AIxploratorium
|
||
|
|
||
Modifications to the LearnDT algorithm[[This page is still being written. It will be completed soon!]]Many Learning Algorithms: Why use InformationGain? Or even GainRatio? Yes, they do try to find the smallest decision tree, which is sometimes useful (see Occam). But there remain several issues: First, it is not clear that the smallest tree really is the most accurate. (see No Free Lunch). Second, even if the smallest really is best, our specific algorithm does not always find the absolute smallest, as it is only GREEDILY hill-climbing. (Note that finding the smallest is NP hard.) The third, and most damning, problem is that our learner is only using a SAMPLE of the instances (here, of the games), which may not be representative of the true distributions. For example, perhaps the MallRats will almost always lose away games where Fred starts and Joe plays center (both offense and defense). But in the one such game we actually saw, they just happen to win. (This is like flipping a 0.99-head coin, and getting tails.) The pruning idea attempts to address this. There have been a variety of other "tweaks", towards addressing this. These include
Note: many researchers have found that the splitting criteria is not that useful, but pruning is essential. For that reason, essentially all decision tree learners include some pruning facility.
We could graph this: using each attribute on an axis, each instance corresponds to a point. We could then put a BOX ([]) on each point representing a positive instance (ie, a bald person), and a circle (o) on each negative instance: [Produce this graph!] This graph also includes a line that separates the positive from the negative instances. Here, we drew a straight line. The obvious decision tree, here, would be [Draw this tree!] Its "decision surface" is a bit more complicated, as it first splits based on age, and then, for certain ages, further divides, based on gender: [Produce this revised graph!] Notice the decision boundary, here, is composed of a series of axis-parallel segments. This is true of decision-trees in general. Now recall our basketball example: Here, each instances corresponds to a point in a 6-dimensional "instance" space, as each instance has a "Where" value (either Home or Away) a "When" value (one of 5pm, 7pm or 9pm), a "Fred Starts" value (either Yes or No), etc. (As each game corresponds to exactly one of these, there are 2*3*2*2*2*2=96 possible types of games. Of course, several different games could have the same description.) Each of the decision trees considers again corresponds to a sequence of such axis-parallel "hyper-planes". Another approach is to consider "oblique" trees. See Salzberg, Kasif, ... [[to be completed]]
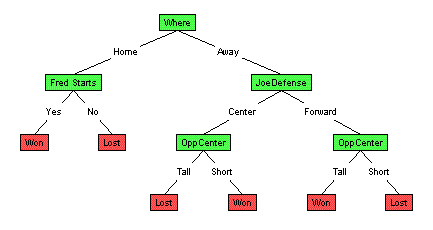
Note the lower left is the exclusive-or of "OppC=Tall (+) JoeDefense=Center". [[to be completed]] Actually there is a yet-smaller tree. Can you find it? |
|||||||||||||||||||
|
|