# jemdoc: addcss{rbh.css}, addcss{jacob.css}
= AlphaGo
~~~
{}{raw}
cgo
oly
nets
evo
rsrcs
AG-FH
AG
AG-LS
DZ-CC
nat
input
slp
rlp
rlv
search
sims
tree
disc
~~~
~~~
{}{raw}
computer go
~~~
~~~
- the race to build a superhuman go-bot is over: AlphaGo won.
computer go research will continue mostly in the commercial world,
as developers (e.g. Coulom and Crazystone) bring
AlphaGo tech to market and, eventually, cell phones
- [http://senseis.xmp.net/?ComputerGo\#toc1 sensei's library: computer go]
- [http://computer-go.info/h-c/ human-computer go challenges]
- brief history
-- 2006: monte carlo tree search
-- pre-AlphaGo: top pros beat top programs + 3 stone handicap
-- 2015 AlphaGo - Fan Hui 2p ~ 5-0 (formal) ~ 3-2 (blitz)
-- 2016 AlphaGo - Lee Sedol korea 9p ~ 4-1
-- 2017 AlphaGo - Ke Jie (world number 1) china 9p ~ 3-0
-- 2017 AlphaGo retires
#-- [https://go.codecentric.de/ 2016 zen 19x v lukas kraemer 6d ~ 3-1]
- [http://webdocs.cs.ualberta.ca/~hayward/670gga/jem/go.html more computer go links]
~~~
~~~
{}{raw}
computer olympiad
~~~
~~~
- since 1989,
[https://en.wikipedia.org/wiki/Computer_Olympiad computer olympiad]
has been a main venue for computer-computer
board game competition. UAlberta groups have competed
in chess, checkers, othello,
[https://senseis.xmp.net/?ComputerOlympiad go],
hex, amazons and other games
#- 2005 Taipei ~ 19x19 go: Hand Talk, Go Intellect, Aya
- 2006 Turin ~ 19x19 gold Gnu Go ~ 9x9 gold Crazystone
#- 2007 Amsterdam ~ 19x19 go: mogo, crazystone, gnu go
- 2009 9x9 gold Fuego (UAlberta)
- 2008 to present, 11x11 hex gold MoHex (UAlberta)
~~~
~~~
{}{raw}
neural nets and image classification
~~~
~~~
- a neural net is a machine-constructed function.
you can learn more about neural nets
(and convolutional neural nets, the kind used in AlphaGo)
on [http://colah.github.io/ chris olah's blog]
- [https://en.wikipedia.org/wiki/Supervised_learning supervised learning]
is learning from (usually human-supplied) training data
- [https://www.google.ca/webhp?sourceid=kitten+images\#q=kitten+images
what are these?] ~ ~ how did recognize them? (hint: not by image classification)
- image classification is the process of learning
how to recognize pixel images of things (e.g. kittens)
- research in image classification works like this
-- humans gather large collections of human-labelled images
-- they then design an algorithm that distinguishes among
the different kinds of images (e.g. species of birds)
-- they train their algorithm, say a neural net,
by taking say 90\% of the images
-- they use the remaining 10\% of the images to test the accuracy of
their algorithm
-- [http://www.vision.caltech.edu/visipedia/papers/WelinderEtal10_CUB-200.pdf 200 bird image dataset]
- 2012 breakthrough [http://www.cs.toronto.edu/~fritz/absps/imagenet.pdf
krizhevsky sutskever hinton: imagenet classification with dcnns] ~
[https://blog.acolyer.org/2016/04/20/imagenet-classification-with-deep-convolutional-neural-networks/ explained]
#-- [https://www.youtube.com/watch?v=-P28LKWTzrI gpu programming vs cpu programming]
~~~
~~~
{}{raw}
AlphaGo evolution
~~~
~~~
- 2010 Deepmind, an AI company, founded by Demis Hassabis (CEO) and 2 others.
- 2013 David Silver full-time head of reinforcement learning
(worked from startup as consultant)
- 2014 Deepmind bought by Google, reportedly for over $500 million
- can we use supervised learning and dcnns (deep cnns)
to predict expert go moves ?
