In many classification tasks, naive Bayes is either competitive with, or is, the best Bayesian-nets model... which is surprising, given that the naive Bayes model is so trivial that it essentially ignores dependencies between features! This seems to be an argument against structure learning, until one realizes that most structure learning methods are trying to model the joint distribution, which does not necessarily corresponds to a good estimate of the class-conditional distribution.
Tree-Augmented Naive Bayes (TAN) is a model that attempts to
optimize this
class conditional distribution;
augmenting naive Bayes by adding arcs between features such
that each feature has as its parents the class node, and (at most) one
other feature. (If you remove the Class node, the remaining
feature-feature arcs form a tree
structure.)
The following is an example of a TAN model.
(Note that the graph on only the evidence variables (W, X, Y, Z) forms
a
tree.)
The algorithm for learning TAN models is a variant of the Chow-Liu algorithm for learning tree-structured Bayes nets. Let C represent the class variable, and {Xi}i=1n be the features (non-class variables).
- Compute the conditional mutual information given C between
each pair of
distinct
variables,
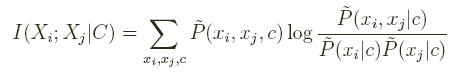
where P(.) is the empirical distribution, computed from the training data. Intuitively, this quantity represents the gain in information by adding Xi as a parent of Xj given that C is already a parent of Xj. - Build a complete undirected graph on the features {X1, ..., Xn}, where the weight of the edge between Xi and, Xj is I(Xi; Xj | C). Call this graph GF.
- Find a maximum weighted spanning tree on GF;
Call it TF.
(You can use Kruskal's or Prim's algorithm here.) - Pick an arbitrary node in TF as the root, and set the direction of all the edges in TF to be outward from the root. Call the directed tree T'F. (Hint: Use DFS.)
- The structure of the TAN model consists of a naive Bayes model on {C, X1, ..., Xn}, augmented by the edges in T'F.
(a: 15 points) Implement the above algorithm for learning the structure of a TAN model, and submit your code as tanstruct.m.
(b: 5 points)
Here, we consider the task of breast cancer typing --
that is, classifying a tumor as either malignant or benign;
see breast.csv within
zip file.
Learn a TAN structure for this data,
and draw the structure (directed acyclic graph) produced in your
writeup.
(c: 10 points) Classification
In this question you will compare the classification accuracy of naive
Bayes and TAN.
First, randomly withhold 183 records as a test set. Then, using a
training set of size m, for m = 100, 200, 300, 400, 500, ...
(You may want to consider several such sets.)
- Learn the structure of a TAN model and estimate each
parameter, corresponding to P(xi |Pai),
using the following smoothing estimator:
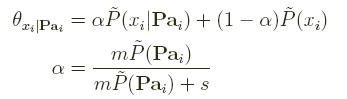
where s is a smoothing parmeter; here, use s = 5. This is known as "back-off" smoothing. - Learn a naive Bayes model , and estimate the parameters using back-off smoothing.
- Compare the classification accuracy of naive Bayes and TAN on the test set. Plot the classification error as a function of the number of training samples in your writeup. Submit the code used to run these experiments as tancompare.m.
Consider a factor produced as a product of some of the CPDs in a Bayesian network B:
-
ν(W) = ∏ik P( Yi
| PaYi )
(a: 5 points) Show that ν is a conditional probability in some network. More precisely, construct another Bayesian network B' and a disjoint partition W = Y ∪ Z such that ν(W) = PB'( Y | Z ).
(b: 5 points) Show that the intermediate factors produced by the variable elimination algorithm are also conditional probabilities in some network.
-
[10 points] Markov Networks & Factorization
Consider a distribution P over four binary random variables {X1, X2,, X3, X4} that assigns probability 1/8 to each of the following eight configurations:(0,0,0,0) (1,0,0,0) (1,1,0,0) (1,1,1,0)
(0,0,0,1) (0,0,1,1) (0,1,1,1) (1,1,1,1)and probability 0 to the other 8 configurations.
The distribution P satisfies the global Markov property with respect to the graph H = {X1 - X2 - X3 - X4 - X1}. (Note this graph is a circle.) For example, consider the independence claim (X1⊥X3|X2,X4). For the assignment X2 = x21, X4 = x40, we have that only assignments where X1 = x11 receive positive probability. Thus, P(x11|x21, x40) = 1, and X1 is trivially independent of X3 in the conditional distribution. A similar analysis applies to all other cases, so that the global Markov assumptions hold. However, the distribution P does not factorize according to H. Give a proof of this. (Hint: Use a proof by contradiction.)
- [10 points] K&F Exercise 4.10
Complete the proof of Theorem 4.3.13 . Assume that Eq. (4.2) holds for all disjoint sets X,Y, Z with |Z|≥ k:-
sepH(X; Y | Z) ⇒ P |= (X ⊥ Y | Z)
- [10 points] K&F Exercise 4.19
Let G be a Bayesian network structure and H a Markov network structure over X such that the skeleton of G is precisely H. Prove that if G has no immoralities, then I(G)=I(H).
