Patches and Patchcords:
An Analysis of How Computer Music End-user Programmers Develop Musical Code


Gregory Burlet, Abram Hindle
University of Alberta
Department of Computing Science
Software Engineering Research Lab
Introduction
Musicians currently have a multitude of tools at their disposal for creating music. Before the digital age, music was created by physically manipulating a conventional musical instrument to produce sound. With the advent of synthesizers, samplers, and sequencers came a rapid paradigm shift in the music creation process that increasingly challenged the definition of "instrument", the role of musicians, and their technical proficiency. Many musicians have embraced the technical challenges arising from the changing landscape of the music creation process, forming a relatively small but tight-knit [1] community of individuals who are invested in developing their own music-making applications on computers or mobile devices.
Computer musicians are end-user programmers who often have no formal training in the field of computing science; however, end-user programmers "face software engineering challenges that are similar to their professional counterparts" [2]. Computer musicians often use visual programming languages to realize their musical compositions. This research study conducts a multifaceted analysis of the software development practices of computer musicians when programming in visual music programming languages. An example of a visual music patch programmed in Max/MSP is displayed in Figure 1.
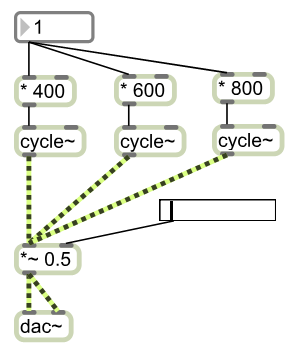
The primary objective of this research is to analyze the software development practices of computer musicians when creating musical applications in the Max/MSP and Pure Data visual programming languages and investigate to what extent this development practice differs from the general population of software developers. If a difference exists then perhaps software engineering tools or education can be tailored to help computer musicians. To this end, a statistical analysis of project metadata harvested from computer musicians' source control repositories hosted on GitHub is performed. In the subsequent section, clone detection is performed on Max/MSP and Pure Data patches to gain insight into the code structures that are often used and repeated by computer music software developers. The next section introduces a web application capable of visualizing the evolution of Max/MSP and Pure Data patches and provides commentary on the evolution of these patches. Finally, a survey of computer musicians is conducted and is supplemented with computer musician interviews to provide qualitative and anecdotal evidence to support the quantitative results in this technical report.
Related Work
A. End-user Programmers
The study of end-user programmers and their communities is an active research topic in the field of software engineering. Ko et al. [3] suggest that end-user software engineering research aims to "study end-user programming practices and invent new kinds of technologies that collaborate with end users to improve software quality". There has recently been a fundamental shift in the perception of end users as being consumers to being participators, demanding software frameworks and programming environments that are easily extensible and malleable to their needs [4]. End-user programmers have different goals than professional programmers who are paid to develop, test, deploy, and maintain software over a period of time [3]; they often develop programs using special-purpose languages to achieve a personal goal in their domain of expertise [5]. Considering these definitions, computer musicians fall into the category of "end users" because they often use specialized music-oriented programming languages for their personal creative musical endeavours.
Although specialized audio libraries exist for languages such as C or Java, these are general purpose programming languages, which are arguably ill-suited for the specific needs of computer musicians [6] who require flexibility in the combination of concepts and tools for their creative compositions [7]. Among the specialized music-oriented programming languages used by computer musicians are visual programming languages such as Max/MSP or Pure Data. These real-time programming environments provide immediate visual and auditory feedback to the programmer, allowing them to test for and hypothetically eradicate bugs at run-time [8].
B. Software Repository Mining
Significant effort has been devoted to mining Git software repositories in order to analyze software artifacts, calculate project development metrics, and study authorship tendencies and collaboration among authors. Hosting over 6.8 million public Git repositories, GitHub is among the most popular collections of publicly available software projects on the internet [9]. The mining software repositories (MSR) research community has gone through great lengths to harvest the publicly available software repository data hosted on GitHub and to publish the resulting dataset called GHTorrent [10].
C. Clone Detection Algorithms
Software clones are duplicates of code entities—or in the case of visual programming languages, subgraphs of connected objects—with or without minor adaptations such as changes to parameter values. The detection of clones in a software system can promote code reuse, refer novice programmers to existing related code, as well as locate software entities that may benefit from refactoring. Several clone detection algorithms have been proposed in the literature [11],[12] and operate by first setting the granularity of detected clones. For example, one might be interested in looking for clones that are exact replicas of other code entities, or clones that are identical except for changes in literal values, identifier names, layout, and comments. Next, the relevant information is extracted from each code entity under analysis and a matching algorithm is used to detect identical code fragments.
Focusing on clone detection in visual music programming languages, the spatial arrangement of objects in Max/MSP or Pure Data patches potentially affects the semantics of the program. Taking this into consideration, Gold et al. [13] propose a clone taxonomy and use pairwise comparison of Max/MSP patch subgraphs to locate clones. This clone detection algorithm was run on 68 preprocessed Max/MSP tutorial patches supplied with the software and found that 86% of connected objects were clones in the lowest level of granularity. Gold et al. [13] did not consider Pure Data patches or patches developed by the computer music community.
Mining Software Repositories
In an effort to understand if computer musicians develop software differently than the general population of programmers, a statistical analysis of project metadata harvested from Git repositories hosted on GitHub has been performed.
A. Software Repository Datasets
The GHTorrent database of extracted Git repositories is queried to compile three datasets. The first dataset consists of 819 computer music repositories and was formed by querying the language field in the GHTorrent MySQL database to retrieve repositories that predominantly contain Max/MSP or Pure Data files. Table 1 provides an overview of the scale of the compiled dataset. Notably, Pure Data projects are over-represented in the compiled dataset; on GitHub there are almost four times as many repositories containing predominantly Pure Data patches as there are repositories containing predominantly Max/MSP patches. The second dataset consists of 819 general software repositories collected by random sampling. The random sampling methodology was as follows: 819 random project identifiers in GHTorrent were generated; if a repository was unable to be cloned due to deletion—a frequent occurrence on GitHub [10]—or renaming, a new random project identifier was resampled. The resulting dataset represents a random sample of Git repositories from the general population of software developers. The third dataset consists of 819 of the most highly active repositories hosted on GitHub, according to the number of total commits. For each extracted Git repository, several attributes of interest are calculated: number of commits, number of weekend or weekday commits, frequency of commits, number of issues, number of unique authors, and number of forks on GitHub.
| Max/MSP | Pure Data | Total | |
|---|---|---|---|
| Repositories | 168 | 651 | 819 |
| Patches | 15,016 | 103,465 | 118,481 |
| Objects | 565,705 | 2,521,573 | 3,087,278 |
| Comment Objects | 86,127 | 419,109 | 505,236 |
| Mean Objects Per Patch | 37.67 | 24.37 | 26.06 |
| Patchcords | 508,295 | 1,973,871 | 2,482,166 |
B. Hypotheses and Significance Tests
After interviewing 15 computer musicians of various skill levels, we propose several hypotheses about the software development practices of this end-user community (represented by the first dataset) relative to the general population of software developers (represented by the second dataset):
- Ho: Computer musicians and general software developers make the same number of commits.
Ha: Computer musicians make less commits than general software developers. - Ho: Computer musicians and general software developers make equal numbers of weekend commits
Ha: Computer musicians make more weekend commits than general software developers - Ho: Computer musicians and general software developers commit with the same frequency
Ha: Computer musicians commit less frequently than general software developers - Ho: Computer musicians and general software developers create the same amount of issues (bug reports) Ha: Computer musicians create less issues than general software developers.