- yes, Deepmind and independently U Edinburgh create go move-policy net
-- 2015 feb [https://chrisc36.github.io/deep-go/ training dcnns to play go] storkey clark
-- 2014 dec [https://arxiv.org/abs/1412.6564 move evaluation in go using dcnns] maddison huang sutskever silver
- 2015 oct secret match AlphaGo-Fan Hui 5-0
- 2016 jan
[http://webdocs.cs.ualberta.ca/~hayward/396/masteringgameofgo.pdf nature paper]
- 2016 mar AlphaGo-Lee Sedol 4-1
- 2017 jan-feb 60 anonymous AlphaGo Master online games
- 2017 mar AlphaGo-Ke Jie 3-0
- 2017 oct
[http://webdocs.cs.ualberta.ca/~hayward/396/agz_unformatted_nature.pdf AlphaGo Zero nature paper]
- 2017 dec [https://arxiv.org/pdf/1712.01815.pdf AlphaZero] self-learns Go, chess, shogi (Japanese chess)
-- [https://www.youtube.com/watch?v=lFXJWPhDsSY analysis of an AlphaZero chess game]
-- 2017-12-06 [https://www.chess.com/news/view/google-s-alphazero-destroys-stockfish-in-100-game-match AZ-Stockfish 28-72-0] ~ ~ but did Stockfish have same resources as AZ ?
- [http://science.sciencemag.org/content/362/6419/1140 AlphaZero paper in Science]
-- [http://science.sciencemag.org/content/362/6419/1140 Kasparov intro]
-- [http://science.sciencemag.org/content/362/6419/1140 Campbell intro]
~~~
~~~
{}{raw}
deepmind AlphaGo resources
~~~
~~~
- [https://deepmind.com/research/AlphaGo/match-archive/AlphaGo-games-english/ AG-LS 4-1
(FH commentary)]
- [https://deepmind.com/research/AlphaGo/match-archive/master/ AG-various pros 60-0 (online, 3x20s byoyomi)]
- [https://deepmind.com/research/AlphaGo/AlphaGo-matches-from-the-future-of-go-summit/ AG-KJ 3-0]
- [https://deepmind.com/research/AlphaGo/AlphaGo-vs-AlphaGo-self-play-games/ post AG-KJ, 50 AG-AG games]
- [https://AlphaGoteach.deepmind.com/ AG teach] with AG est. B winrate after 10 000 000 simulations
- [http://www.alphago-games.com/ all AG games]
- [https://deepmind.com/research/alphago/alphazero-resources/ AZ resources]
~~~
~~~
{}{raw}
AlphaGo - Fan Hui 5-0 (and 3-2)
~~~
~~~
- secret match AG-[https://en.wikipedia.org/wiki/Fan_Hui Fan Hui] (2p euro go champion)
- formal games (each 2 hr + 3x60s byoyomi) [http://www.alphago-games.com/\#fanhui AG-FH 5-0]
- informal games (3x60s byoyomi) AlphaGo v Fan Hui 3-2
- [https://www.youtube.com/watch?v=NHRHUHW6HQE myungwan kim commentary]
~~~
~~~
{}{raw}
AlphaGo ! (nature paper)
~~~
~~~
- [http://webdocs.cs.ualberta.ca/~hayward/396/masteringgameofgo.pdf nature paper]
~~~
~~~
{}{raw}
AlphaGo - Lee Sedol 4-1
~~~
~~~
- [https://deepmind.com/research/AlphaGo/AlphaGo-games-english/ Fan Hui match commentary] ~ [http://deeplearningskysthelimit.blogspot.ca/2016/03/lee-sedol-defeated-by-deep-learning.html postmatch analysis] ~ [https://www.youtube.com/watch?v=V0-IWQ9TvLo&t=1545s ecg2016 Fan Hui talk]
- exercise: use AG-teach (above) to analyze AG-LS game 1 (above, all AG games)
- [https://www.youtube.com/watch?v=mzpW10DPHeQ match 5-Garlock-Redmond 9p] ~
[https://www.youtube.com/watch?v=5Zs--5fEV9o AGA-Jackson-KimMyungwan 9p] ~
[https://web.archive.org/web/20160517104724/https://gogameguru.com/alphago-defeats-lee-sedol-4-1/ gogameguru] ~
- [https://www.youtube.com/watch?v=yCALyQRN3hw match 4] ~
[https://www.youtube.com/watch?v=SMqjGNqfU6I AGA] ~
[https://web.archive.org/web/20160517094944/https://gogameguru.com/lee-sedol-defeats-alphago-masterful-comeback-game-4/ gogameguru] ~
[https://massgoblog.wordpress.com/2016/03/15/before-game-5/ Li Zhe 6p]
- [https://www.youtube.com/watch?v=qUAmTYHEyM8 match 3] ~
