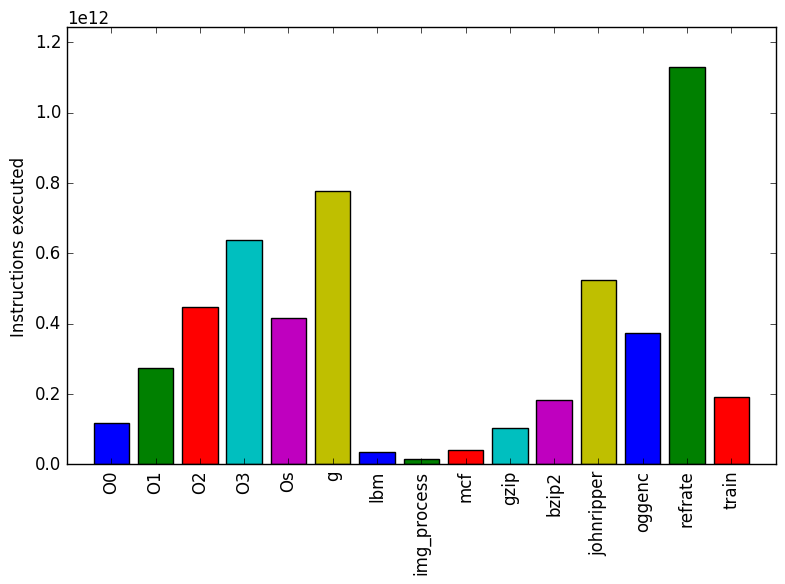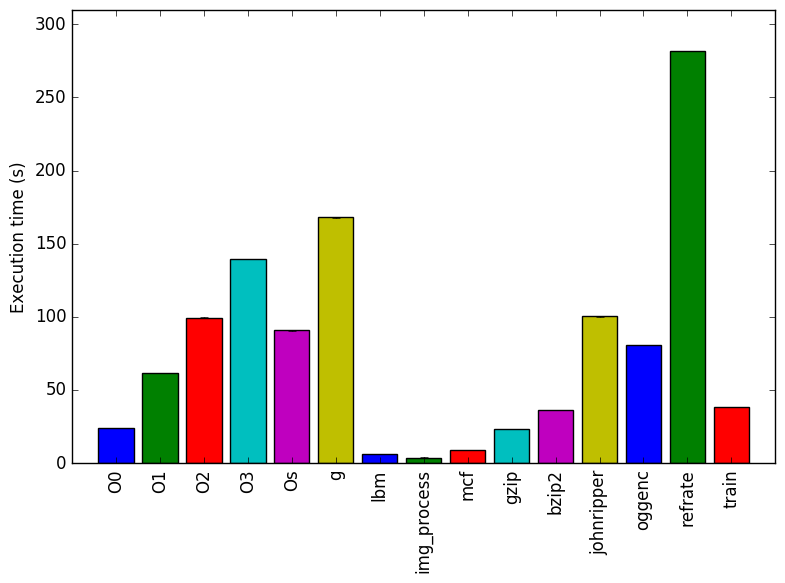
Figure 1: The mean execution time from three
runs for each workload.
This report presents:
Important take-away points from this report:
502.gcc_r is an important benchmark for the SPEC suite and its been present in all of the 5 suites released so far. The current version of the GCC benchmark used in CPU2017 is based on the GNU C Compiler 4.5.0.
The 502.gcc_r benchmark requires a preprocessed single compilation unit input. Please see the SPEC documentation for more information about the benchmark.
The source code for most large and interesting C programs is organized into multiple C and include files. OneFile is a tool that transforms a multiple-compilation-unit program into an equivalent preprocessed single-compilation-unit program. While the goal is to allow any C program to be automatically transformed into a valid input for the 502.gcc_r benchmark, OneFile has limitations. The requirements, general work flow, results and limitations are described in Section 7: OneFile’s Overview.
To download OneFile please visit: https://webdocs.cs.ualberta.ca/~amaral/AlbertaWorkloadsForSPECCPU2017/scripts/502.gcc˙r.scripts.tar.gz
OneFile uses Java and was compiled using version 1.8.0_65.
