. Kohli and P.H.S. Torr. Efficiently Solving Dynamic Markov Random
Fields Using Graph Cuts. In IEEE Tenth International Conference on
Computer Vision 2005 (oral). (patent pending).
Tue 19-20:30
Banff New Media Inst tour
Tour of Banff New Media institute, including their arts studios, multimedia room,
immersive visualization "cave" etc.
Posters 2
Thu 9-12 AM Posters
Results of interaction: Artists/modelers will present what they produced
by combining computer vision captured models, tracked video etc in
their arts projects.
Second chance to see other posters as well.