- Ho: The number of unique authors contributing to computer musicians' and general software developers' repositories are equal. Ha: Computer musicians' repositories have less unique authors than general software developers' repositories.
- Ho: The number of forks of computer musicians' and general software developers' repositories are equal.
Ha: Computer musicans' repositories have a different number of forks than general software developers' repositories.The number of forks is calculated for each software repository. Figure 7 displays a side-by-side box plot of fork counts for the computer music dataset, the dataset of random samples of Git repositories, and the busy sample of Git repositories. To properly display the results, the fork counts were transformed into the logarithmic domain. The Wilcoxon rank sum test reports a z-value of 0.330 and a p-value of 0.741 for a two-sided significance test. At alpha=0.01 there is insignificant evidence to reject the null hypothesis and we conclude that both computer musicians' and general software developers' repositories have similar numbers of forks. Both the computer music dataset and the random sample dataset had significantly less forks than the busy sample of repositories.
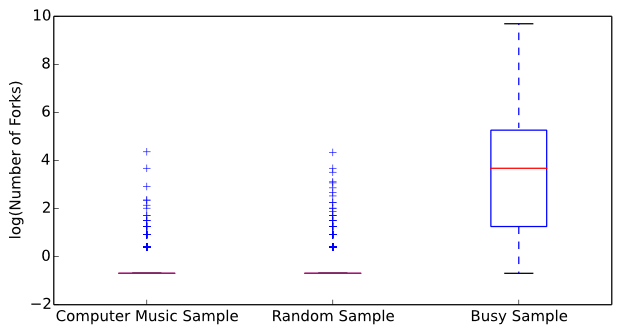
Figure 7: Box plots of the number of forks made of repositories in the computer music dataset (left), of repositories in the general software developers dataset (middle), and of the busy dataset (right).
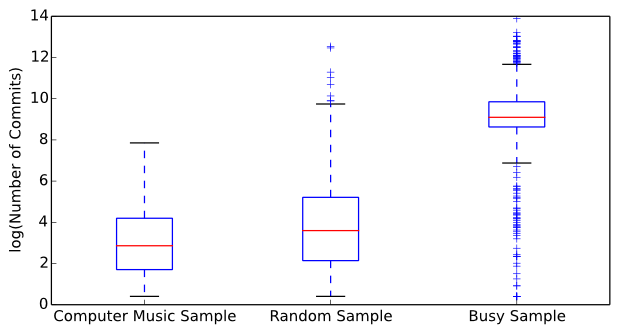
Figure 2 displays a side-by-side box plot of commit counts for the compiled computer music dataset (median: 17 commits), the random sample dataset (median: 36 commits), and the busy sample dataset (median: 8924 commits). To properly display the results, the commit counts were transformed into the logarithmic domain. The Wilcoxon rank sum test reports a z-value of -7.332 and a p-value of 1.133e-13. At alpha=0.01 there is extremely strong evidence to reject the null hypothesis and conclude that computer musicians make less commits than the general population of software developers. As several computer musicians noted during interviews, less commits may be made because of the community's culture of sharing intellectual property or the inability of computer musicians to identify significant structural changes in code. Both the number of commits made by computer musicians and the random sample of repositories were significantly less than that of the busy sample of repositories.
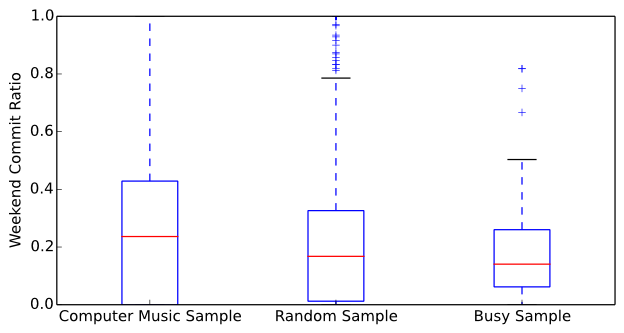
Before performing the statistical test, the data first needs to be preprocessed. Each repository has zero or more commits and each commit has an associated timestamp. If the commit occurred on a weekday it is assigned a value of zero, otherwise it is assigned a value of one. The average of these values are calculated for each repository and the result is the proportion of commits that occur on weekends. Figure 3 displays a side-by-side box plot of the proportion of commits occurring on weekends for the compiled computer music dataset, the random sample dataset, and the sample of busy repositories. The Wilcoxon rank sum test reports a z-value of 3.805 and a p-value of 7.091e-5. At alpha=0.01 there is strong evidence to reject the null hypothesis and conclude that computer musicians make more weekend commits than general software developers. However, it is incorrect to reach the conjecture that computer musicians typically operate on the weekend; the box plot in Figure 3 shows that the median proportion of weekend commits is 23.6% for the sample of computer musicians' repositories. Further, at alpha=0.01 there is no significant difference between the number of weekend commits of the random sample of repositories and the busy sample of repositories (z-value of 1.1592, p-value of 0.2464 for a two-sided significance test).
For each software repository, the difference between subsequent commits in hours is calculated and concatenated into an array of 49,762 commit delays for the computer music dataset, 1,207,413 commit delays for the random sample dataset, and 21,659,406 commit delays for the busy sample dataset. Figure 4 displays a side-by-side box plot of commit delays for the sample of computer music repositories (median of 0.471 hours between commits), the random sample of repositories (median of 0.034 hours between commits), and the busy sample of repositories (median of 0.083 hours between commits). The commit delays along the y-axis have undergone a logarithmic transformation to properly display the result. The Wilcoxon rank sum test reports a z-value of 167.323 and a p-value of practically 0. At alpha=0.01 there is extremely strong evidence to reject the null hypothesis and conclude that computer musicians commit less frequently than general software developers. This result makes sense given that computer musicians make significantly more commits on weekends in relation to the general population of software developers, yielding longer delays between subsequent commits. Further, the frequency of commits in the random sample of repositories were significantly lower than that of the busy sample of repositories (z-value of 24.124 and a p-value of practically 0).
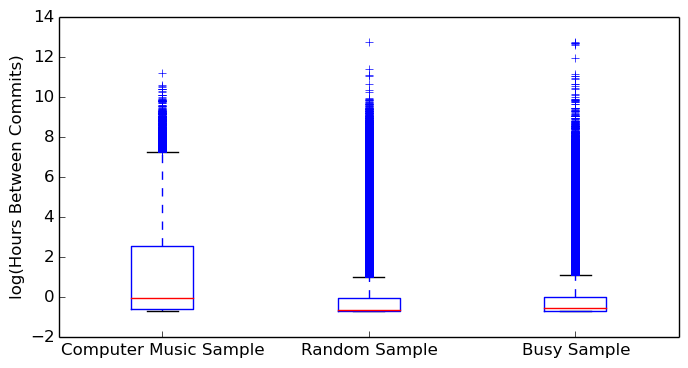
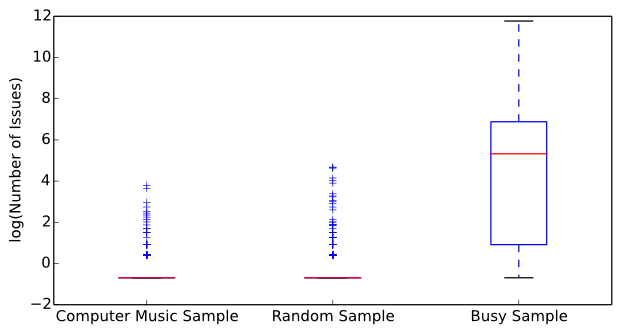
Figure 5 displays a side-by-side box plot of issue counts for the computer music dataset, the random sample dataset, and the busy sample dataset. To properly display the results, the issue counts were transformed into the logarithmic domain. The Wilcoxon rank sum test reports a z-value of -0.792 and a p-value of 0.214. At alpha=0.01 there is insignificant evidence to reject the null hypothesis and we conclude that computer musicians create the same amount of issues as the general population of software developers, which refutes our hypothesis and the intuitions of many computer musicians. A closer look at the data shows that the median number of issues for both the computer music and random sample datasets is zero, meaning that the general population of developers also create few issues when contributing to software repositories on GitHub. However, the random sample of repositories had significantly less issues than the busy sample of repositories (z-value of -27.1827, p-value of practically zero).