To use OneFile you must be in a directory that contains a folder named src. The src folder must contain the .c and .h files that will be merged into a single compilation unit. After that, enter the following command:
This command will invoke OneFile. The argument OUTFILE.c is required. The argument OUTFILE.c is the name of the new .c file that will be generated from OneFile.
OneFile will print messages about its progress to stdout.
There are thirteen new workloads for 502.gcc_r. The thirteen new workloads are named
502.gcc_r is a complex program with many configurable runtime options that allows users to fully specify how to compile a source file. In order to explore the impact of these different runtime options, there are two different types of workloads. The first type of workload allows one to measure the impact of different C source files and the second one allows one to measure the impact of different command line options.
The following sections describe the design of the workloads briefly. The full workloads can be downloaded at https://webdocs.cs.ualberta.ca/~amaral/AlbertaWorkloadsForSPECCPU2017/inputs/502.gcc˙r.inputs.tar.gz .
The first type of workload is designed in order to analyze the impact of different input C-files to 502.gcc_r. This impact is measured by profiling a workload as it compiles a C source file 20 times with different optimization flags. Profiling a workload this way, allows one to compare the impact of a specific c-file with another across different workloads, while the impact of optimizations averages out.
This type of workloads can be identified by their naming convention. They are named after the C-file which they repeatedly compile.
Ideal workloads should have an execution time similar to the refrate workload and exercise the workload in a way that is typically done by a user. While, compiling the same C source file 20 times with different optimization options might not be a typical use for GCC for most users, this design decision allowed some of the new workloads to achieve an execution time comparable to refrate. This decision was also used by SPEC CPU 2017 by compiling multiple times the same input C-file.
| Compilation Unit | kLOC | |
| lbm.c | 2.0 | |
| img_process.c | 3.2 | |
| mcf.c | 3.5 | |
| gzip.c | 6.6 | |
| bzip2.c | 7.0 | |
| johnripper.c | 18.5 | |
| oggenc.c | 49.5 | |
| gcc.c | 480.8 | |
| Compilation Unit | kLOC | |
| train01.c | 40.2 | |
| scilab.c | 52.2 | |
| 200.c | 59.9 | |
| gcc-smaller.c | 269.4 | |
| gcc-pp.c | 366.4 | |
| ref-32 | 414.6 | |
This strategy used to achieve workloads with an execution time similar to refrate was partially successful. While the refrate workload achieves an execution time of around 275 seconds, most of the workloads that explore differences in C-source files execute in less than 100 seconds. This difference in execution time can be explained by the difference in the line-of-code count. Table 1 and Table 2 show the kLOC count for the new single-compilation-unit C source files.
The second type of workload is designed to analyze the impact of different option flags. This impact is measured by profiling a workload as it compiles different C source files with the same option flags. For example workload O0 compiles different C source files each with only the option -O0 explicitly typed.
This type of workloads can also be identified by their naming convention. They are named after the optimization flag which was used during the execution of 502.gcc_r. E.g. O0 is the name of the benchmark that compiles several C source files with only the -O0 optimization flag.
In order to decrease the difference in execution time between these type of workloads and the refrate workload, single-compilation-unit source files train0.c, scilab.c and 200.c were added to these workloads.
A simple metric to compare the effect of various workloads on a benchmark is the benchmark execution time. All of the data in this section was obtained using the Linux perf utility and represents the mean value from three runs. The 502.gcc_r run on an Intel Core i7-2600 processor at 3.4 GHz and 8 GiB of memory running Ubuntu 14.04 LTS on Linux Kernel 3.16.0-76. To this end, 502.gcc_r was compiled with GCC 4.8.4 at the optimization level -O3, and the execution time was measured for each workload.
This section presents an analysis of the workloads for 502.gcc_r and their effects on its performance.