[https://www.youtube.com/watch?v=CkyVB4Nm9ac AGA-ChoHyeyeon]
[https://www.youtube.com/watch?v=MnFXNyuLwRo part2] ~
[https://web.archive.org/web/20160516213118/https://gogameguru.com/alphago-shows-true-strength-3rd-victory-lee-sedol/ gogameguru]
- [https://www.youtube.com/watch?v=l-GsfyVCBu0 match 2] ~
[https://www.youtube.com/watch?v=EitoPhtGWJQ AGA] ~
[https://web.archive.org/web/20160516213118/https://gogameguru.com/AlphaGo-races-ahead-2-0-lee-sedol/ gogameguru]
[https://massgoblog.wordpress.com/2016/03/11/game-2-a-nobody-could-have-done-a-better-job-than-lee-sedol/ Li Zhe]
- [https://www.youtube.com/watch?v=vFr3K2DORc8 match 1] ~
[https://www.youtube.com/watch?v=YZPKR7HzM_s AGA] ~
[https://web.archive.org/web/20160516213118/https://gogameguru.com/AlphaGo-defeats-lee-sedol-game-1/ gogameguru] ~
[https://massgoblog.wordpress.com/2016/03/11/lee-sedols-strategy-and-AlphaGos-weakness/ Li Zhe]
- [http://imgur.com/a/29mOG AlphaGo scores] ~
[https://www.reddit.com/r/baduk/comments/4cgitz/AlphaGos_confidence_chart_for_the_5_games_david/ reddit] ~ [http://zhuanlan.zhihu.com/yuandong/20639694 darkforest scores matches 1,2]
- [https://www.youtube.com/watch?v=482sitMhspo haylee]
- [https://www.youtube.com/watch?v=X4OiR48wG70&feature=youtu.be korean documentary]
~~~
~~~
{what did we learn ?}
- game 1, move 7
-- LS tries to throw off AG, backfires
-- AG flexible, solid
- game 2, move 37
-- cigarette break, shoulder hit
-- AG beyond human
- game 3: AG move 14 unusual, LS reply over-agressive
-- AG winrate .59 (move 28) .62 (move 32) .72 (move 48) .74 (move 54)
-- AG has no problem with ko.
-- LS 77 wild, AG winrate .84 (move 84)
-- LS resigns after move 176
-- AG superhuman, does whatever works best
- game 4, AG builds big moyo
-- LS miracle move 78 (he saw that all other moves lose)
-- AG did not expect this move, in trouble by move 85
-- LS in byoyomi by move 103 but clearly winning: can he hang on? ~ yes!
-- LS amazing, AG human
- game 5, LS in trouble by move 80
-- AG too strong
~~~
~~~
{}{raw}
2016 nov Deep Zen - Cho Chikun 1-2
~~~
~~~
- [http://senseis.xmp.net/?ZenGoProgram deep zen go] ~
[https://en.wikipedia.org/wiki/Cho_Chikun Cho Chikun] ~ (\#1 1979-87 ~ \#{{≤10}} -99, still active)
- [http://denou.jp/go/ DZ-CC] ~ [http://www.nicovideo.jp/ register]
- game 1 ~ CC-DZ 1-0 ~ [http://www.usgo.org/news/2016/11/cho-defeats-deep-zen-go-game-2-tonight-at-11/ aga] ~ [https://www.youtube.com/watch?v=QDVUXWKshC8 michael redmond + antti tormanen] ~ [https://www.youtube.com/watch?v=erUj3iO5ybg myungwan kim]
- game 2 ~ DZ-CC 1-0 ~ [http://www.usgo.org/news/2016/11/deep-zen-go-wins-game-2-final-game-tuesday-night/ aga] ~ [https://www.youtube.com/watch?v=A_f4ZYlPsLY redmond + tormanen] ~ [https://www.youtube.com/watch?v=hkRf3JDwfKc myungwan kim]
- game 3 ~ CC-DZ 1-0 ~ [http://eidogo.com/\#ABYz5kZ1 sgf] ~ [https://www.youtube.com/watch?v=f4BOTi1cH50&index=3&list=PLZzBg_TlIYmFWhgBxfnEhmr5In1GJufWZ redmond \+ at] ~ [https://www.youtube.com/watch?v=0Nqp9V7Wwxc aj + myungwan kim]
- all games redmond [https://www.youtube.com/playlist?list=PLZzBg_TlIYmFWhgBxfnEhmr5In1GJufWZ at \+ redmond]
- deep zen
-- used a single $15K computer (requires 1-2 Kw power)
-- after game 1, multiplied available-time-per-move by 1.8
-- costs about $400 CAD
~~~
~~~
{common mcts flaw: optimistic simulations}
{{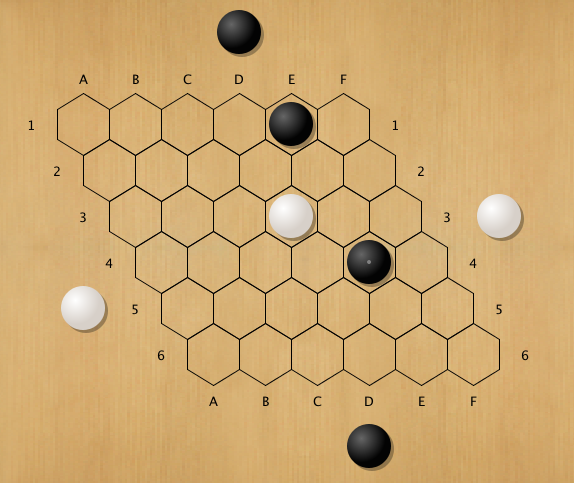 }}
- in games where winner often has narrow line of play, eg.