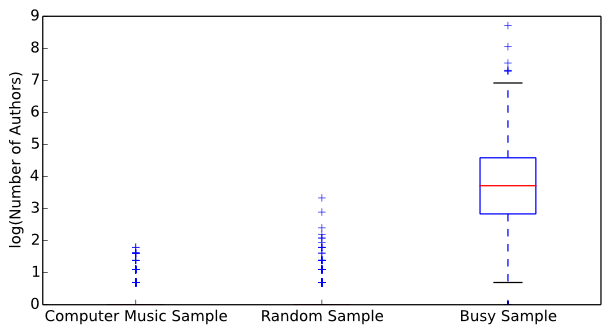
The number of distinct commit authors is calculated for each software
repository. Figure 6 displays a side-by-side box
plot of unique author counts for the computer music dataset,
the dataset of random samples of Git repositories, and the busy sample of Git repositories.
To properly display the results, the number of unique authors were
transformed into the logarithmic domain.
The Wilcoxon rank sum test reports a z-value of -0.082 and a p-value of 0.4673.
At alpha=0.01 there is insignificant evidence to reject the null
hypothesis and we conclude that both computer musicians' and
general software developers' repositories have similar numbers of
distinct authors, which refutes our hypothesis as well as several
computer musicians' intuitions. Upon closer inspection, the median number of distinct
contributing authors for the computer music and general population samples is one, meaning
the general population of developers contributing to software repositories on GitHub tend to work alone.
However, the random sample of repositories had significantly less unique authors than the busy sample
of repositories (z-value of -33.2139 and p-value of practically 0).
Clone Detection in Max/MSP and Pure Data Patches
The developed Max/MSP and Pure Data clone detection algorithm operates with two levels of granularity, locating DF1 and DF2 type clones in patch subgraphs. Recall that a patch is a directed graph consisting of objects (vertices) and patchcords (edges). The clone taxonomy is as follows:
- DF2 clone: two subgraphs containing the same object types that are connected by patchcords to the same inlets and outlets.
- DF1 clone: two subgraphs that are a DF2 clone and, further, the corresponding objects in each subgraph possess the same literal values as default parameters.
Note that this clone taxonomy differs from Gold et al. [13] in that the absolute and relative positions of objects are not considered. In this research study we are interested in which objects computer musicians interface with other objects and are not concerned with situations where object position affects precedence.
A. Clone Detection Algorithm
In order to perform clone detection on both Max/MSP and Pure Data patches, each file must first be parsed and translated into a common data format. A Pure Data parser was developed in Python, which translates the text encoding of patches to the internal data structure used by the Python graph library NetworkX. Similarly, a JSON parser was used to convert encoded Max/MSP patches to the NetworkX data structure. Nested patches are not parsed recursively. Using the resulting patch graphs as input, the proposed clone detection algorithm begins by setting the granularity of detected clones to either DF1 or DF2 clones. For each vertex in each directed graph representing a Max/MSP or Pure Data patch, the graph is traversed in a depth-first fashion. With each traversal, the attributes of objects (type, parameters, number of inlets, number of outlets) and patchcords (source object, outlet number, sink object, inlet number) along the path from the root vertex to the current vertex is compiled. The depth of paths considered by the clone detection algorithm is limited to eight. Depending on the granularity of clone detection, the gathered object and patchcord attributes are filtered accordingly. For example, when searching for DF1 clones all of the patchcord attributes are necessary but the parameters attribute of all objects should be discarded. The list of objects, patchcords, and their attributes are stored in a JSON data structure that is converted to text prior to hashing. This textual representation of the patch subgraph is transformed using the MD5 hash. If the hash is not unique, the subgraph is a clone.
B. Clone Detection Results
First, the proposed clone detection algorithm was run on the dataset of 68 preprocessed Max/MSP tutorial patches and received similar results as the algorithm proposed by Gold et al. [13]: 2,104 DF1 clones and 5,837 DF2 clones were detected in comparison to the 1,501 DF1 clones and 5,696 DF2 clones reported by Gold et al. Note that the slight increase in clone counts reported by our algorithm is likely due to the relaxed criteria for clone detection that disregards object position information.
On the compiled dataset of 819 computer music repositories, the number of DF1 and DF2 clones detected by the proposed algorithm is presented in Table 2. Approximately 9.8 million DF1 clones and 10.5 million DF2 clones were detected out of the roughly 11 million paths traversed by the algorithm. From this analysis we note that 89.2% of connected object subgraphs in Max/MSP and Pure Data patches programmed by computer musicians are DF1 clones and 95.2% of connected object subgraphs are DF2 clones. These clone proportions are significantly higher than the clone proportions our algorithm reported on the dataset of preprocessed Max tutorial patches used by Gold et al. [13]: 31.8% and 88.2% for DF1 and DF2 clones, respectively. This result is expected given the intentional variety of concepts and object connections explored in the tutorial patches, whereas patches created by computer musicians do not necessarily utilize all facets of these visual programming languages.
| Type | Clone Counts | Paths | Clone Proportion |
|---|---|---|---|
| DF1 | 9,798,031 | 10,985,064 | 89.2% |
| DF2 | 10,462,725 | 10,985,064 | 95.2% |
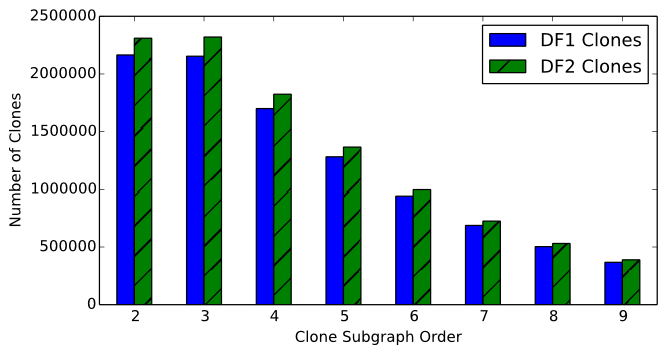
In more detail, the distribution of clone counts over the order of path subgraphs is presented in Figure 8. The order of a graph G = {V,E} is |V|, the cardinality of the set of vertices in the graph. For example, Figure 8 displays that approximately 50,000 of the DF1 clones detected in Max/MSP and Pure Data patches created by computer musicians are composed of eight connected objects. The resulting distribution of clone counts reveals that as the order of subgraphs increase, the number of clones decrease. Moreover, as the criteria for clone detection becomes more relaxed---for example, as we move from DF1 to DF2 clone detection---the number of clones increase.