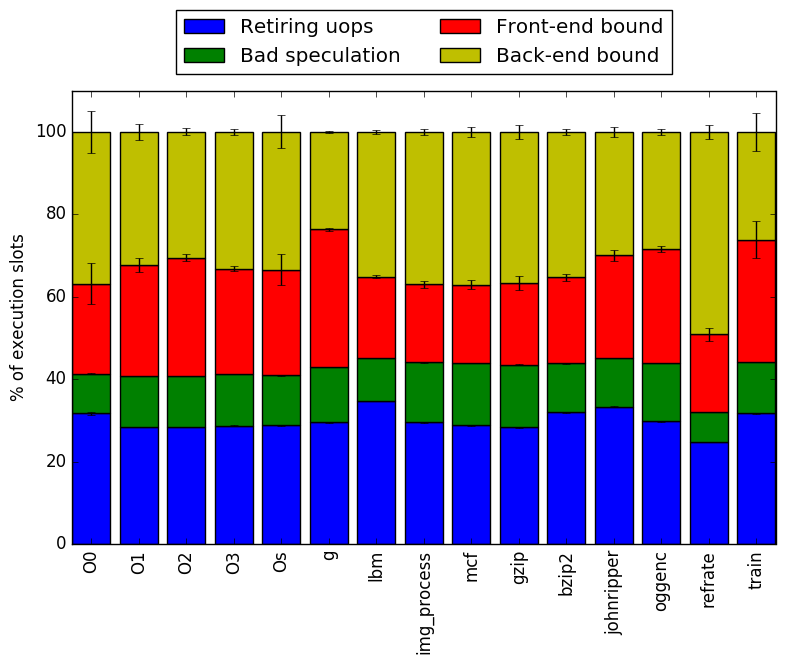
Figure 1 shows the mean execution time for each of the workloads. The execution time of 502.gcc_r is lower when it runs with workloads with a lower kLOC count.
Another interesting find is the difference between the optimization flags. Increasing the optimization level increases the execution time of the workloads.
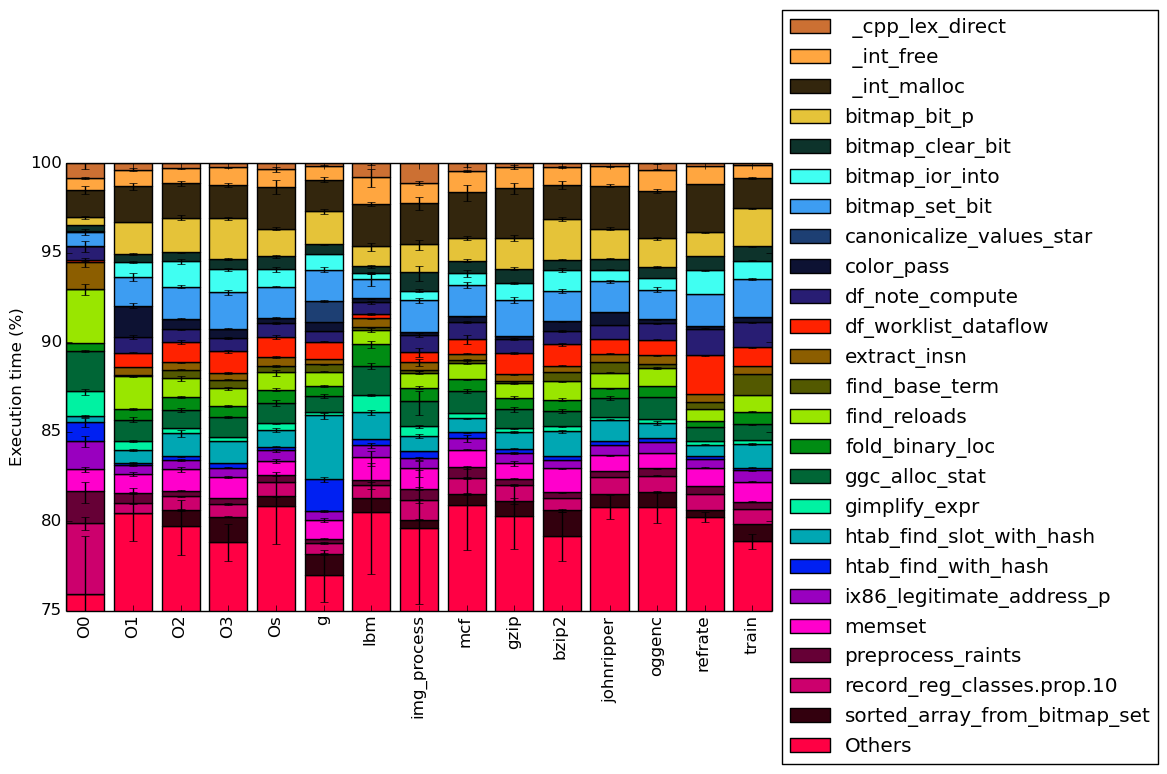
This section analyzes which parts of the benchmark are exercised by each of the workloads by showing the percentage of execution time that the benchmark spends on several of the most time-consuming functions. This data was recorded on a machine equipped with Intel Core i7-2600 processor at 3.4 GHz with 8 GiB of memory running Ubuntu 14.04 LTS on Linux Kernel 3.16.0-76.
