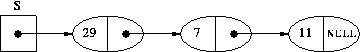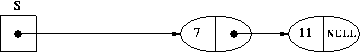Consider the stack of integers S = 29,7,11 (29 is the top, 11 the bottom). The logical order of the values in a stack is very clear; first comes the top element, next comes the element just below the top element, etc. In a linked implementation, this relationship will be explicitly represented: the memory cell containing the top element will also contain a pointer to the second element, the memory cell containing the second element will contain a pointer to the third element, etc. What about the memory cell containing the bottom element?
So this is our basic implementation:
There will be one memory cell for each element in the stack; in this memory cell we need to store two things: the value of the element, which is an integer in this example but could be anything, and a pointer to the memory cell of the next element.Having decided this, we can now draw the node-and-arc diagram representing S.
What about S itself? It will be a variable in our program, explicitly declared. So it will be a box. What is in the box? Well, one thing for sure, we need to store a pointer to the top element. In addition, we could store anything else we like.
In terms of actually coding this in C, some things are already settled.
An important question is, how will we represent the EMPTY stack? There are actually several possibilities.
The remaining operations - POP, PUSH, and DESTROY_STACK - are a little more complex because they actually involve allocating or freeing of memory. I will show you how to design one of them: the method of design I use is completely general and I recommend that you use it for designing all operations on all the data structures you ever implement.
This design method works exclusively with the node-and-arc diagrams. Yet it works out the step-by-step details of how to implement the operation, so all that remains to be done is to translate each step into C code (each step typically needs one or two simple lines of code, so this process is almost 100% mechanical).
All you do is draw a before and after picture - two node-and-arc diagrams, one showing the values passed to the operation before it is executed, the other showing the values created/changed by the operation after it has finished. For example, consider the POP operation.

A typical input to the POP operation is the stack S (as above):
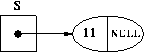
That is our before diagram. Here is what S will look like after the POP:
That is our after diagram. All we have to do, to design the inner workings of the POP operation, is to list all the differences between the before and after diagrams. How many can you see?

Now, let us work out exactly what needs to be done to achieve these 2 changes.

Well, there is one case that always deserves close scrutiny, because it often requires special processing. What happens if there is only one element in S, and we POP it off making S empty. This might be different than a typical case, because, an empty stack does not `look the same' as a non-empty one (partly this depends on exactly how we choose to represent the empty stack). Let's see:
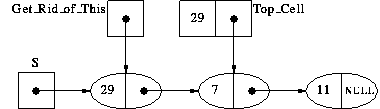
After doing steps 1a and 2a, we will have:
where Top_Cell is a copy of the cell S is currently pointing to.
Everything looks like it will work. Step 1b will free up the cell, and the `next' pointer in Top_Cell, which is destined to become S's TOP pointer (by step 2b) is NULL, as it should be. So, these four steps, in this order, will work on all valid inputs. However, sometimes this is not the case; sometimes different inputs require different processing, and you have to do before/after analysis for each of the different kinds of inputs.
The very last thing we need to consider before turning all this into code is: in what order should these steps be done in?
Obviously we must not delete the TOP cell (step 1b) until we have grabbed the pointer in it that we need (for change 2). But rather than thinking too hard about these intricate interactions, here is a very easy, and completely general-purpose way to sequence these operations.
The trick is to do all the steps without changing the before diagram; but to store things you need in temporary variables, e.g. Get_Rid_of_This, Top_Cell, etc.
Then when you have collected into temporary variables all the information you need, you can make the changes to the data structure in any order you like. Here is how this strategy works on the four steps needed to implement the POP operation. Steps 1b and 2b are the ones that actually change the given data structure S, so they are done last (in any order you like). Step 2a and 1a are done first, in either order. After doing 1a and 2a to our original `before' diagram we get:
And now we can finish off with the final steps - 1b and 2b - in either order.
But they key idea in this strategy - the main thing to remember - is the idea of using the differences between before and after diagrams to define what steps are needed to implement the operation. If you do this, you will have no trouble implementing PUSH, DESTROY_STACK, or any other operation on any linked data structure.
One last thing to remember: these procedures can call each other. This can be very useful. For example, you will find it very easy to write DESTROY_STACK if you first write IS_EMPTY and POP and then use them in the implementation of of DESTROY_STACK.
![]()
![]()