sequence with unique winning move(s),
randomized simulation often has wrong result
- eg. above hex position, white to play, who wins ?
- mohex, rave, 17500 simulations in tree, win rate .53, move d5
- d5 loses, all white moves lose: black wins
~~~
~~~
{end of game 3}
- among commercial go programs, zen has strong playouts (simulations)
- but zen's playouts missed Cho Chikun\'s best defensive sequences
- [http://eidogo.com/\#ABYz5kZ1 sgf]
- [https://www.advancedstudyroom.org/2016/11/3rd-game-3-cho-chikun-black-beats-deep-zen-go-white-overall-21/\#jp-carousel-20631 move 137 zen estimates this final position] ~ win rate .64 (mcts below .55 usually loses)
-- cell size shows prob. player owns cell at end
-- notice: zen estimates white has large group middle right
- but simulations are too optimistic: zen win rate drops
- white 156, 158 gain little: Cho Chikun guesses computer in trouble
- after 164, white win rate .48
- black 167: cut
- [https://www.youtube.com/watch?v=f4BOTi1cH50&index=3&list=PLZzBg_TlIYmFWhgBxfnEhmr5In1GJufWZ&t=3h36m10s white 168 zen operator Hideki Kato
places black stones captured by white on board: resign]
- after 167, middle right white group dead, black wins easily
~~~
~~~
{deep-zen-go vs cho-chikun game 3}{}
storkey-clark dcnn correctly-predicted next-moves
1 2 3 4 5 6 - - 9
- 11 12 - 14 15 16 - - 19
20 21 - 23 24 - 26 27 - -
30 31 - 33 34 35 36 - 38 -
40 41 42 - - 45 46 47 - 49
- 51 52 - 54 - - 57 - -
60 61 - 63 64 65 66 - - 69
70 71 - 73 74 75 76 - - -
- 81 82 83 - - - - - -
- - - - - - - - - -
- 101 102 - 104 - ...
~~~
~~~
{}{raw}
}}
- in games where winner often has narrow line of play, eg.
sequence with unique winning move(s),
randomized simulation often has wrong result
- eg. above hex position, white to play, who wins ?
- mohex, rave, 17500 simulations in tree, win rate .53, move d5
- d5 loses, all white moves lose: black wins
~~~
~~~
{end of game 3}
- among commercial go programs, zen has strong playouts (simulations)
- but zen's playouts missed Cho Chikun\'s best defensive sequences
- [http://eidogo.com/\#ABYz5kZ1 sgf]
- [https://www.advancedstudyroom.org/2016/11/3rd-game-3-cho-chikun-black-beats-deep-zen-go-white-overall-21/\#jp-carousel-20631 move 137 zen estimates this final position] ~ win rate .64 (mcts below .55 usually loses)
-- cell size shows prob. player owns cell at end
-- notice: zen estimates white has large group middle right
- but simulations are too optimistic: zen win rate drops
- white 156, 158 gain little: Cho Chikun guesses computer in trouble
- after 164, white win rate .48
- black 167: cut
- [https://www.youtube.com/watch?v=f4BOTi1cH50&index=3&list=PLZzBg_TlIYmFWhgBxfnEhmr5In1GJufWZ&t=3h36m10s white 168 zen operator Hideki Kato
places black stones captured by white on board: resign]
- after 167, middle right white group dead, black wins easily
~~~
~~~
{deep-zen-go vs cho-chikun game 3}{}
storkey-clark dcnn correctly-predicted next-moves
1 2 3 4 5 6 - - 9
- 11 12 - 14 15 16 - - 19
20 21 - 23 24 - 26 27 - -
30 31 - 33 34 35 36 - 38 -
40 41 42 - - 45 46 47 - 49
- 51 52 - 54 - - 57 - -
60 61 - 63 64 65 66 - - 69
70 71 - 73 74 75 76 - - -
- 81 82 83 - - - - - -
- - - - - - - - - -
- 101 102 - 104 - ...