Compared to other benchmark’s analyses, the execution on 502.gcc_r is more uniformly spread across most of the functions. In most benchmarks there are several functions that each execute for more than 5% of the execution time. However, for 502.gcc_r there are no functions that are run for more than 5% of the execution time.
Compared to other workloads, workload O0 does not execute functions found on most other workloads. The functions bitmap_ior_input, color_pass, df_worklist_dataflow and sorted_array_from_bitmap_set all execute for more than 1% of the total execution time.
Another interesting finding is that workload g, which compiles binaries with debugging symbols, is the only workload that spends more than 1% on function canonicalized_values_star.
The analysis of the workload behaviour is done using two different methodologies. The first section of the analysis is done using Intel’s top down methodology.1 The second section is done by observing changes in branch and cache behaviour between workloads.
To collect data GCC 4.8.4 at optimization level -O3 is used on machines equipped with Intel Core i7-2600 processors at 3.4 GHz with 8 GiB of memory running Ubuntu 14.04 LTS on Linux Kernel 3.16.0-76. All data remains the mean of three runs.
Intel’s top down methodology consists of observing the execution of micro-ops and determining where CPU cycles are spent in the pipeline. Each cycle is then placed into one of the following categories:
Using this methodology the program’s execution is broken down into these categories as shown Figure 6. Using the top down analysis it appears that refrate spends more time waiting for resources on the back-end than the rest of the workloads.
By looking at the behaviour of branch predictions and cache hits and misses we can gain deeper insight into the execution of the program between workloads.
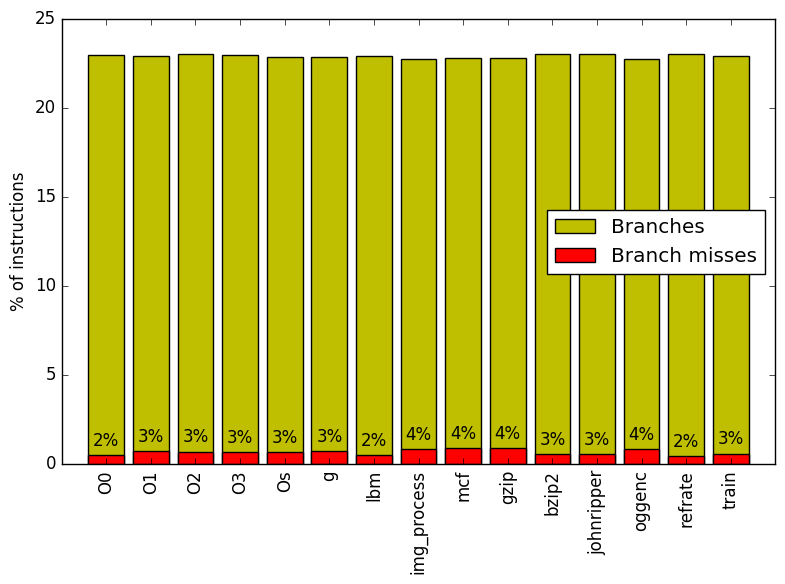
Figure 7 summarizes the percentage of instructions that are branches and exactly how many of those branches resulted in a miss. The amount of branches and branch misses do not seem to vary among different workloads.