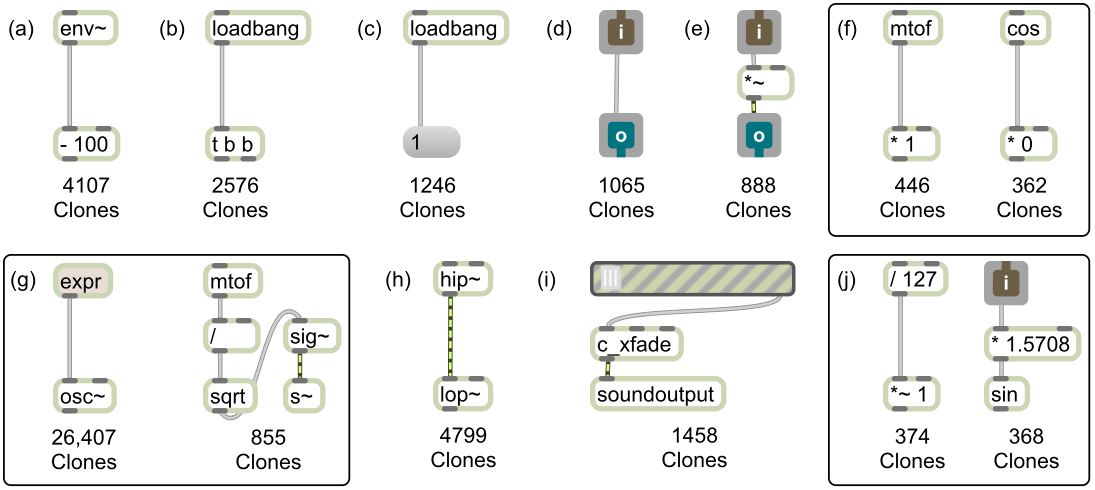
Moreover, Table 3 presents the top 10 DF1 and DF2 clones discovered in the dataset of Max/MSP and Pure Data patches.
| DF1 Clones | DF2 Clones | |
|---|---|---|
| 1. | (env~, - 100) : 4107 clones | (route, route) : 105,655 clones |
| 2. | (*~, outlet~) : 4029 clones | (inlet, *) : 77,069 clones |
| 3. | (inlet, list trim) : 3910 clones | (list, s) : 40,403 clones |
| 4. | (inlet, t b a) : 3684 clones | (inlet~, *~) : 32,865 clones |
| 5. | (sig~, *~) : 3384 clones | (inlet, route) : 32,159 clones |
| 6. | (p, p) : 2972 clones | (+, clip) : 31,524 clones |
| 7. | (line~, *~) : 2927 clones | (+, del) : 30,328 clones |
| 8. | (inlet, t b a, p, outlet) : 2900 clones | (list, list) : 26,818 clones |
| 9. | (t b a, f) : 2900 clones | (+, +) : 26,462 clones |
| 10. | (inlet, t b a, p) : 2900 clones | (expr, osc~) : 26,407 clones |
Among the millions of DF1 and DF2 clones detected within the Max/MSP and Pure Data patches gathered from GitHub, several interesting clone structures stand out that emphasize common practices of computer musicians and highlight idiosyncrasies of these visual programming languages. The clone depicted in Figure 9 (a) is a Pure Data envelope follower object, which outputs the amplitude in decibels of an input audio signal. However, an output of 1 is normalized to 100 decibels, and so many computer musicians subtract 100 to reverse the normalization. Figure 9 (b) displays a frequently occurring clone involving the loadbang object, which fires a bang when the patch loads. The bang message acts as a trigger for connected objects to start processing. This clone triggers two bangs instead of one when the patch starts, which suggests that the loadbang object should have a parameter indicating the number of bang messages to output. The following Pure Data clone shown in Figure 9 (c) outputs the number 1 when the patch loads. In Max/MSP, an object called loadmess exists to accomplish this task; however it is not implemented in Pure Data. The clone depicted in Figure 9 (d) is the identity function that simply outputs its input. A possible explanation for the frequency of this clone is that computer musicians create an identity function with the intent to add functionality later but forgot. The clone shown in Figure 9 (e) provides commentary on the point in which some computer musicians choose to abstract code fragments into functions. In this case, the clone is an overly simplistic function that attenuates the amplitude of the input signal. The clones in Figure 9 (f) demonstrate that computer musicians often choose default parameters that have no effect on the output—for example, multiplying a value by one—or choose default parameters that zero a value or silence an audio signal until an event occurs that changes the default parameters. The clones in Figure 9 (g) display two methods that computer musicians use to perform calculations: either as a one-line expression using the expr object, or as a daisy chain of mathematical operations. The clone displayed in Figure 9 (h) is a high-pass filter—responsible for filtering high frequencies in audio signals—that is immediately followed by a low-pass filter, which filters low frequencies in audio signals. This configuration of objects is essentially a band-pass filter, which exists as a stand-alone object in both Max/MSP and Pure Data, but is evidently not used in certain situations. The clone shown in Figure 9 (i) demonstrates that computer musicians often use external objects, such as the c_xfade crossfade object in the rjdj library, to simplify common musical functions like fading out one audio signal while fading in another. Finally, the clones in Figure 9 (j) demonstrate that computer musicians often use magic numbers such as 127—the highest value encoded in the musical instrument digital interface (MIDI) protocol—or even divisions of the mathematical constant pi.
Patch Evolution Analysis
In an effort to qualitatively analyze how Max/MSP and Pure Data patches evolve throughout the development process, a patch history visualization web application has been developed. The web application allows the user to input a Git HTTPS clone URL that is used to clone the Git repository on the server. The user may then select a music patch within the repository to visualize its history by incrementally stepping forward or backward through the commit history timeline. Object and patchcord insertions, deletions, movements, and rescalings are rendered in the browser using scalable vector graphics (SVG) and animated using the d3.js JavaScript library. A demo of the web application exists, or the web application can be used to visualize the evolution of any music patch on GitHub: try it out.
The web application was used to visualize the evolution of a sample of Max/MSP and Pure Data patches within Git repositories in the compiled computer music dataset. From this qualitative analysis, we determined that software development in visual music programming languages is not necessarily a tuning process, whereby the core musical infrastructure is created and then parameters are tuned in subsequent commits. Computer musicians, as composers, seem to exhibit different development strategies as a means to their personal and creative musical goals. Indeed, this finding is supported by our interviews with 15 computer musicians. When asked if key musical components are constructed and then tuned until realizing the desired sound, computer musicians had the following responses:
- "To a certain extent, but it depends on what the goal of the patch is really."
- "I usually start from simple things and gradually elaborate until I hear something that is (potentially) interesting. So the development process and the tuning of parameters go hand in hand."
- "After tuning parameters, I can become aware of weaknesses in the combination of key components and work backwards to include more or to reconnect them in more fruitful ways."
The consensus among interviewed computer musicians was that the evolution of programmed musical compositions is largely project dependent and often iterative in nature.
Computer Musician Surveys and Interviews
A survey of 175 computer musicians and interviews with 15 computer musicians was conducted to gather more information about this end-user community. Computer musicians were recruited using relevant forums on Reddit, the Max/MSP and Pure Data forum boards, and several mailing lists. A live version of the survey can be visited to view how the 16 survey questions were presented to the computer musicians who participated.
