
Explanation-based
learning (EBL) systems attempt to improve the performance of a problem
solver (PS), by first examining how PS solved previous problems, then modifying
PS to enable it to solve similar problems better (typically, more
efficiently) in the future. This article first motivates and explains
this explanation-based learning task, then discusses the challenges that
any EBL system must address, and presents several successful implementations.
It concludes by distinguishing this learning task from other types of learning.
 Many problem
solving tasks -- which here include diagnosis, classification, PLANNING,
scheduling and parsing (see also KNOWLEDGE-BASED SYSTEMS; NATURAL LANGUAGE
PROCESSING; CONSTRAINT SATISFACTION) -- are combinatorially difficult,
as they require finding a (possibly very long) sequence of rules to reduce
a given goal to a set of operational actions, or to a set of facts, etc.
Unfortunately, this can force a problem solving system (PS) to take a long
time to solve a problem. Fortunately, many problems are similar, which
means that information obtained from solving one problem may be useful
for solving subsequent, related problems. Some PSs therefore include an
"explanation-based learning" module (EBL) that learns from each solution:
After the basic problem-solving module has solved a specific problem, the
EBL module then modifies the solver (perhaps by changing its underlying
rule base, or by adding new control information), to produce a new solver
that is able to solve this problem, and related problems, more efficiently.
Many problem
solving tasks -- which here include diagnosis, classification, PLANNING,
scheduling and parsing (see also KNOWLEDGE-BASED SYSTEMS; NATURAL LANGUAGE
PROCESSING; CONSTRAINT SATISFACTION) -- are combinatorially difficult,
as they require finding a (possibly very long) sequence of rules to reduce
a given goal to a set of operational actions, or to a set of facts, etc.
Unfortunately, this can force a problem solving system (PS) to take a long
time to solve a problem. Fortunately, many problems are similar, which
means that information obtained from solving one problem may be useful
for solving subsequent, related problems. Some PSs therefore include an
"explanation-based learning" module (EBL) that learns from each solution:
After the basic problem-solving module has solved a specific problem, the
EBL module then modifies the solver (perhaps by changing its underlying
rule base, or by adding new control information), to produce a new solver
that is able to solve this problem, and related problems, more efficiently.
As a simple
example, given the information in the Prolog-style logic program
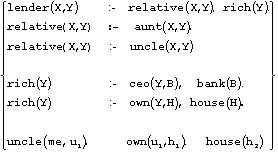
(where the first rule states that a person
Y may lend money to X if Y is a relative of X and Y is rich, etc., as well
as information about a house-owning uncle u1),
the PS would correctly classify u1 as a
lender -- i.e., return yes to the query lender(me, u1).
Most PSs
would have had to backtrack here; first asking if u1
was a relative as it was an aunt, and only when this subquery failed, then
asking whether u1 was an uncle; similarly,
to establish rich(u1), it would first see
whether u1 was the CEO of a bank before
backtracking to see if he owns a house. In general, PSs may have to backtrack
many times as they search through a combinatorial space of rules until
finding a sequence of rules that successfully reduces the given query to
a set of known facts.
While there
may be no way to avoid such searches the first time a query is posed (note
that many of these tasks are NP-hard; see COMPUTATIONAL COMPLEXITY), an
EBL module will try to modify the PS to help it avoid this search the second
time it encounters the same query, or one similar to it. As simply "caching"
or "memorizing" (Michie 1967) the particular conclusion -- here, uncle(me,
u1) -- would only help the solver if it
happens to encounter this exact query a second time, most EBL modules instead
incorporate more general information, perhaps by adding in a new rule that
directly encodes the fact that any uncle who owns a house is a lender;
i.e.,
lender(X, Y) :- uncle(X, Y), owns(Y,
H), house(H).
Many EBL systems would then store this
rule -- call it rnew -- in the front
of the PS's rule set, which means it will be the first rule considered
the next time a lender was sought. This would allow the modified solver
-- call it PS' -- to handle house-owning uncles in a single backward-chaining
step, without any backtracking.
Such EBL
modules first "explain" why u1 was a lender
by examining the derivation structure obtained for this query; hence the
name "explanation-based learning." Many such systems then "collapse" the
derivation structure of the motivating problem: directly connecting a variablized
form of the conclusion to the atomic facts used in its derivation. In general,
the antecedents of the new rule are the weakest set of conditions required
to establish the conclusion (here lender(X, Y)) in the context of the given
instance. The example itself was used to specify what information -- in
particular, which of the facts about me and u1
-- were required.
