Learning geometry from vision for
robotic manipulation
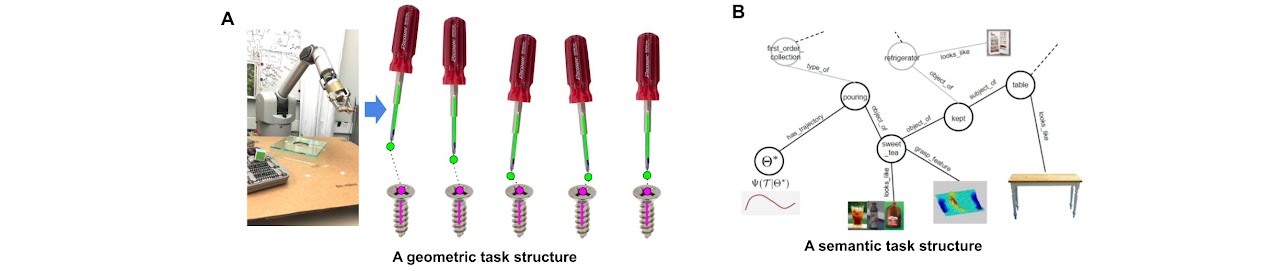
Fig. 1: Two types of task structures: (i) a geometric task structure (Fig. 1A) that we use; (ii) a semantic task structure[3] (Fig. 1B) that extract task semantic meanings by a tree or graph, which has been intensively studied [13, 14] in the literature.
This thesis studies how to enable a real-world robot to efficiently learn a new task by watching human demonstration videos. Learning by watching provides a more human-intuitive task teaching interface than methods requiring coordinates programming, reward/cost design, kinesthetic teaching, or teleoperation. However, challenges regarding massive human demonstrations, tedious data annotations or heavy training of a robot controller impede its acceptance in real-world applications. To overcome these challenges, we introduce a geometric task structure to the problem solution.
What is a geometric task structure?
A geometric task structure uses geometric features observed in image planes[1, 2] to specify a task by either explicitly forming geometric constraints or implicitly extracting task-relevant keypoints. For example, in figure 1A, a screwing task can be specified by points and lines constraints.
What new insights can it bring to us in robot learning?
It enables unsupervised learning from a few human demonstrations without tedious annotations. We propose Visual Geometric Skill Imitation Learning (VGS-IL) (our publication [4,5]), a method that uses a task function to learn the geometric task structure by extracting task-relevant image features to compose geometric constraints, thus forming an efficient and interpretable representation. The task function is optimized by Incremental Maximum Entropy Inverse Reinforcement Learning (InMaxEnt-IRL) (our publication [6]) based on “temporal-frame-orders” in human demonstration video.
It enables efficient transfer to a robot controller. Unlike prevalent methods that require intensive training on the robot when mapping the learned representation to robot actions, our proposed task function selects out geometric constraints with adjoint geometric errors that can be directly used in a conventional visual servoing controller or a UVS controller[7].
Furthermore, we show that introducing geometric task structure to the representation learning of “what is the task” enables task generalization. We devise Categorical Object Generalizable VGS-IL (CoVGS-IL) that uses a graph-structured task function to select out task-relevant image features on categorical objects with the same task functionality, thus fulfilling task generalization. The insight is “task specification correspondence” as shown in Fig. 2 below.
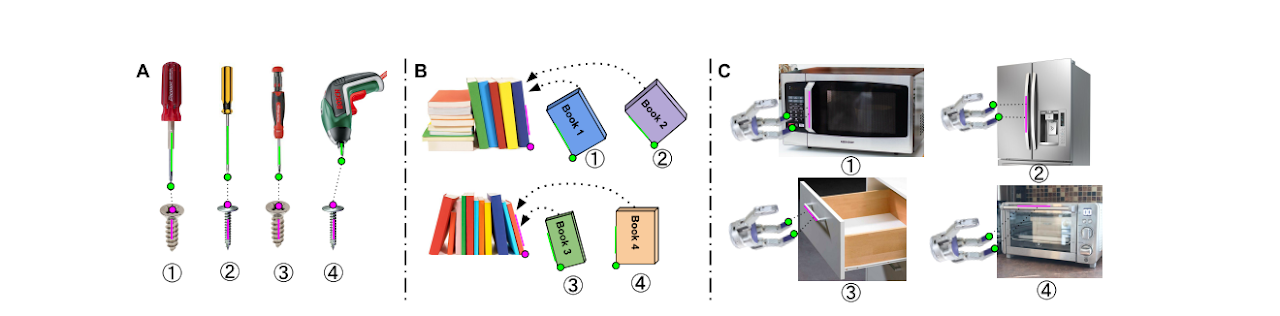
Fig. 2: The same geometric constraint from categorical objects defines the same task, which is called task specification correspondence. The affordance of object parts alone does not define any task. Beyond affordance, the interconnections between multiple object parts provide task specification, thus represents the task and can be used to build task specification correspondence.
How does this work relate to robot learning literature?