A. Survey Responses
- How many years have you been programming musical applications?
- How would you rank your programming skill?
- Which music-oriented languages do you program in?
- Do you program musical applications for pleasure, or is it your main source of income?
- Do you write music software for other individuals or companies?
- If you program outside of the musical realm, which languages do you tend to use?
- Do you use source control repositories?
- "I'm still trying to figure out how best to work with it."
- "It hasn't really seemed necessary ... lack of backup for previous versions hasn't really caused me any significant problems."
- "No one else really uses my code, so versioning isn't a priority for me."
- If you use source control repositories, which ones do you use?
- Do you create tests (e.g., unit tests, regression tests) for music code you write?
- To what level do you comment your musical code?
- Which external music libraries do you use on a regular basis?
- Do you use www.stackoverflow.com for music application development?
- Which mailing lists do you subscribe to in order to ask the computer music community questions you may have?
- Do you use MIDI (Musical Instrument Digital Interface)?
- Do you use OSC (Open Sound Control)?
- How many musical instruments do you play?
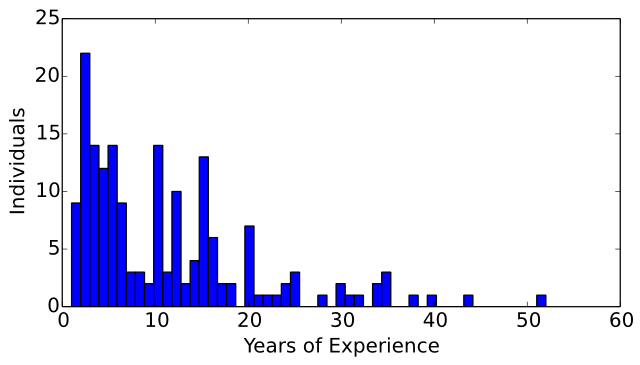
A histogram of the number of years of experience of the surveyed computer musicians is displayed in Figure 10. The median number of years of experience is 9. The mean number of years of experience is 10.942. The minimum number of years of experience is 0–1, and the maximum number of years of experience is 52. These responses indicate that the experience level of the community of computer musicians varies greatly.
The possible responses to this question were limited to: beginner, intermediate, advanced, or no response. Of the surveyed computer musicians, 15 considered themselves beginner programmers, 84 considered themselves intermediate programmers, 74 considered themselves advanced programmers, and 2 chose not to respond to this question (see Figure 11). These responses indicate that the computer music community predominantly consists of intermediate and advanced programmers.
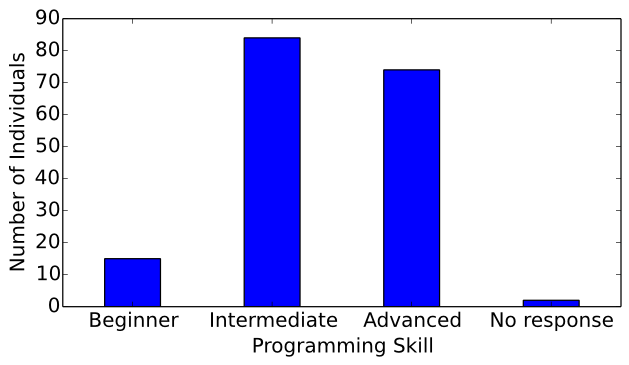
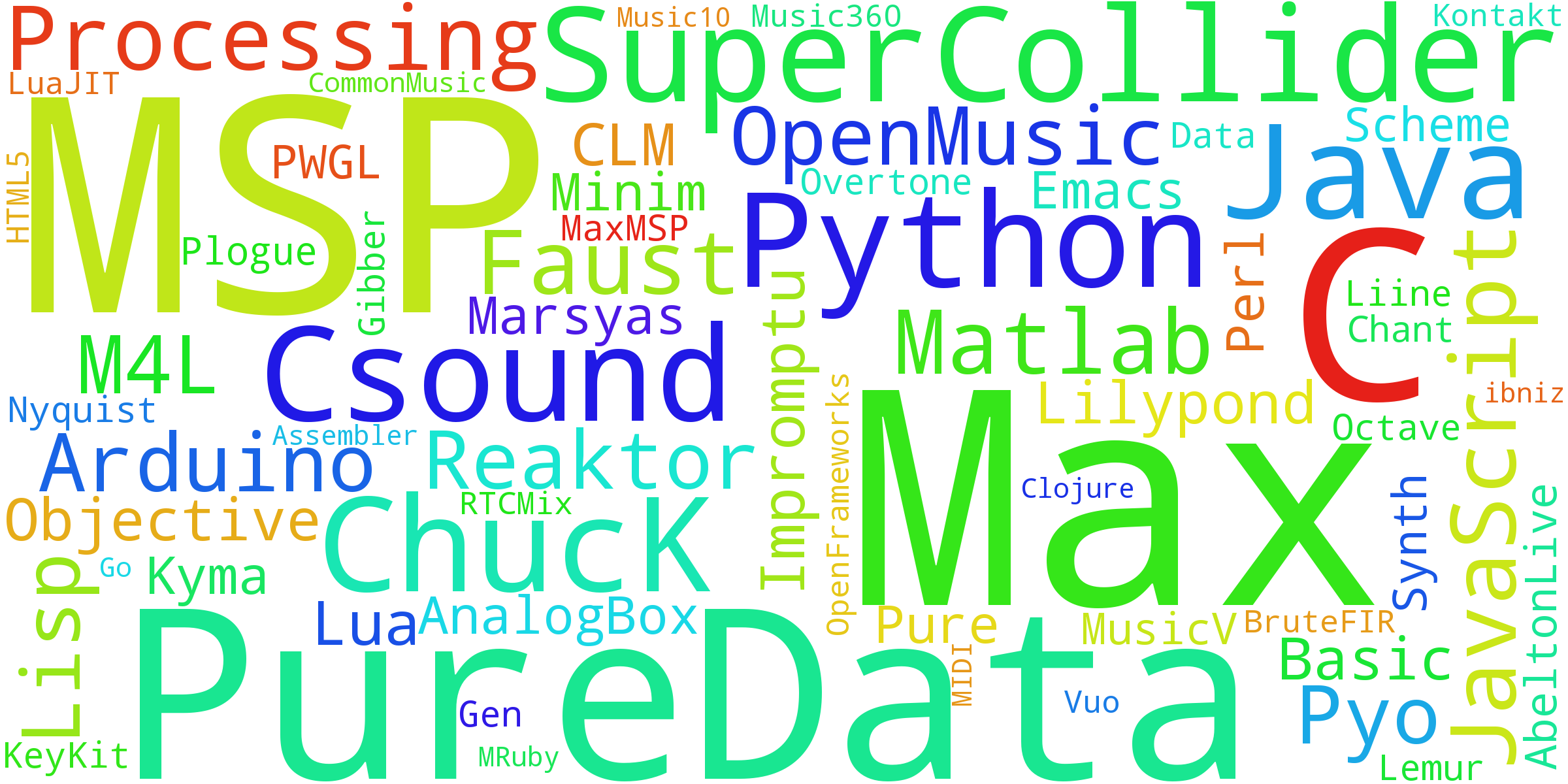
Figure 12 presents a word cloud of the programming languages used by computer musicians who responded to the survey. Larger names of languages indicate a higher frequency of use. According to the responses, Max/MSP (99) and Pure Data (82) are the top two programming languages used by computer musicians, followed by SuperCollider (46), Csound (36), C++ (24), C (23), Python (20), ChucK (15), Java (8), JavaScript (8), and other lesser used languages. It is worthy to note that some of the languages computer musicians report to use are general-purpose programming languages that are not specifically oriented towards audio applications.
