We have spoken about the efficiency of the various sorting algorithms, and it is time now to discuss the way in which the efficiency of sorting algorithms, and algorithms in general, is measured. This is called complexity analysis, and it is a very important and widely-studied subject in computer science. Our short introduction here touches only the surface of the subject: you are encouraged to study it further through textbooks devoted to the subject (there are many) or in-depth university courses.
Now you might say, it's obvious how to measure the efficiency of an algorithm. Just code up the algorithm as a program and run the program on some test data. Measure the execution time, or the memory required, and there you are. If you want to know if one algorithm is more efficient than another, do this for both of them and compare the results.
Can anyone see any problems in measuring efficiency this way?

We have to decide which property of the input we are going to measure; the best choice is the property that most significantly affects the efficiency-factor we are trying to analyze. We will use the generic term size of the input to refer to the key property that will be used in the analysis. And we'll use the variable N to denote this property. By the way, it is not absolutely necessary to have just one property; we could express efficiency as a function of several properties. But it is most common to use just one, and we'll stick to examples where one is all that is needed.
For example, the time taken to sort a list is invariably a function of the length of the list. The sorting algorithms you meet in first year are typically quadratic functions - TIME(N) = N*N (roughly). MergeSort and QuickSort are faster: for them TIME(N) = N*log(N) (roughly), which is less than quadratic, but greater than linear in the length of the list.

This does not entirely answer problem (2). Consider an algorithm that searches through a list looking for a specific value. Let's assume the value is always somewhere in the list, so the algorithm always succeeds. What are the factors affecting the speed with which this algorithm runs?
Answer: The position where the value is located.
If the algorithm happens to start at the location containing the value, the algorithm will finish very quickly. On the other hand, if the algorithm is `unlucky' it will try all other locations before getting to the right one!
So the function we're trying to draw is really a band: for an input of size N (e.g. length of a list), you get variation between two extremes, called the worst case behaviour and the best case behaviour.
In our searching example: best-case = constant time, worst-case = length of list (or is it one less than length - see below) The average-case is somewhere in between - exactly where depends on things beyond this course.
Now, when we go to compare two algorithms we are comparing two functions. One has to be careful, because functions can cross one another several times - if this happens it means that neither of the algorithms is better than the other on all possible inputs.
The technical definition of ballpark estimate is asymptotic complexity. With asymptotic complexity all we are interested in is the dominant term, in the limit, of the efficiency function.
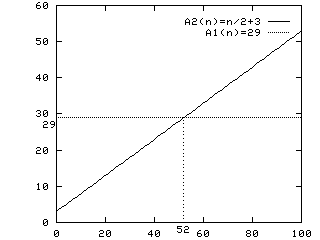
For example, suppose we have two algorithms:
Although for very short lists A2 is more efficient than A1, for all sufficiently large lists A1 is more efficient than A2. This is the idea asymptotic complexity captures.
Asymptotic complexity ignores all low-order terms, and all constant multipliers ... so all linear functions are written O(N), all constant time functions O(1).
The asymptotic complexity of A1 is O(1), of A2 is O(N).
Big-O is read ``order of''
Obviously, asymptotic complexity is only appropriate when you are dealing with big inputs. If, in your application, you know your inputs will be small you will have to do more careful analysis.

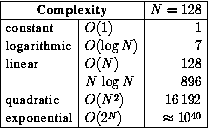
For example, the NlogN entry shows that MergeSort would do roughly 896 comparisons in sorting a list of length 128; for the same list, the number of comparisons done by Insertion Sort is given by the N*N entry, 16,192.
As you can see these are massive differences, so reducing the order of complexity is always a huge payoff (unlike most simple coding tricks).
What is wrong with the following: efficiency(N) = O(2N + logN)
Answer: With Big-O notation, we are strictly concerned with the dominant term, low-order terms and constant coefficients are ignored. The statement in the example ought to have been simplified to efficiency(N) = O(N).
![]()
![]()
![]()