~~~
~~~
{}{raw}
nature paper: details
~~~
~~~
- [https://applied-data.science/static/main/res/alpha_go_zero_cheat_sheet.png
cheatsheet]
- [https://storage.googleapis.com/deepmind-media/AlphaGo/AlphaGoNaturePaper.pdf AlphaGo nature paper pdf]
- go is a game of perfect information, so solving is easy:
traverse the game tree
- problem: depth \~ 150 ~ breadth \~ 250 ~ search space \~ 10\*\*360
- number atoms in observable universe \~ 10\*\*80
- idea: reduce search space ~ truncate tree at depth d,
for subtree s, replace true v*(s) with v'(s)
- idea: reduce breadth ~ sample actions from policy p(a|s) that is prob. dist. over moves a from s
- this sampling is what mcts does
- big improvement in image classification using dcnn:
use many layers of neurons, each arranged in overlapping tiles, to represent image
- AlphaGo: use neural nets to evaluate positions ~ value net
- AlphaGo: use neural nets to estimate p(a|s) ~ policy net
- AlphaGo network training pipeline
-- start with 29 400 000 positions from 160 000 KGS games, train supervised learning policy net
-- result: strong policy net
-- also train a fast (weaker) policy net
-- train a value net
-- combine fast policy net and value net with mcts
~~~
~~~
{}{raw}
~~~
~~~
- cell: player ~ opponent ~ empty
- liberties
- capture size
- self-atari size
- liberties after move
- ladder capture
- ladder escape
- legal and does not fill own eye
~~~
~~~
{}{raw}
policy nets (deep, shallow) via supervised learning
~~~
~~~
- [https://en.wikipedia.org/wiki/Supervised_learning supervised learning]
- goal here: using human data and sl, create a policy net
-- for arbitrary state s and all possible actions a, deep convolution neural net that estimates function f = prob(a|s)
-- input: board position s
-- output: from s, for each empty cell a, probability (from the human data)
that human selects action a
- how dcnn accuracy is measured
-- fraction of human record data is withheld from training, used for testing
- human data: 30 000 000 game positions from 160 000 KGS games
- improvement: when input is board position + above features, function is more accurate
- SL policy net accuracy:
-- \.557 (board input)
-- \.57 (board + features input)
~~~
~~~
{}{table}{policy nets}
net | response time {{(10-6 s)}} | response accuracy ||
deep | 3 000 | .57 ||
shallow | 2 | .24
~~~
~~~
{}{raw}
strengthen policy net via reinforcement learning
~~~
~~~
- [https://en.wikipedia.org/wiki/Reinforcement_learning reinforcement learning]
- observation: a move that clearly leads to a loss is not likely to be played
- so adding information about whether move leads to loss should
make dcnn more accurate
- improvement: starting from SL policy net, train a new neural
net using reinforcement learning
-- for each move, self-play game to end, find result
-- move that leads to win gets reward 1
-- move that leads to loss gets reward -1
- RL dcnn is similar architecture to SL dcnn (1 extra final layer)
- weights of RL dcnn initialized to final weights of SL dcnn
- reinforcement learning then trains RL dcnn to find final weights
- RL policy net ~ v ~ SL policy net ~ ~ winrate ~ .8
~~~
~~~
{}{raw}
from RL policy net to RL value net
~~~
~~~
- policy net estimates probability of making a move
- so ranks children, but cannot rank non-siblings
- for tree search (eg. minimax, mcts, ...)
need to be able to compare non-siblings
- need, for each node, an estimate of value:
what is the probability that a given move *wins* ?