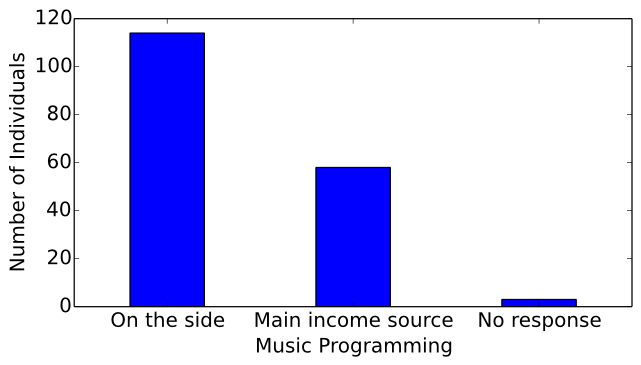
Of the surveyed computer musicians, 114 program musical applications as a hobby, 58 program musical applications as a main source of income, and 3 chose not to respond to the question (see Figure 13). If the majority of computer musicians program in their free time, one would expect their commits to occur more on weekends and be less frequent than the general population of software developers. Indeed, the results procured by the significance tests performed in the Mining Software Repositories Section support these survey responses.
Of the surveyed computer musicians, 70 write music software for other individuals or companies, 104 do not, and 1 individual chose not to respond to this question (see Figure 14). This response was resonated in the interviews with 15 computer musicians, where the majority of interviewees advocated that music projects tend to be highly personal and follow the creative vision of one musician.
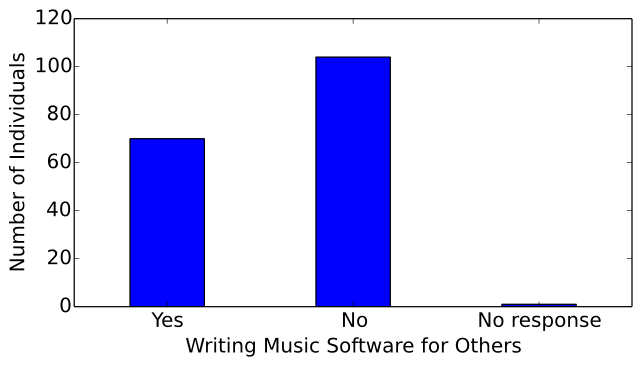
Figure 15 presents a word cloud of the programming languages used by computer musicians who responded to the survey when they are programming outside of the musical realm. Larger names of languages indicate a higher frequency of use. According to the responses, Python (47) and C++ (47) are the top two programming languages used by computer musicians when not programming music-related applications, followed by C (45), JavaScript (37), Java (35), Processing (14), Objective-C (14), PHP (14), HTML (10), C# (10), and other lesser used languages.

Of the surveyed computer musicians, 94 use source control repositories, 77 do not, and 4 chose not to respond to this question (see Figure 16). Interestingly, roughly half of computer musicians in the population sample use source control repositories either for version control or as a means for sharing code with the community. With roughly half of computer musicians not using source control repositories, we turn to interview responses for possible explanations for this phenomenon:
These responses indicate that source control systems may be avoided by the computer music community due to a lack of technical understanding of the tool, a lack of understanding of the merits of the tool, or because collaboration is unnecessary in their musical endeavours.
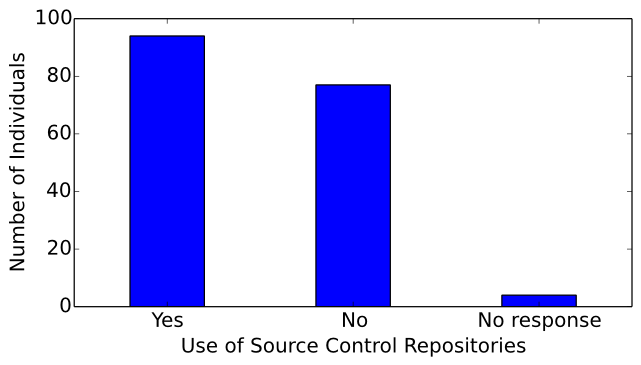
Figure 17 presents a word cloud of the source control systems used by computer musicians who responded to the survey. Larger names of source control systems indicate a higher frequency of use. According to the responses, Git (83) and SVN (25) are the top two source control systems used by computer musicians, followed by SourceForge (8), CVS (6), GitHub (6), Bitbucket (6), Mercurial (3), Clearcase (2), and other lesser used languages. Note that several of the responses provided by computer musicians, such as "GitHub" or "Bitbucket" are not source control systems, but rather online hosts for such repositories.

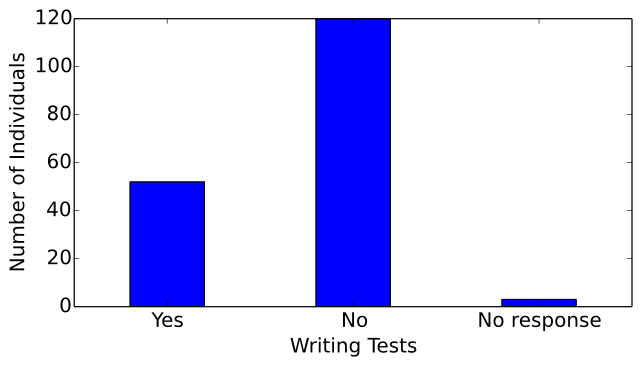
Of the surveyed computer musicians, 52 write tests for music programs they develop, 120 do not, and 3 chose not to respond to this question. (see Figure 18) A possible explanation for the large proportion of computer musicians who do not write tests is that it may be difficult to translate desired qualities of a sound to a quantifiable property that can be asserted as correct or incorrect in the context of a test.
Of the surveyed computer musicians, 34 barely comment their code, 94 provide comments on key functions,
44 extensively comment their code, and 3 chose not to respond to this question (see Figure 19).
Within the dataset of 819 repositories containing Max/MSP and Pure Data patches, there exists 505,236 comment
objects out of the 3,087,278 objects in the dataset (see Table 1), which provides empirical
evidence that computer musicians do comment their musical code.