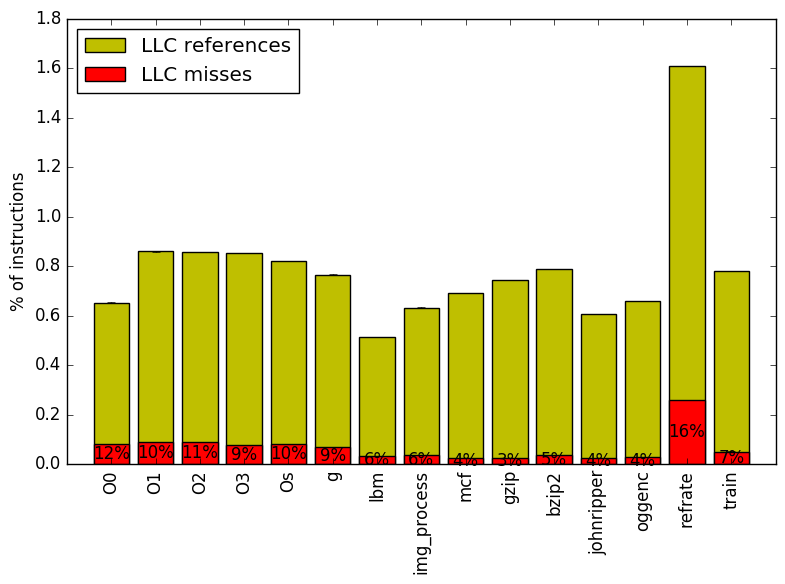
Figure 8 summarizes the percentage of LLC accesses and exactly how many of those accesses resulted in LLC misses. Workloads which compile multiple source files with different optimization flags have more LLC misses than other workloads.
This section compares the performance of the benchmark when compiled with GCC 4.8.4 and the Intel ICC compiler 16.0.3. The benchmark was compiled with these compilers at six optimization levels (-O0, -O1, -O2, -O3, -Ofast, and -Os), resulting in 12 different executables. Each workload was then run 3 times with each executable on an Intel Core i7-2600 machine mentioned earlier. The subsequent sections will compare ICC against GCC.
GCC binaries compiled with LLVM were abled to be generated. However, only binaries generated with -O0 were able to run without creating an error. The error message received said that it was an “Internal Compiler Error”.
 (a)
relative
execution
time
(a)
relative
execution
time 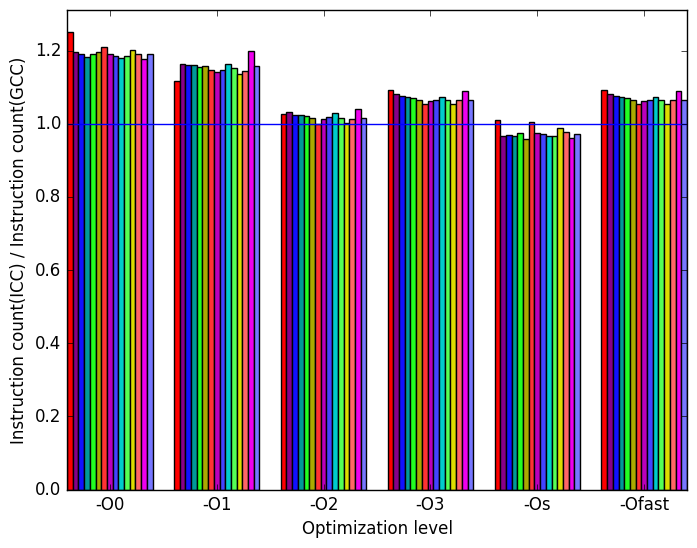 (b)
instructions
(b)
instructions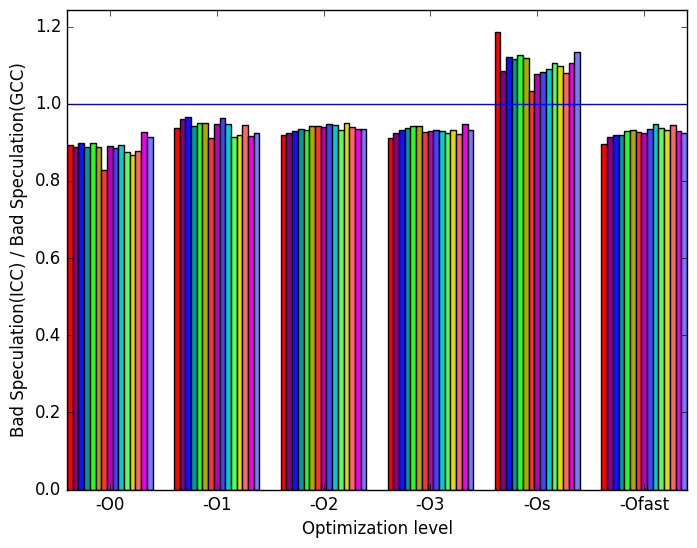 (c)
