

4.2. Graph Traversal
To traverse a graph is to process every node in the graph exactly
once. Because there are many paths leading from one node to another,
the hardest part about traversing a graph is making sure that you do
not process some node twice. There are two general solutions to this
difficulty:
- when you first encounter a node, mark it as REACHED. When you
visit a node, check if it's marked REACHED; if it is, just
ignore it. This is the method our algorithms will use.
- when you process a node, delete it from the graph. Deleting the
node causes the deletion of all the arcs that lead to the node,
so it will be impossible to reach it more than once.
At the heart of our traversal algorithm - and in fact all of our
algorithms - is a list of nodes that we have reached but not yet
processed. we will call this the READY list.
General Traversal Strategy
- Mark all nodes in the graph as NOT REACHED.
- pick a starting node. Mark it as REACHED and place it on the
READY list.
- pick a node on the READY list. Process it. Remove it from READY.
Find all its neighbours: those that are NOT REACHED should
marked as REACHED and added to READY.
- repeat 3 until READY is empty.

Example:
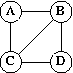
- Step 1: A = B = C = D = NOT REACHED.
- Step 2: READY = {A}. A = REACHED.
- Step 3: Process A. READY = {B,C}. B = C = REACHED.
- Step 3: Process C. READY = {B,D}. D = REACHED.
- Step 3: Process B. READY = {D}.
- Step 3: Process D. READY = {}.
In fact this will traverse only a connected graph. To traverse a graph
that might be unconnected, you repeat this whole procedure until all
nodes are marked as REACHED.
There are two choice points in this algorithm: in step 2,
how do we pick the initial starting node, and in step 3 how do we pick
a node from READY?
The answer is, it depends on what you are trying to accomplish. If
all you want to do is print out nodes, or count them, or do any other
processing that is order-independent, then any selection will do.
The two most common traversal patterns are breadth-first
traversal and depth-first traversal.
In breadth-first traversal, READY is a QUEUE, not an arbitrary
list. Nodes are processed in the order they are reached (FIFO). This
has the effect of processing nodes according to their distance from
the initial node. First, the initial node is processed. Then all its
neighbours are processed. Then all of the neighbours' neighbours etc.
In depth-first traversal, READY is a STACK; the most recently
reached nodes are processed before earlier nodes.

Let us compare the two traversal orders on the following graph:
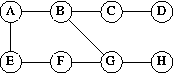
Initial Steps:
READY = [A]. Process A. READY = [B,E]. Process B.
It is at this point that two traversal strategies differ.
Breadth-first adds B's neighbours to the back of READY;
depth-first adds them to the front:
Breadth First:
- READY = [E,C,G].
- process E. READY = [C,G,F].
- process C. READY = [G,F,D].
- process G. READY = [F,D,H].
- process F. READY = [D,H].
- process D. READY = [H].
- process H. READY = [].
Depth First:
- READY = [C,G,E].
- process C. READY = [D,G,E].
- process D. READY = [G,E].
- process G. READY = [H,F,E].
- process H. READY = [F,E].
- process F. READY = [E].
- process E. READY = [].
Our discussion of graphs will continue next lecture.