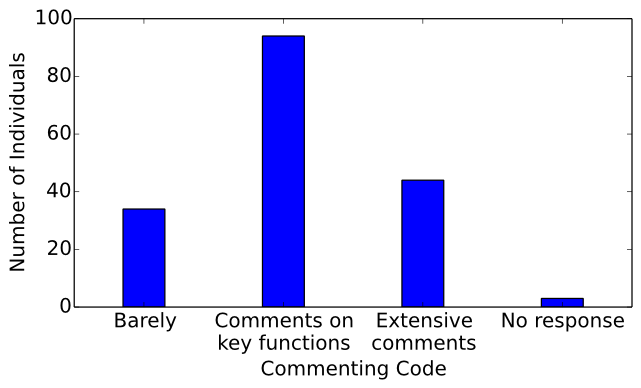
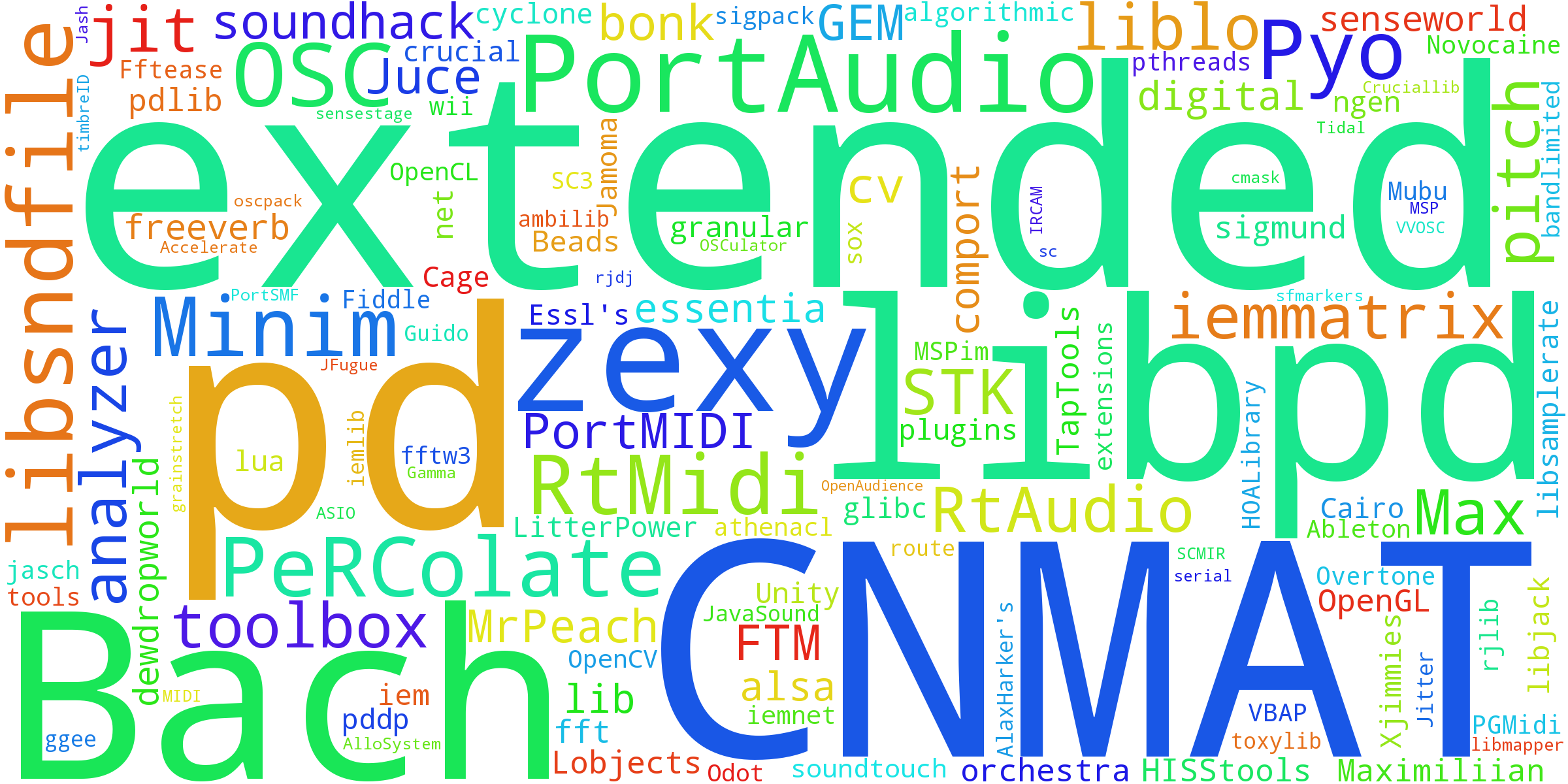
Figure 20 presents a word cloud of the external music libraries used by computer musicians who responded to the survey on a regular basis. Larger names of music libraries indicate a higher frequency of use. According to the responses, pd-extended (14) and CNMAT (9) are the top two music libraries used by computer musicians, followed by PortAudio (5), Bach (5), zexy (5), libpd (4), PeRColate (3), libsndfile (3), Minim (3), Pyo (3), STK (3), and other lesser used libraries. The number of music libraries used by computer musicians on a regular basis is certainly vast and diverse.
Of the surveyed computer musicians, 46 use www.stackoverflow.com for application development, 126 do not use the website, and 3 chose not to respond to this question (see Figure 21). If the majority of computer musicians do not use www.stackoverflow.com, which knowledge sources do they consult for aid? Interviews with 15 computer musicians revealed that computer musicians often consult their community through mailing lists. Indeed, 54% of the surveyed computer musicians subscribe to mailing lists. These results indicate that the community of computer musicians could benefit from more knowledge sources for support, such as a question and answer website dedicated to computer musicians.
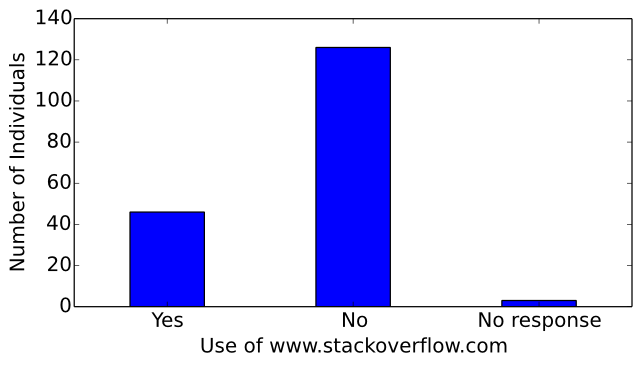
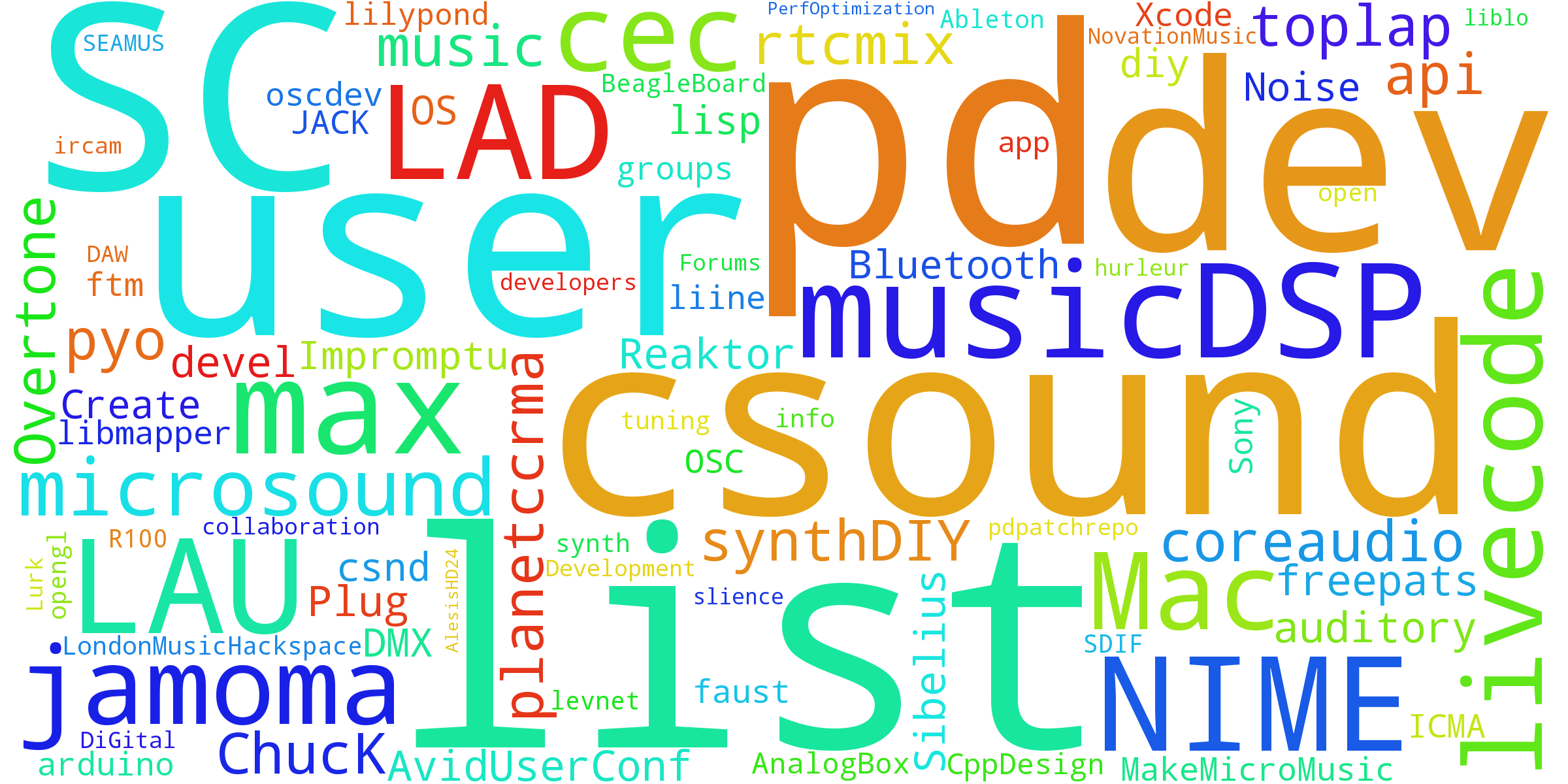
Figure 22 presents a word cloud of the mailing lists that computer musicians subscribe to. Larger names of mailing lists indicate a higher frequency of use. According to these responses, pd-list (30) and csound-list (16) are the top two mailing lists subscribed to by computer musicians, followed by SC-users (16), musicDSP (10), max-list (7), csound-dev (7), linux audio users (7), linux audio developers (6), and others.
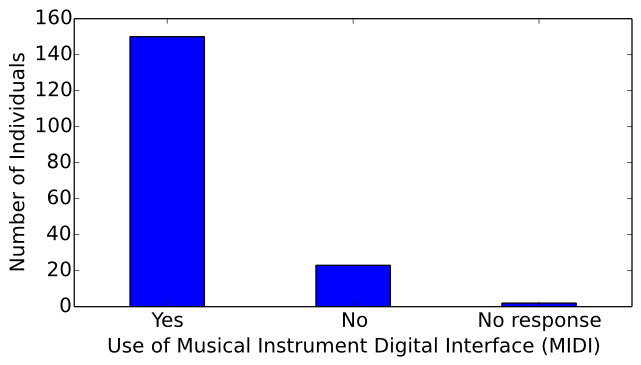
Of the surveyed computer musicians, 150 use MIDI, 23 do not use MIDI, and 2 chose not to respond to this question
(see Figure 23).
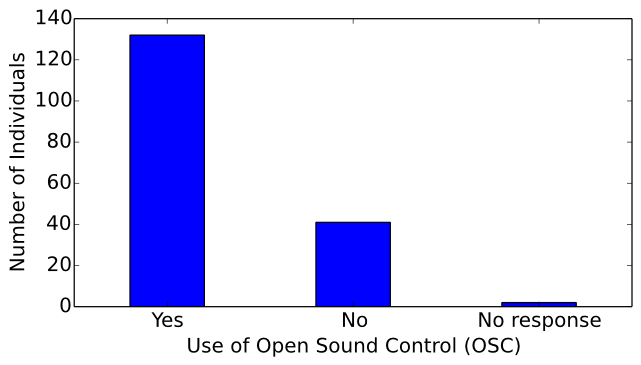
Of the surveyed computer musicians, 132 use OSC, 41 do not use OSC, and 2 chose not to respond to this question.
(see Figure 24).
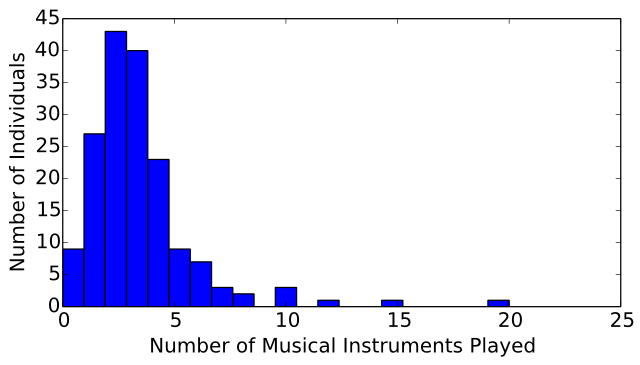
The distribution of the number of instruments played by the surveyed computer musicians is displayed in Figure 25. The median number of instruments played is 3. The mean number of instruments played is 3.112. The minimum number of instruments played is 0, and the maximum number of instruments played is 20.
B. Interview Conclusions