relative
number
of
bad
speculations
performed
(c)
relative
number
of
bad
speculations
performed
 (d)
cache
misses
(d)
cache
misses 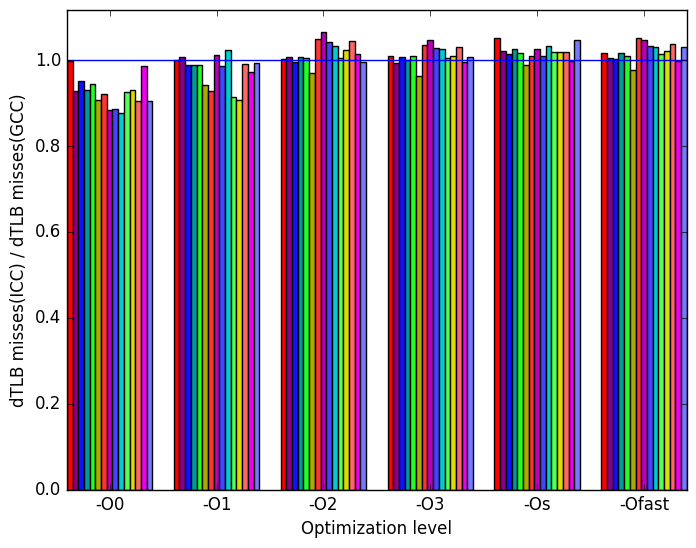 (e)
dTLB
misses
(load
and
store
combined)
(e)
dTLB
misses
(load
and
store
combined) (f)
Legend
for all
graphs
in
Figure 9
(f)
Legend
for all
graphs
in
Figure 9
The most prominent differences between the ICC and GCC generated binaries are highlighted in Figure 9.
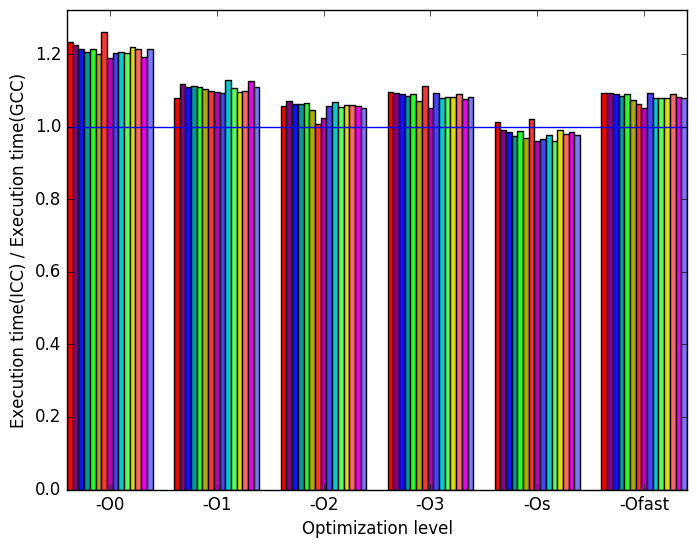
Figure 10a shows that ICC generated binaries take longer to execute than GCC generated binaries for all but optimization level -Os.
Figure 10b shows that for optimization levels -O0, -O1, -O3 and -Ofast ICC binaries execute more instructions than GCC binaries. For the rest of the optimization levels, ICC binaries execute about the same number of instructions as GCC.
Figure 10c shows that ICC binaries execute less instructions that will later be discarded due to bad speculation. However, the binary compiled with GCC at optimization level -Os performs better than its ICC counter part.