(a: 5 points) Moralize this Bayesian network.
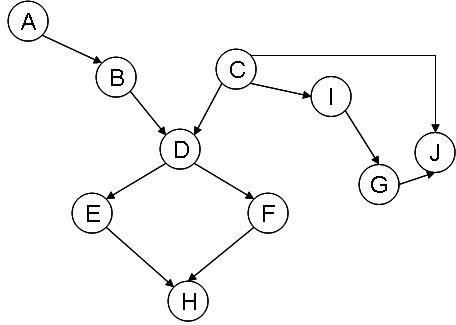
(b: 5 points) Build a cluster graph for this Bayesian net, and determine the message passing scheme and initial potential of each cluster (use a cluster that contains variable "C" in it as the root).
(c: 15 points) Matlab implementation: Use the Lauritzen-Spiegelhalter algorithm to calibrate the cluster tree associated with the Naive-Bayes model below. Submit your code as ctreecalibrate.m.
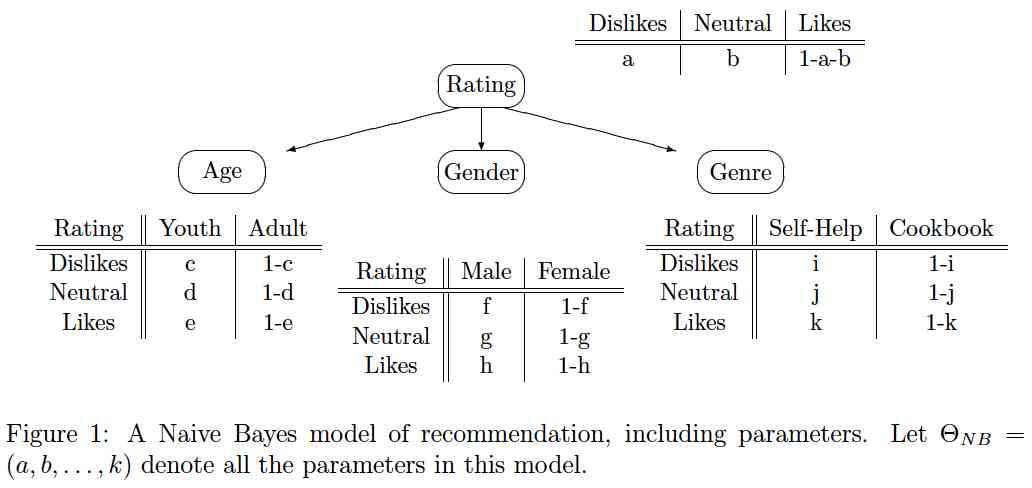
(d: 5 points)
Answer the following queries using the calibrated cluster tree.
Use values for the Bayes model parameters as follows:
[a=.25, b=.5, c=.65, d=.55, e=.4, f=.4, g=.5, h=.3, i=.8, j=.4, k=.5].
- P( Rating = Likes | Age = Youth, Genre = Cookbook )
- P( Genre = Cookbook | Gender = Male )
- P( Age = Adult | Genre = Self-Help )
- [20 points] Cluster Graphs and Inference - Programming
(a: 5 points) Consider the following pairwise Markov network.
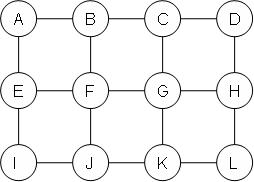
For this network:
i. Construct a clique tree with the minimal number of variables per cluster.
ii. Construct a generalized cluster graph with the minimal number of variables per cluster.
(b: 15 points) Matlab implementation: Consider the following Markov net and the corresponding cluster graph.
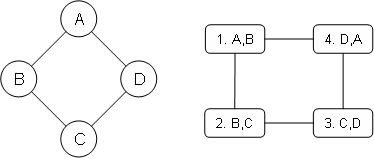
Each of the factors in this net has been assigned to one of the clusters, e.g. a(f1(A,B))=C1. Suppose all variables are binary and all factors all equal, i.e.:
i. Implement Belief-Update message passing algorithm on the above loopy cluster graph.
f1(A+,B+) = f2(B+,C+) = f3(C+,D+) = f4(D+,A+) = a
f1(A+,B-) = f2(B+,C-) = f3(C+,D-) = f4(D+,A-) = b
f1(A-,B+) = f2(B-,C+) = f3(C-,D+) = f4(D-,A+) = c
f1(A-,B-) = f2(B-,C-) = f3(C-,D-) = f4(D-,A-) = d
Note: You should be able to re-use a lot of the code you built for Part c of the Clique Trees problem above.
ii. For each of the following cases, compare the true value of P(A+) with the value obtained from loopy belief propagation. Plot the value of P(A+) for each case.
-
1. (a,b,c,d) = (10,1,5,2)
2. (a,b,c,d) = (10,10,2,1)
3. (a,b,c,d) = (10,2,10,1)
4. (a,b,c,d) = (10,1,1,10)
5. (a,b,c,d) = (10,11,12,10) -
[Question removed - no time to cover Markov Network Approximations]
Submit your code for i and ii as mploopy.m