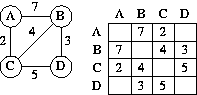
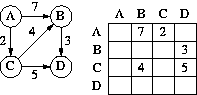
The most popular and convenient representation of a graph, whether directed or undirected, weighted or unweighted, is an adjacency matrix. The graph is represented by a matrix whose rows and columns are indexed by the nodes. There is an entry in the matrix in row N1, column N2, iff there is an edge from N1 to N2 in the graph. In a weighted graph, the matrix position (N1,N2) would contain the weight of the edge from N1 to N2.
In the adjacency matrix for a directed graph the successors of node N are stored in row N and the predecessors for node N are stored in column N. For example:
Row `B' gives the successors of `B', column `B' gives predecessors of `B'. The fact that row `D' is empty indicates that `D' has no successors; similarly, column `A' being empty indicates `A' has no predecessors.
Certain operations are extremely efficient with an adjacency matrix representation:
In fact, we have already discussed the solution to this problem. When a graph has very few - O(N) - edges, almost all the positions in the matrix will be zero (empty). Does anyone recall an efficient implementation of almost-empty matrices we discussed several lectures ago?
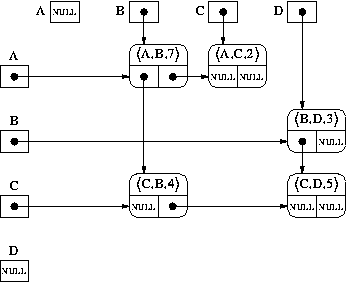
A matrix in which most of the positions are zero is called a sparse matrix. We talked about these in our lecture about multi-linked lists. They can be represented very efficiently by having each row be a linked list, and each column a linked list, where the rows and columns share nodes. You only allocate space for the non-empty positions of the matrix. The matrix above would be represented in this way:
The space needed is O(N+E) - there are 2N list headers and one node in the matrix for each edge in the graph (E nodes in the matrix in total). For each edge in the graph there are 2 pointers (next-in-row, next-in-column), a weight, and the names of the nodes the edge connects.
This representation is commonly called the adjacency list representation. Often, for simplicity of implementation, the successor and predecessor lists do not share nodes but have separate, redundant nodes. If the graph is undirected, the predecessor and successor lists will be identical so only one of them is necessary.
The biggest drawback of this representation is that deleting an edge, or even looking up its weight, is O(E) time, not constant-time as it is with an adjacency matrix.
![]()
![]()