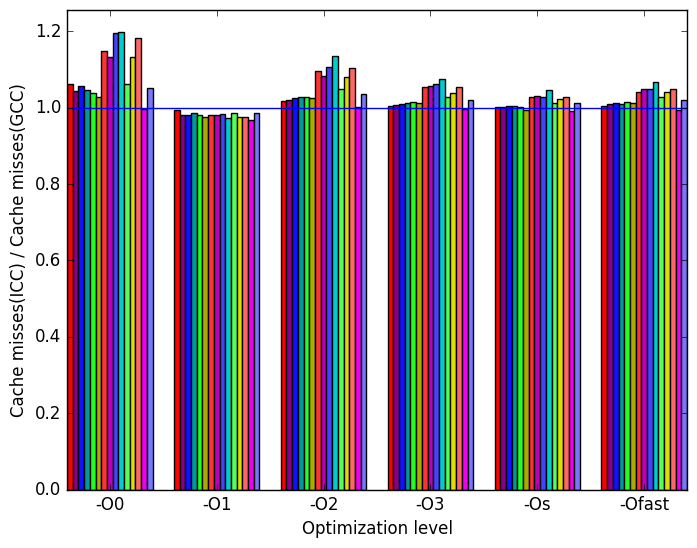
Figure 10d shows that at optimization levels -O0 and -O2 ICC generated binaries have more cache misses than GCC.
Figure 10e shows that at optimization level -O0 ICC generated binary performs better than GCC’s binary. However, ICC generated binaries perform similarly to GCC’s for the rest of the inputs.
This section describes the steps that OneFile performs to generate a pre-processed single-compilation-unit workload.
#include ”hello/world.h” changes to #include ”world.h”
#include ”hello/world.c” is ommited from files.
After this step
Linemarkers can be used to tell what code comes from which file. In particular, we care about finding out what code in our pre-processed files came from .h files.
For example:
The previous example shows a minimal preprocessed file. The output of the command
can be used to tell that the line
comes from the file world.h because it is preceded by the linemarker
The .h files could not have been removed them from the code in step 6 because these files contain important information about the semantics of the program. However, multiple .c files might include the same .h file. Thus, proceeding with name mangling of the preprocessed files at this stage would result in multiple definition errors. To deal with this problem OneFile removes all of the code found in the preprocessed files that come from .h files by calling removeLineMarkers.4
After this step, the preprocessed files contain no source code from .h files. For example:
nameMangler.jar will go through each file and ignore extern declarations. nameMangler.jar will rewrite static functions, and variables by prepending the file name to the function and variable name.
E.g.
Before name mangling, file a.c has the following content:
After name mangling, file a.c has the following content:
nameMangler.jar only mangles names of symbols that are not available to other compilation units. nameMangler.jar uses ANTLR v 4.5.3 to generate a C lexer and parser.
This final file can be compiled by a C compiler.
OneFile successfully created single compilation units for the 505.mcf_r and 519.lbm_r SPEC benchmarks and for johnripper the password cracker. These benchmarks have a simple source-code organization: all the .c and .h files are in the root directory, and hence there are no files with the same name.
There are some known limitations of this tool. One problem we encountered was that a different .h files which had the same name. It wasn’t a problem for the original c project we were attempted to convert since the .h were placed in different folders. However, when placing them at the root of the directory, this became a problem.
Another known issue is the need to address compilations that contain macro definitions. At the moment, OneFile calls gcc without any -D flags. However, it is known that certain compilations require the definition of macros in order to compile correctly. This has not been addressed. A user could manually preprocess source files and add definition flags. Then, OneFile would be able to name mangle all sources into one compilation unit.
There are some cases in which a definition is placed out of order and a unsatisfied dependency will cause the program to fail. OneFile will warn the user when this happens and the user will be required to manually inspect the code.
[1] Stephen McCamant. Large single compilation-unit C programs. https://people.csail.mit.edu/smcc/projects/single-file-programs/, January 2006. Accessed on August 09 2016.
1More information can be found in §B.3.2 of the Intel 64 and IA-32 Architectures Optimization Reference Manual .
2This is an example where execution of OneFile was cut short. You can simulate this by modifying OneFile and placing an exit command on line 22
3For documentation on linemarkers please visit https://gcc.gnu.org/onlinedocs/cpp/Preprocessor-Output.html
4This is also why OneFile made an includes.c file that we can later prepend to our name mangled source code.
5We have also provided the source code.