While the
new rnew rule is useful for queries
that deal with house-owning uncles, it will not help when dealing with
house-owning aunts or with CEO uncles. In fact, rnew
will be counter-productive for such queries, as the associated solver PS'
will have to first consider rnew
before going on to find the appropriate derivation. If only a trivial percentage
of the queries deal with house-owning uncles, then the performance of PS'
will be worse than the original problem solver, as PS' will take
longer, on average, to reach an answer. This degredation is called the
"utility problem" (Minton 1988; Tambe et al. 1990).
One way
to address this problem is to first estimate the distribution of queries
that will be posed, then evaluate the efficiency of a PS against that distribution
(Greiner and Orponen 1996; Segre et al. 1996; Cohen 1990; Zweben et al.
1992). (Note that this estimation process may require the EBL module to
examine more than a single example before modifying the solver.) The EBL
module can then decide whether to include a new rule, and if so, where
it should insert that rule. (Storing the rule in front of the rule set
may not be optimal, especially after other EBL-generated rules have already
been added.) As the latter task is unfortunately intractable (Greiner 1991),
many EBL systems involve hill-climbing to a local optimum (Greiner 1996;
Gratch and Dejong 1996; see GREEDY LOCAL SEARCH).
There are,
however, some implemented systems that have successfully addressed these
challenges. As examples, the Samuelsson and Rayner EBL module improved
the performance of a natural language parsing system by a factor of 3 (Samuelsson
and Rayner 1991); Zweben et al. (1992; resp. Gratch and Chien 1996) improved
the performance of their respective constraint-based scheduling system
by about 34% (resp., 50%) on realistic data.
Explanation-based
learning differs from typical MACHINE LEARNING tasks in several respects:
First, standard learners try to acquire new information, which the solver
can then use to solve problems that it could not solve previously; for
example, many INDUCTION learners learn a previously unknown classification
function, which can then be used to classify currently unclassified instances.
By contrast, a typical EBL module does not extend the set of problems that
the underlying solver could solve (Dietterich 1986); instead, its goal
is to help the solver to solve problems more efficiently. Stated another
way, explanation-based learning does not extend the deductive closure of
the information already known by the solver. Such knowledge-preserving
transformations can be critical, as they can turn correct, but inefficient-to-use
information (e.g., first-principles knowledge) into useful, efficient,
special-purpose expertise.
Of course,
the solver must know a great deal initially. There are other learning systems
that similarly exploit a body of known information, including work in INDUCTIVE
LOGIC PROGRAMMING (attempting to build an accurate deductive knowledge
base from examples; Muggleton 1992) and theory revision (modifying a given
initial knowledge base, to be more accurate over a set of examples; Ourston
and Mooney 1994; Wogulis and Pazzani 1993; Greiner 1997; Craw and Sleeman
1990). However, these other learning systems differ from EBL (and resemble
standard learning algorithms) by changing the deductive closure of the
initial theory (see DEDUCTIVE REASONING).
Finally,
most learners require a great number of training examples to be guaranteed
to learn effectively; by contrast, many EBL modules attempt to learn from
a single solved problem. As we saw above, this single "solved problem"
is in general very structured, and moreover, most recent EBL modules use
many samples to avoid the utility problem.
This article
has focused on EBL modules that add new (entailed) base-level rules to
a rule base. Other EBL modules, instead, try to speed up a performance
task by adding new control information, for example, which help the solver
to select the appropriate operator when performing a state space search,
etc. (Minton 1988). In general, EBL modules first detect characteristics
that make the search inefficient, and then incorporate this information
to avoid poor performance in future problems. Also, while our description
assumes the background theory is "perfect," there have been extensions
to deal with theories that are incomplete, intractable, or inconsistent
(Cohen 1992; Ourston 1991; DeJong 1997).
The rules
produced by an EBL module resemble the "macro-operators" built by the Abstrips
planning system (Fikes et al. 1972), as well as the "chunks" build by the
Soar system (Laird et al. 1986). (Note that Rosenbloom (Laird et al. 1986)
showed that this "chunking" can model the practice effects in humans.)
See also
EXPLANATION
KNOWLEDGE REPRESENTATION
PROBLEM SOLVING
-- Russell Greiner
REFERENCES
Cohen, W. W. (1990). Using distribution-free
learning theory to analyze chunking. Proceeding of CSCSI-90 17783.
Cohen, W. W. (1992). Abductive explanation-based
learning: a solution to the multiple inconsistent explanation problems.
Machine Learning 8(2): 167219.