After engaging in interviews with 15 computer musicians of various skill levels, several recurring themes emerged from the conversations: the community’s culture of sharing intellectual property is perhaps different than the culture of software developers who endorse opensource code; computer musicians often work alone on compositions because the creative direction of a piece is usually the vision of a single musician; some qualities of audio can not be quantified in such a way that they can be explicitly tested or written about in concrete terms; and finally, computer music tends to be a hobby for most musicians, possibly due to the uncommercial nature of the music.
Conclusion
A multifaceted study of computer music programmers has been conducted to gain insight into how this community of end users develop music patches written in the Max/MSP and Pure Data visual programming languages. The first facet of analysis was a comparison of the software development practices of computer musicians and the general population of software developers. Using a dataset of Git repositories hosted on GitHub, a series of statistical tests established that in comparison to the general population of software developers, computer musicians' repositories have less commits, less frequent commits, more commits on the weekend, yet similar numbers of bug reports, contributing authors, and forks. The second facet of analysis was an investigation of cloned code and repeated object structures in visual music programming languages. When run on 118,481 Max/MSP and Pure Data patches, the algorithm detected that 89% of connected objects are DF1 clones (object types, parameters, and connections are equivalent) and 95% of connected objects are DF2 clones (object types and connections are equivalent). Many clones discovered in source code programmed by computer musicians were re-implementations of already existing objects in Max/MSP and Pure Data. The third facet of analysis was a web application designed to visualize how music patches change over the commit history of a project. Using this tool, a qualitative evolutionary analysis found that computer musicians do not necessarily develop core musical infrastructure and then proceed to tune the parameters of these key components; instead the development process is iterative in nature and largely dependent on the musical composition. The final facet of analysis investigates, via surveys and interviews, how computer musicians build their software and which software engineering tools they use. The surveys reinforced that computer musicians do not necessarily use source control repositories or bug trackers. Furthermore, computer musicians lack a dedicated support website for posing questions and answers to the entire computer music community and instead subscribe to mailing lists for support. Now that an empirical study of computer music programmers has been conducted, more work can be done to educate and develop software engineering tools for this end-user community.