 +
+  =
= 

By contrast, in conventional modeling a so called 3D modeling program is used to build an object or scene by adding geometric primitives (e.g. lines, planes, spheres...) one-by-one in a fashion similar to how a 2D picture can be drawn in say Macdraw or xfig. There are several such modelers, e.g. Maya, 3D studiomax, Lightwave, Blender. The three first are commercial programs costing from thousands to ten thousand dollars. The last, Blender can be downloaded for free. Making detailed and realistic models by hand using a modeling program is very tedious and time consuming. In also difficult to ensure that the manually entered model is a faithful copy of the real heritage object.
Another way to capture 3D geometry of a real object is to use an active laser scanner. This falls into the general category of active 3D sensing, which also includes structured light, where a light pattern is projected on the object and mechanical sensing, where a touch probe is traced along object surfaces. Laser scanning is the most popular and accurate of these methods. There are two principles. For small and medium scale objects a triangulation based laser head is used. A line of laser light is beamed on the object and captured by a camera offset a distance. Depth is calculated from the resulting image curve. For large scale objects and scenes a time of flight laser is used, and the depth is calculated by measuring the time until a light pulse comes back from the surface. Either technology is quite expensive, with laser capture "heads" starting at $20,000 and whole capture systems often being in the $100,000's.
Laser scanning is mostly applied in industrial and engineering applications, where the high accuracy of the model is needed. Manual modeling is mostly used for movie special effects and computer games, where the complete creative freedom in model creation is most important. Both methods require rather large budgets and skilled users, and have therefore had little penetration in broader applications. An additional problem in using these methods for real world visual modeling is that they produce geometry only, and for photorealistic rendering photos of object appearance have to be separately (often manually) registered with the geometric models.
On the other end of the spectrum, so called structure-from-motion (SFM) methods in computer vision (which are similar to photogrammetry) compute an explicit geometry from camera images based on the identification of points in two or more images which correspond to the same physical 3D point. Then triangulation is used to determine the location of the 3D point. The main challenge here is that it is non-trivial to automatically and reliably find the corresponding points. Hence resulting models have relatively few points and the modeled geometry is at best a coarse representation for the real world object.
In shape-from-silhouette (SFS), instead of using corresponding points, a 3D shape is computed from the 2D image projection of an object silhouette in several images. When capturing objects we need to isolate or "segment" the object from the background, and in the process we get the silhouette. Practically this can be done with techniques from blue screening to background subtraction. The geometry computed with SFS is not in general the true object geometry, but an enveloping geometry called the visual hull. This is because not all object features are seen on the silhouette (for instance indentations in the object can hide detail). Yet, while the SFS model is only approximate it is easily and quickly computed, and therefore it is our method of choice for capturing object geometry.
In model capture, an input image sequence is decomposed into these two parts, the coarse geometry and the fine scale appearance basis. For rendering the 3D geometry is reprojected into a 2D image just as in regular graphics, but unlike regular graphics we don't texture (paint) the model with a static texture image. Instead an intuitive way to visualize the dynamic texture is that it plays a small movie on each model facet as the viewpoint of the rendering changes. The content of the movie is designed to hide the coarseness of the underlying geometric model.
+ =
Geometry + dynamic texture = photo-realistic rendering of novel views
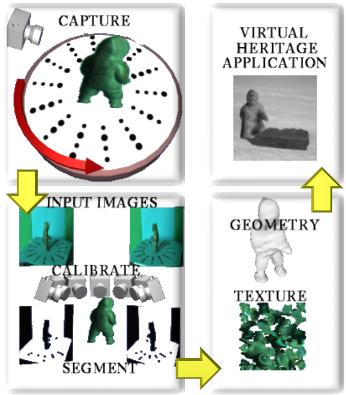 The process to acquire a digital model involves the following steps:
The process to acquire a digital model involves the following steps:
Model capture performed by University of Alberta's computer vision research group as a WISEST project involving two High School interns, Katie and Tammy, under the supervision of Cleo Espiritu and Martin Jagersand.
Site design, content and graphics by Cleo Espiritu
Software by Keith Yerex and Neil Birkbeck.
Maya modeler provided by Alias. (For which we wrote an image-based rendering plugin and used to render the videos and scene images)
Background music of the Hunt video: "Wind Dancing" by Soaring Eagle.
Seal hunt information taken from:
The Inuit
Aboriginal Innovations in Art, Science and Technology
Native Peoples and Cultures of Canada by Alan D. McMillan
Scared Hunt by David F. Pelly