In addition to the "learning by watching" approaches, a.k.a., "third-person visual imitation learning"[12], our work also closely relates to methods that use task-relevant geometric features to boost up sample-efficient robot learning and task generalization (Fig. 3).
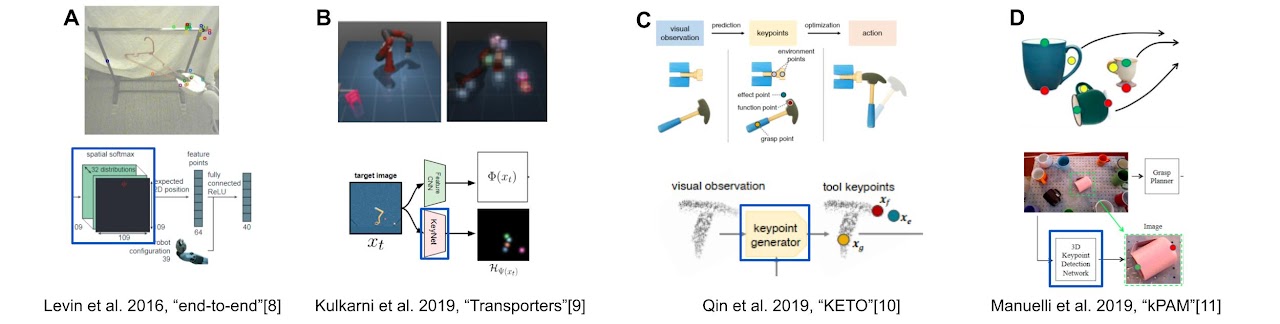
Fig. 3: Example of current researches using keypoint structures in robot learning. The top row shows the method, keypoint structures are extracted by modules marked with a blue block.
These researches motivate us to push from a simple intuition that “task-relevant keypoints should be good for robot learning” to a complete investigation on:
(1) “why are they good for robot learning”, “how do they relate to a task specification”, and “what about using geometric features other than points”.
(2) “how to avoid heavy training of a robot controller since geometric feature itself provides a virtual linkage to robot actions[1]”
(3) “why using geometric features will improve task generalization”.
This 8 min video uses a hammering task as an introductory demo for this research.
References
[1] François Chaumette. “Visual servoing using image features defined upon geometrical primitives.” In: Proceedings of 1994 33rd IEEE Conference on Decision and Control. Vol. 4. IEEE. 1994, pp. 3782–3787.
[2] Gregory D Hager and Zachary Dodds. “On specifying and performing visual tasks with qualitative object models.” In: Proceedings 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation.. Vol. 1. IEEE. 2000, pp. 636–643.
[3] Ashutosh Saxena et al. “Robobrain: Large-scale knowledge engine for robots.” In: arXiv preprint arXiv:1412.0691 (2014).
[4] Jun Jin et al. “Visual geometric skill inference by watching human demonstration.” In: 2020 IEEE International Conference on Robotics and Automation (ICRA) . IEEE. 2020, pp. 985–8991.
[5] Jun Jin et al. “A Geometric Perspective on Visual Imitation Learning.” In: 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) . IEEE. 2020, pp. 2655–2662.
[6] Jun Jin et al. “Robot eye-hand coordination learning by watching hu- man demonstrations: a task function approximation approach.” In: 2019 International Conference on Robotics and Automation (ICRA). IEEE. 2019, pp. 6624–6630.
[7] M. Jagersand, O. Fuentes, and R. Nelson. “Experimental evaluation of uncalibrated visual servoing for precision manipulation.” In: Proceedings of International Conference on Robotics and Automation 4.April (1997), pp. 2874–2880.
[8] Sergey Levine et al. “End-to-end training of deep visuomotor policies.”In: The Journal of Machine Learning Research 17.1 (2016), pp. 1334–1373.
[9] Kulkarni, Tejas D., et al. "Unsupervised Learning of Object Keypoints for Perception and Control." Advances in Neural Information Processing Systems 32 (2019): 10724-10734.
[10] Qin, Zengyi, et al. "Keto: Learning keypoint representations for tool manipulation." 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020.
[11] Lucas Manuelli et al. “kPAM: Keypoint affordances for category-level robotic manipulation.” International Symposium on Robotics Research (ISRR) 2019.
[12] Pratyusha Sharma, Deepak Pathak, and Abhinav Gupta. “Third-Person Visual Imitation Learning via Decoupled Hierarchical Controller.” In: Advances in Neural Information Processing Systems . 2019, pp. 2593– 2603.
[13] Daniel Leidner, Christoph Borst, and Gerd Hirzinger. “Things are made for what they are: Solving manipulation tasks by using functional object classes.” In: 2012 12th IEEE-RAS International Conference on Humanoid Robots (Humanoids 2012). IEEE. 2012, pp. 429–435.
[14] David Paulius and Yu Sun. “A survey of knowledge representation in service robotics.” In: Robotics and Autonomous Systems 118 (2019), pp. 13–30.