Craw, S. and D. Sleeman. (1990). Automating
the refinement of knowledge-based systems. In L.C. Aiello (Ed.), Proceedings
of ECAI 90. Pitman.
DeJong, G. (1997). Explanation-base learning.
In A. Tucker (Ed.), The Computer Science and Engineering Handbook.
Boca Raton, FL: CRC Press, pp. 499520.
DeJong, G. and R. Mooney. (1986). Explanation-based
learning: an alternative view. Machine Learning 1(2): 14576.
Dietterich, T. G. (1986). Learning at the
knowledge level. Machine Learning 1(3): 287315. (Reprinted
in Readings in Machine Learning.)
Ellman, T. (1989). Explanation-base learning:
a survey of programs and perspectives. Computing Surveys 21(2):
163221.
Fikes, R., P. E. Hart, and N. J. Nilsson.
(1972). Learning and executing generalized robot plans. Artificial Intelligence
3: 251288.
Gratch, J. and S. Chien. (1996). Adaptive
problem-solving for large-scale scheduling problems: a case study. Journal
of Artificial Intelligence Research 4: 365396.
Gratch, J. and G. Dejong. (1996). A decision-theoretic
approach to adaptive problem solving. Artificial Intelligence 88(12):
365396.
Greiner, R. and P. Orponen. (1996). Probably
approximately optimal satisficing strategies. Artificial Intelligence
82(12): 2144.
Greiner, R. (1991). Finding the optimal
derivation strategy in a redundant knowledge base. Artificial Intelligence
50(1): 95116.
Greiner, R. (1996). PALO: A probabilistic
hill-climbing algorithm. Artificial Intelligence 83(12).
Greiner, R. (1998). The complexity of theory
revision. Artificial Intelligence to appear.
Laird, J. E., P. S. Rosenbloom, and A.
Newell. (1986). Universal Subgoaling and Chunking: The Automatic Generation
and Learning of Goal Hierarchies. Hingham, MA: Kluwer Academic Press.
Michie, D. (1967). Memo functions: a language
facility with 'rote learning' properties. Research Memorandum MIP-r-29,
Edinburgh: Department of Machine Intelligence and Perception.
Minton, S. (1988). Learning Search Control
Knowledge: An Explanation-Based Approach. Hingham, MA: Kluwer Academic
Publishers.
Mitchell, T. M., R. M. Keller, and S. T.
Kedar-Cabelli. (1986). Example-based generalization: a unifying view. Machine
Learning 1(1): 4780.
Muggleton, S.H. (1992). Inductive Logic
Programming. Academic Press.
Ourston, D. and R. J. Mooney. (1994). Theory
refinement combining analytical and empirical methods. Artificial Intelligence
66(2): 273310.
Samuelsson, C. and M. Rayner. (1991). Quantitative
evaluation of explanation-based learning as an optimization tool for a
large-scale natural language system. In Proceedings of the 12th International
Joint Conference on Artificial Intelligence. Morgan Kaufmann, pp.609615.
Segre, A. M., G.J. Gordon, and C.P. Elkan.
(1996). Exploratory analysis of speedup learning data using expectation
maximization. Artificial Intelligence
Tambe, M., A. Newell, and P. Rosenbloom.
(1990). The problem of expensive chunks and its solution by restricting
expressiveness. Machine Learning 5(3): 299348.
Wogulis, J. and M. J. Pazzani. (1993).
A methodology for evaluating theory revision systems: results with Audrey
II. Proceedings of IJCAI-93 11281134.
Zweben, M., E. Davis, B. Daun, E. Drascher,
M. Deale, and M. Eskey. (1992). Learning to improve constraint-based scheduling.
Artificial Intelligence 58: 271296.
Further Readings
DeJong, G. (1997). Explanation-based learning.
In A. Tucker (Ed.), The Computer Science and Engineering Handbook.
Boca Raton, FL: CRC Press, pp. 499520.
DeJong, G. and R. Mooney. (1986). Explanation-based
learning: an alternative view. Machine Learning 1(2): 14576.
Ellman, T. (1989). Explanation-base learning:
a survey of programs and perspectives. Computing Surveys 21(2):
163221.
Minton, S., J. Carbonell, C.A. Knoblock,
D.R. Kuokka, O. Etzioni and Y. Gil. (1989). Explanation-based learning:
a problem solving perspective. Artificial Intelligence 40(13):
63119.
Mitchell, T. M., R. M. Keller, and S. T.
Kedar-Cabelli. (1986). Example-based generalization: a unifying view. Machine
Learning 1(1): 4780.