-- for arbitrary state s, deep convolution neural net estimates v(s) =
prob(s is winning position)
-- input: board position s
- problem: using 30 000 000 game positions from only 160 000 games
leads to overfitting
-- value net learns to mimic move sequences in 160 000 games,
but plays poorly in other games
-- solution: use 30 000 000 game positions from 30 000 000 self-play data-set games
- RL value net will be used at leaf nodes of tree search
- MCTS will also be used at leaf nodes of tree search
- one RL value net call comparable in accuracy to about t MCTS simulations
using the fast RL policy net,
but requires 15 000 times less computation time
~~~
~~~
{}{raw}
AlphaGo search: integrate policy / value nets into MCTS
~~~
~~~
- each edge (s,a) stores action value Q(s,a) from policy net,
visit count N(s,a), prior probability P(s,a)
- bonus u(s,a) proportional to P(s,a) / (1 + N(s,a))
- use argmax ( Q(s_t,a) + u(s_t,a) ) for child selection
- at leaf, expand if number of visits exceeds a threshold
- at leaf, evaluate using simulation *and* using value net
(mixed ratio .5 .5 is best)
- after simulation, backup as usual, update N(s,a), update Q(s,a)
- when time is up, pick root child with most visits as move
- *surprise*
-- SL policy net works better in MCTS than stronger RL policy net, presumably because humans select a diverse beam of promising moves to explore, whereas RL optimizes for single best move
-- RL value net (derived from RL policy net) works better in AlphaGo than
similar value net derived from SL policy net
- evaluating policy / value nets is slow, so
-- use asynchronous multi-threaded search
-- use CPUs for simulation
-- use GPUs for policy / value net calls
- AlphaGo specs
-- single-machine: 40 search threads, 48 CPUs, 8 GPUs
-- distributed: 40 search threads, 1202 CPUs, 176 GPUs
~~~
~~~
{}{raw}
simulations
~~~
~~~
- like RAVE, but more general (used also in Crazystone and Erica)
-- each move (and est. win prob) in tree is cached
-- simulations use these cache moves/probs
- RAVE uses these probs only for children of each node on path to root
~~~
~~~
{simulation policy features}
- response ~ ( 1 pattern )
- save atari ~ ( 1 )
- neighbour to previous move ~ ( 8 )
- nakade (inside move) ~ ( 8192 )
- response pattern (12-point diamond around prev move) ~ ( 32207 )
- non-response pattern (8-points around cell) ~ ( 69338 )
~~~
~~~
{nakade example}{}
if x group has no outside liberties ,
where should x/o play ?
x x x x x
x - - - x
x x x x x
~~~
~~~
{}{raw}
tree policy features
~~~
~~~
- all simulation policy features plus ...
- self-atari ~ ( 1 ) ~ moves allows stone to be captured
- last move distance ~ ( 34 ) ~ manhattan distance to previous 2 moves
- non-response pattern ~ ( 32207 )
~~~
#~~~
#{}{raw}
#AlphaGo strength
#~~~
#
#~~~
#- tournaments with different versions, also Zen Crazystone Pachi Fuego Gnugo, 5s/move
#- no handicap ~ AlphaGo win rate .998
#- 4 stone handicap ~ AlphaGo win rate .77 .86 .99 1 ~ v ~ C Z P F
#- dist alphgo v ~ AlphaGo C Z P F ~ win rate ~ .77 1 1 1 1
#- mixed ratio (sims, value net) .5 .5 v other variants win rate .95
#-- suggests sims, value net provide complementary info
#- distributed AlphaGo ~ v ~ Fan Hui 2p ~ Oct 2015 ~ 5-0 formal games
#(each player 1 h + 3 x 30s byoyomi) and 3-2 (3 x 30s byoyomi)
#~~~
~~~
{}{raw}
discussion
~~~
~~~
- in Fan Hui match, AlphaGo looked at thousands times fewer / second
positions than DeepBlue-Kasparov ~ but ...
-- picked positions more wisely, using policy net and mcts
-- evaluated positions more accurately, using value net and sims
- DeepBlue used handcrafted eval function
- AlphaGo used neural nets trained using general-purpose
supervised/reinforcement learning methods
- AlphaGo trained with no-suicide Tromp-Taylor rules
(close to Chinese rules), komi 7.5
-- changing komi or rule-set would require retraining all its neural nets
- AlphaGo uses no RAVE, no progressive widening, no dynamic komi,
no opening book
~~~
~~~
{not mentioned in paper}
- AlphaGo time management policy found by ad hoc selfplay machine learning
- AlphaGo ponders (thinks during own and opponent's clock time)
- in Lee Sedol match
-- AlphaGo time per move close to constant
-- LS often behind on time (compared to AG)
-- AG pondering exaggerated this effect, putting LS under more time pressure
-- 9-dan pros like LS used to playing with little time
~~~