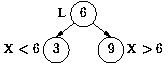Before discussing these trees, we first need to understand the idea of binary search.
Suppose we have a list L and in this list we are searching for a value X. If L has no special properties, if it might be any old list, then there is no better way to search it than to start at the beginning and go through the list one step at a time comparing each element to X in turn. This is called linear search - the time it takes (on average, and in the worst case) is linear, or O(N), in the length of the list.
But if L is a sorted list, there is a much faster way to search for X:
Example: L = 1 3 4 6 8 9 11. X = 4.
The difference between O(logN) and O(N) is extremely significant when N is large: for any practical problem it is crucial that we avoid O(N) searches. For example, suppose your list contained 2 billion (2 * 10**9) values. Linear search would involve about a billion comparisons; binary search would require only 32 comparisons!

Binary search works perfectly if lists are implemented with arrays. But, there is a problem with linked implementations of lists. Can anyone see what it is?
Answer: With a linked implementation we cannot find the middle of the list in constant time: it takes linear time (not just in our implementation, but in any linked implementation), and this takes away all the speedup we get from binary search.
What can we do about this? We need linked implementations for their memory efficiency and flexibility, but we cannot afford to do linear search.
Let's design a linked structure specifically for doing binary search very efficiently. It will contain exactly the pointers needed for binary search. What's the first thing we need? A pointer to the middle element.
Using our previous example (L -> 6), what should the node `6' point to? Well, when we compare X to 6 there are two possible outcomes that involve further search: X < 6 and X > 6. In the first case we need a pointer from `6' to the middle of the front half of L, i.e. from `6' to `3'. In the second case we need a pointer from `6' to the middle of the last half of L, i.e. to `9'.
So the pointers we've got so far:
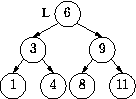
What pointers do we need emanating out of `3'? Again there are two, one for each possible outcome of comparing X to 3 that requires further search. If X < 3 we need a pointer to the middle of the portion of L less than 3. If X > 3 we need a pointer to ... be careful here ... this pointer should not be to the middle of the portion of L bigger than 3. We have already eliminated all the elements bigger than or equal to 6. So this pointer should point to the middle of the portion of the list between 3 and 6. Similarly for 9. So here is our final data structure:
As you can see this structure is a binary tree. But is not an arbitrary binary tree; it has two special properties:

A binary tree with these properties is called a Binary Search Tree. In a binary search tree we can search for a value in O(logN) time, where N is the number of nodes in the tree. The algorithm is exactly the binary search algorithm, but translated in terms of `root' and `subtrees':
Example: search for 5 in the above tree.
The properties defining a BST (my abbreviation for Binary Search Tree), mean that it is very easy to traverse the tree in increasing (or in decreasing order). To traverse a BST in increasing order here is what we must do:
From the node containing the value N:
How would we traverse the BST in decreasing order?
Answer: Right to Left infix traversal.
![]()
![]()