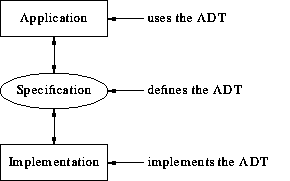
It illustrates an important, general idea: the idea of layered software. In this picture there are two layers: the application layer and the implementation layer. The critical point - the property that makes these truly separate layers - is that the functionality of the upper layer, and the code that implements that functionality, are completely independent of the code of the lower layer. Furthermore the functionality of the lower layer is completely described in the specification.
We have already discussed how this arrangement permits very rapid, bug-free changes to the code implementing an abstract data type. But this is not the only advantage.
Another great advantage is that the abstract data type (implemented in the lower layer) can be readily reused: nothing in it depends critically on the application layer (neither its functionality nor its coding details). An abstract type like `stack' has extremely diverse uses in computer science, and the same well-specified, efficient implementation can be used for them all (although always keep in mind there is no universal, optimally-efficient implementation, so efficiency gains by re-implementation are always possible).
Libraries of abstract datatypes are a very effective way of extending the set of datatypes provided by a programming language, which themselves constitute a layer of ``abstraction'' - the so-called virtual machine - above the actual data types supported by hardware. In fact, in an ordinary programming environment there are several layers of software - layers in the same strong sense as above.
The use of strictly layered software is good software engineering practice, and is quite common in certain software areas. Operating systems themselves have a long tradition of layering, starting with a small kernel and building up functionality layer-by-layer. Communications software/hardware also conforms to a well-defined layering.
The concept of layered software suggests a software development methodology quite different from top-down design. In top-down design one starts with a rather complete description of the required global functionality and decomposes this into subfunctions that are simpler than the original. The process is applied recursively until one reaches functions simple enough to be implemented directly. This design methodology does not, by itself, tend to give rise to layers - coherent collections of subfunctions whose coherence is independent of the specific application under development.
The alternative methodology is called ``bottom-up'' design. Starting at the bottom - i.e. the virtual machine provided by the development environment - one builds up successively more powerful layers. The uppermost of these layers, which is the only one directly accessible to the applications developer, provides such powerful functionality that writing the final application is relatively straightforward. This methodology emphasizes flexibility and reuse, and, of course, integrates perfectly with bottom-up strategies for implementation and testing. Throughout the development process, one must bear in mind the needs of the specific application being developed, but, as said above, most of the layers are quite immune to large shifts in the application's functionality, so one does not need a ``final'', ``complete'' description of the required global functionality, as is needed in the top-down methodology.
![]()
![]()