typedef struct { int numerator,denominator; } fraction;
main()
{
fraction f;
f.numerator = 1;
f.denominator = 2;
...
}
#define numerator 0
#define denominator 1
typedef int fraction[2];
main()
{
fraction f;
f[numerator] = 1;
f[denominator] = 2;
...
}
These are just 2 of many different possibilities. Obviously, these
differences are in some sense extremely trivial - they do not affect
the domain of values or meaning of the operations of fractions.

In a real application we would like to be able to experiment with many different implementations, in order to find the implementation that is most efficient - in terms of memory and speed - for our specific application. And, if our application changes, we would like to have the freedom to change the implementation so that it is the best for the new application.
Equally important, we would like our implementation to give us simple implementations of the operations. It is not always obvious from the outset how to get the simplest implementation, so, again, we need to have freedom to change our implementation.
What is the cost we must pay in order to change implementation? We have to find and change every line of code that depends upon the specific details of the implementation (e.g. available operations, naming conventions, details of syntax - for example, the two implementations of fractions given above differ in how you refer to the components: one uses the dot notation for structures, and the other uses the bracketed index notation for arrays). This can be very costly, expensive, and can run a high risk of introducing bugs.
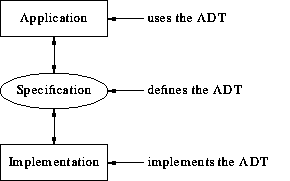
This is the idea of an abstract data type. We define the data type - its values and operations - without referring to how it will be implemented. Applications that use the data type are oblivious to the implementation: they only make use of the operations defined abstractly. In this way the application, which might be millions of lines of code, is completely isolated from the implementation of the data type. If we wish to change implementations, all we have to do is re-implement the operations. No matter how big our application is, the cost in changing implementations is the same. In fact often we do not even have to re-implement all the datatype operations, because many of the them will be defined in terms of a small set of basic core operations on the datatype.
Core Fraction Operations

create_fraction(N,D)
N/D.
get_numerator(F)
get_denominator(F)
fraction ADD(fraction F1, fraction F2)
{ int n1 = get_numerator(F1);
n2 = get_numerator(F2);
d1 = get_denominator(F1);
d2 = get_denominator(F2);
return create_fraction( n1*d2+n2*d1 , d1*d2 ); }

In general terms, an abstract data type is a specification of the values and the operations that has 2 properties:
All your programs in this course must divide like this. T.A.'s may well test the independence of the two parts by substituting one of their own.
If programming in teams, implementers and application-writers can work completely independently once the specification is set.
![]()
![]()
![]()