AIxploratorium
|
||
|
|
||
PruningHere, LearnDT no doubt produced a huge tree; typically with over 30 nodes. (Using Gain, we produced a tree with 37 nodes; 18 internal.) While its resubstitution error is near 0 (as we continued to purity when possible), its apparent generalization error (measured on the hold-out set) was huge --- typically around 0.375. (Why?). However, notice that FrogLegs wins 75% of the time; this means trivial decision tree, containing just the single (leaf) node labeled "Won", would have a much smaller error --- around 0.25. This means the larger decision tree is both larger (and so takes more storage, and is harder to explain) and less accurate! While this is an extreme case, this type of situation is quite common, and has led to a technology to address this issue. This problem is called overfitting, which refers to the situation where the data suggests the wrong classifier: Eg, where the resubstitution error of classifier C1 is lower than that of C2, while the true error of C2 is lower than C1's (here you pick C1, even though C2 is actually better). This is happening here, as the trivial tree
appears worse than the propsed tree 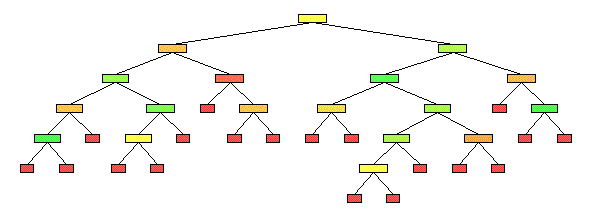
but actually is better. PruningThe basic LearnDT algorithm tried to grow each branch to purity. As shown above, this is typically way too far, as this allows the learning algorithm enough "degrees of freedom" that it can fit arbitrary nuances of the training data. It is better, in general, to restrict the learner to "smaller" trees, as this means they cannot match any possible ideosyncracy of the data. (That is, if such a smaller tree does match the data, it is unlikely to be a fluke; see Occam Algorithms.) But how small should we force our trees to be? While this is hard to tell a priori, we can still use this insight as follows: First grow the trees as far as possible (ie, to purity if possible) --- see top figure below. Then prune back some branches, to produce a smaller tree (a "subtree" of the initial tree) -- see bottom figure below. 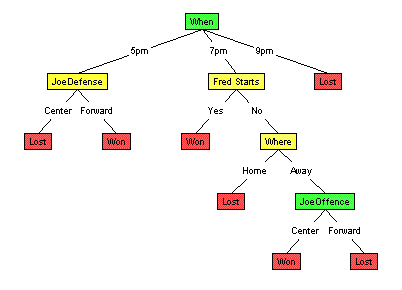
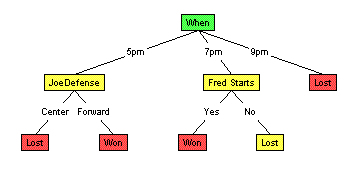
How? Notice the larger tree will necessarily have a smaller resubstitution error than the smaller one; this is by construction (recall how the trees were grown!). However, as we discussed earlier, this does not mean the larger tree will have a smaller generalization error. Why not use a hold-out set to estimate the generalization errors of the two trees?
Try it!
Go to the applet, and make sure the "FrogLegs" dataset is loaded. Here, we'll use one type of pruning, known as "Reduced-Error Pruning" (described above) to tidy up our overgrown tree.
Now run the algorithm (by selecting the "Run" option from the "Algorithm" menu) and watch the result. Alternatively, if tree construction and pruning occurs too quickly, you can use the "Step" option under the "Algorithm" menu to step through the algorithm line by line. Occassionally, the randomly generated tree might correctly classify all the holdout examples (it's rare, but it can happen), and so no pruning will take place. If this is the case, try generating another random holdout set and running the algorithm again. |
|||
|
|

 The algorithm is quite straight-forward:
First grow the tree, from root to leaves, as discussed above.
But here only use a subset of given data, called the "training set".
Then consider pruning the tree, starting from the leaves:
Here, consider making each penultimate node into a leaf,
with the appropriate label
(that is, the label that is most common over the instances that reach here).
Then measure the the "hold-out error" of the resulting tree
(over the hold-out data)
and compare that with the hold-out error of the current (unpruned) tree.
If the pruned tree has smaller hold-out error,
then leave that node as a leaf;
otherwise revert to the current tree.
Then recur -- considering all branching, and going up the branch if
appropriate.
The algorithm is quite straight-forward:
First grow the tree, from root to leaves, as discussed above.
But here only use a subset of given data, called the "training set".
Then consider pruning the tree, starting from the leaves:
Here, consider making each penultimate node into a leaf,
with the appropriate label
(that is, the label that is most common over the instances that reach here).
Then measure the the "hold-out error" of the resulting tree
(over the hold-out data)
and compare that with the hold-out error of the current (unpruned) tree.
If the pruned tree has smaller hold-out error,
then leave that node as a leaf;
otherwise revert to the current tree.
Then recur -- considering all branching, and going up the branch if
appropriate.